KNN(K近邻算法)基本介绍

辰菇凉
行为 ->性格 ->命运
KNN学习了很久,但是都没有形成体系,遗忘曲线过于陡峭,开始运用新方法,输出倒逼完整=输入,这篇文章的目标有三个:
- 了解KNN算法的思想和原理
- Python手动实现KNN算法,并从sklearn中调用KNN算法
- 了解监督学习和非监督学习的概念
一、KNN算法介绍和应用场景
KNN(k-NearestNeighbor),就是k最近邻算法,这是一种常用的监督学习方法,简单来说,根据k个最近的邻居的状态来决定样本的状态,即‘物以类聚,人以群分’。
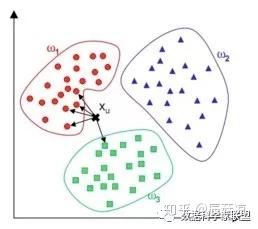
KMeans的基本原理是:首先,随机选择K个对象,而且所选择的每个对象都代表一个组的初始均值或初始的组中心值,对剩余的每个对象,根据其与各个组初始均值的距离,将他们分配各最近的(最相似)小组,然后重新计算每个小组新的均值,这个过程不断重复,直到所有的对象在K组分布中都找到离自己最近的组。
以上模型三要素: 距离度量(一般用欧氏距离),k值,分类决策规则
使用场景:
通常在分类任务重,可使用‘投票法’,即选择k个样本中出现最多的类别标记作为预测结果,在回归任务中,可使用‘平均法’,即将这k个样本的实值输出标记的平均值作为预测结果,还可基于距离远近进行加权平均或加权投票,距离越近的样本权重越大。
二、 KNN简单实现
- 准备数据
- 求欧式距离 & 距离排序求取结果索引
- 选择k值
- 决策规则
import numpy as np
import matplotlib.pyplot as plt
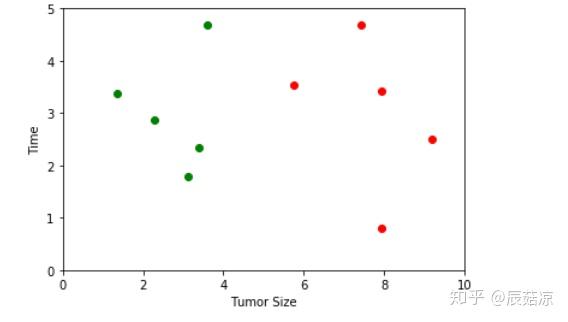
# raw_data_x是特征,raw_data_y是标签,0为良性,1为恶性
raw_data_X = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343853454, 3.368312451],
[3.582294121, 4.679917921],
[2.280362211, 2.866990212],
[7.423436752, 4.685324231],
[5.745231231, 3.532131321],
[9.172112222, 2.511113104],
[7.927841231, 3.421455345],
[7.939831414, 0.791631213]
]
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
# 设置训练组
X_train = np.array(raw_data_X)
y_train = np.array(raw_data_y)
#数据可视化
plt.scatter(X_train[y_train==0,0], X_train[y_train==0,1], color='g', label = 'Tumor Size')
plt.scatter(X_train[y_train==1,0], X_train[y_train==1,1], color='r', label = 'Time')
plt.xlabel('Tumor Size')
plt.ylabel('Time')
plt.axis([0,10,0,5])
plt.show()


