react-hooks原理解析

React-hooks源码解析
一、react添加hook的动机
Hook 是 React 16.8 的新增特性。它可以让你在不编写 class 的情况下使用 state 以及其他的 React 特性。我们来讨论下添加hook的动机。
1、在组件之间复用状态逻辑很难
React 没有提供将可复用性行为“附加”到组件的途径(例如,把组件连接到 store)。使得复用状态逻辑很难,举个栗子
我们假设有个ChatAPI可以订阅好友的在线状态,现在想要实现好友在线时,展示onLine字符,好友不在线时展示offLine字符。其中ChatAPI是现有模块,可以直接使用,实现如下:
import React, { useState, useEffect } from 'react';
function FriendStatus(props) {
const [isOnline, setIsOnline] = useState(null);
useEffect(() => {
function handleStatusChange(status) {
setIsOnline(status.isOnline);
}
ChatAPI.subscribeToFriendStatus(props.friend.id, handleStatusChange);
return () => {
ChatAPI.unsubscribeFromFriendStatus(props.friend.id, handleStatusChange);
};
});
if (isOnline === null) {
return 'Loading...';
}
return isOnline ? 'Online' : 'Offline';
}
现在我们假设聊天应用中有一个联系人列表,当用户在线时需要把名字设置为绿色。我们可以把上面类似的逻辑复制并粘贴到 FriendListItem 组件中来,但这并不是理想的解决方案
import React, { useState, useEffect } from 'react';
function FriendStatus(props) {
const [isOnline, setIsOnline] = useState(null);
useEffect(() => {
function handleStatusChange(status) {
setIsOnline(status.isOnline);
}
ChatAPI.subscribeToFriendStatus(props.friend.id, handleStatusChange);
return () => {
ChatAPI.unsubscribeFromFriendStatus(props.friend.id, handleStatusChange);
};
});
return (
<div style={ {color: isOnline?'green':'black'} }>
{props.friend.name}
</div>
);
}
以上在使用isOnline的逻辑是完全一样的,毫无疑问,我们想要复用这一块逻辑,如果你使用过 React 一段时间,你也许会熟悉一些解决此类问题的方案,比如 render props 和 高阶组件。但是
1)、这类方案需要重新组织你的组件结构,这可能会很麻烦,使你的代码难以理解。
2)、如果你在 React DevTools 中观察过 React 应用,你会发现由 providers,consumers,高阶组件,render props 等其他抽象层组成的组件会形成“嵌套地狱”。
尽管我们可以在 DevTools 过滤掉它们,但这说明了一个更深层次的问题:React 需要为共享状态逻辑提供更好的原生途径。
你可以使用 Hook 从组件中提取状态逻辑,使得这些逻辑可以单独测试并复用。Hook 使你在无需修改组件结构的情况下复用状态逻辑。这使得在组件间或社区内共享 Hook 变得更便捷。我们可以用自定义hook的方式来 复用状态逻辑,自定义 Hook 是一个函数,其名称以 “use” 开头,函数内部可以调用其他的 Hook。 使用此技术复用状态逻辑如下:
import { useState, useEffect } from 'react';
function useFriendStatus(friendID) {
const [isOnline, setIsOnline] = useState(null);
useEffect(() => {
function handleStatusChange(status) {
setIsOnline(status.isOnline);
}
ChatAPI.subscribeToFriendStatus(friendID, handleStatusChange);
return () => {
ChatAPI.unsubscribeFromFriendStatus(friendID, handleStatusChange);
};
});
return isOnline;
}
使用自定义hook的方法如下:
function FriendStatus(props) {
const isOnline = useFriendStatus(props.friend.id);
if (isOnline === null) {
return 'Loading...';
}
return isOnline ? 'Online' : 'Offline';
}
function FriendListItem(props) {
const isOnline = useFriendStatus(props.friend.id);
return (
<li style={ { color: isOnline ? 'green' : 'black' } }>
{props.friend.name}
</li>
);
}
以上我们用不同方式实现了 状态逻辑的复用,较render props和高阶组件,自定义hook简单、容易理解、学习成本低、易于维护、没有嵌套地狱等。
2、复杂组件变得难以理解
我们经常维护一些组件,组件起初很简单,但是逐渐会被状态逻辑和副作用充斥。每个生命周期常常包含一些不相关的逻辑。例如,组件常常在 componentDidMount 和 componentDidUpdate 中获取数据。但是,同一个 componentDidMount 中可能也包含很多其它的逻辑,如设置事件监听,而之后需在 componentWillUnmount 中清除。相互关联且需要对照修改的代码被进行了拆分,而完全不相关的代码却在同一个方法中组合在一起。如此很容易产生 bug,并且导致逻辑不一致。
在多数情况下,不可能将组件拆分为更小的粒度,因为状态逻辑无处不在。这也给测试带来了一定挑战。同时,这也是很多人将 React 与状态管理库结合使用的原因之一。但是,这往往会引入了很多抽象概念,需要你在不同的文件之间来回切换,使得复用变得更加困难。
为了解决这个问题,Hook 将组件中相互关联的部分拆分成更小的函数(比如设置订阅或请求数据),而并非强制按照生命周期划分。你还可以使用 reducer 来管理组件的内部状态,使其更加可预测。
举个栗子来说明一下:
import React from 'react';
class FriendStatus extends React.Component{
componentDidMount(){
// 订阅好友在线状态
// 事件绑定
// 设置定时器
}
componentDidUpdate(){
// 取消订阅好友在线状态
// 订阅好友在线状态
// 事件解绑
// 事件绑定
// 清除定时器
// 设置定时器
}
componentWillUnMount(){
// 取消订阅好友在线状态
// 事件解绑
// 清除定时器
}
}
以上事例我们发现,同一个模块的功能散列在不同的地方,这使代码可读性、复杂性和可维护性大大降低,也很容易造成内存泄漏、性能下降、容易出错等,我们来看下hook内我们的实现:
function FriendStatus(props) {
useEffect(() => {
// 订阅好友在线状态
return () => {
// 取消订阅好友在线状态
}
})
useEffect(() => {
// 事件绑定
return () => {
// 事件解绑
}
})
useEffect(() => {
// 设置定时器
return () => {
// 清除定时器
}
})
}
用hook后我们发现同一块的功能在一个useEffect内,对于代码可读性、复杂性和可维护性都有很大提升。
3、难以理解的 class
除了代码复用和代码管理会遇到困难外,我们还发现 class 是学习 React 的一大屏障。拿个栗子来讲下:
class Example extends React.Component {
constructor(props) {
super(props);
this.state = {
count: 0
};
}
handle() {
this.setState({ count: this.state.count + 1 })
}
render() {
return <button onClick={this.handle.bind(this)}>Click me</button>;
}
}
function Example(props) {
const [count, setCount] = useState(0);
return <button onClick={setCount(count+1)}>Click me</button>;
}
你必须去理解 javascript 中 this 的工作方式,这与其他语言存在巨大差异。还不能忘记绑定事件处理器。没有稳定的语法提案,这些代码非常冗余。大家可以很好地理解 props,state 和自顶向下的数据流,但对 class 却一筹莫展。即便在有经验的 React 开发者之间,对于函数组件与 class 组件的差异也存在分歧,甚至还要区分两种组件的使用场景。
另外,class 也给目前的工具带来了一些问题。例如,class 不能很好的压缩,并且会使热重载出现不稳定的情况。因此,我们想提供一个使代码更易于优化的 API。
为了解决这些问题,Hook 使你在非 class 的情况下可以使用更多的 React 特性。 从概念上讲,React 组件一直更像是函数。而 Hook 则