# 求距离
from math import sqrt
x = [8.90933607318, 3.365731514]
distances =[] #用来记录x到样本数据集中每个点的距离
for x_train in X_train:
d = sqrt(np.sum((x_train - x) **2))
distances.append(d)
# 使用列表生成器
#distances = [sqrt(np.sum((x_train - x) ** 2)) for x_train in X_train]
distances
输出:
[5.611968000921151,
6.011747706769277,
7.565483059418645,
5.486753308891268,
6.647709180746875,
1.9872648870854204,
3.168477291709152,
0.8941051007010301,
0.9830754144862234,
2.7506238644678445]求出距离后,需要进行一次排序操作,简单排序没有作用,需要知道的是
距离最小的k个点在样本集中的位置
运用np.argsort(array)对数组进行排序
nearest = np.argsort(distances)
nearest
输出:
array([7, 8, 5, 9, 6, 3, 0, 1, 4, 2])
# 结果的含义是距离最小的点在distance数组中的索引是7, 第二小的点是8接下来,进入投票环节,对于不同类别的点进行计数
# 选择k值,如果暂定8, 就找出最近的8个点,并记录他们的标签值y
k = 8
topK_y = [y_train[i] for i in nearest[:k]]
topK_y
输出:
[1, 1, 1, 1, 1, 0]
# 对不同类别的点进行计数,将数组中的元素和元素出现的频次进行统计
from collections import Counter
votes = Counter(topK_y)
votes
输出:一个字典,原数组中值为0的个数为1,值为1的个数为5
Counter({0:1, 1:5})Counter.most_common(n)找出票数最多的n个元素:
找出票数最多的n个元素,返回的是一个列表,列表中的每个元素是一个元组,元组中第一个元素是对应的元素是谁,第二个元素是频次
votes.most_common(1)
输出:
[(1,5)]
predict_y = votes.most_common(1)[0][0]
predict_y
输出:
1三、KNN自实现完整工程代码
import numpy as np
from math import sqrt
from collections import Counter
class kNNClassifier:
def __init__(self, k):
"""初始化分类器"""
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None
self._y_train = None
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k"
self._X_train = X_train
self._y_train = y_train
return self
def predict(self,X_predict):
"""给定待预测数据集X_predict,返回表示X_predict结果的向量"""
assert self._X_train is not None and self._y_train is not None, \
"must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1], \
"the feature number of X_predict must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
distances = [sqrt(np.sum((x_train - x) ** 2)) for x_train in self._X_train]
nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
def __repr__(self):
return "kNN(k=%d)" % self.k四、sklearn 中的kNN
机器学习流程:
- 训练数据集
- 机器学习算法-fit
- 模型输入样例
- 模型 - predict
- 输出结果
from sklearn.neighbors import KNeighborsClassifier
# 创建kNN_classifier实例
kNN_classifier = KNeighborsClassifier(n_neighbors=6)
# kNN_classifier做一遍fit(拟合)的过程,没有返回值,模型就存储在kNN_classifier实例中
kNN_classifier.fit(X_train, y_train)
# kNN进行预测predict,需要传入一个矩阵,而不能是一个数组。reshape()成一个二维数组,第一个参数是1表示只有一个数据,第二个参数-1,numpy自动决定第二维度有多少
y_predict = kNN_classifier.predict(np.array(x).reshape(1,-1))
y_predict
输出:
array([1])

#输出结果
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=6, p=2,
weights='uniform')参数详解:
n_neighbors: int, 可选参数(默认为 5)。用于kneighbors查询的默认邻居的数量weights(权重): str or callable(自定义类型), 可选参数(默认为 ‘uniform’)。用于预测的权重参数,可选参数如下:uniform: 统一的权重. 在每一个邻居区域里的点的权重都是一样的。distance: 权重点等于他们距离的倒数。使用此函数,更近的邻居对于所预测的点的影响更大。[callable]: 一个用户自定义的方法,此方法接收一个距离的数组,然后返回一个相同形状并且包含权重的数组。algorithm(算法): {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, 可选参数(默认为 'auto')。计算最近邻居用的算法:ball_tree使用算法BallTreekd_tree使用算法KDTreebrute使用暴力搜索auto会基于传入fit方法的内容,选择最合适的算法。注意 : 如果传入fit方法的输入是稀疏的,将会重载参数设置,直接使用暴力搜索。leaf_size(叶子数量): int, 可选参数(默认为 30)。传入BallTree或者KDTree算法的叶子数量。此参数会影响构建、查询BallTree或者KDTree的速度,以及存储BallTree或者KDTree所需要的内存大小。此可选参数根据是否是问题所需选择性使用。p: integer, 可选参数(默认为 2)。用于Minkowski metric(闵可夫斯基空间)的超参数。p = 1, 相当于使用曼哈顿距离,p = 2, 相当于使用欧几里得距离],对于任何 p ,使用的是闵可夫斯基空间。metric(矩阵): string or callable, 默认为 ‘minkowski’。用于树的距离矩阵。默认为闵可夫斯基空间,如果和p=2一块使用相当于使用标准欧几里得矩阵. 所有可用的矩阵列表请查询 DistanceMetric 的文档。metric_params(矩阵参数): dict, 可选参数(默认为 None)。给矩阵方法使用的其他的关键词参数。n_jobs: int, 可选参数(默认为 1)。用于搜索邻居的,可并行运行的任务数量。如果为-1, 任务数量设置为CPU核的数量。不会影响fit
KNeighborsClassifier的方法: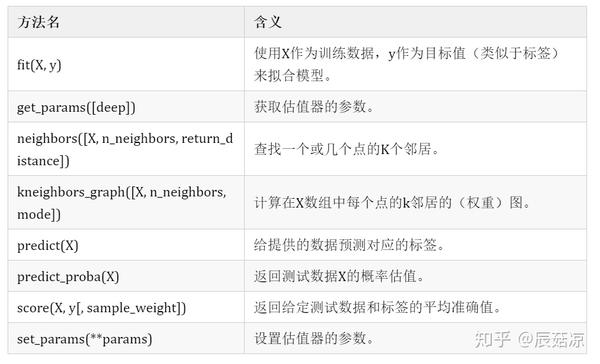

发布于 2020-03-01 13:00
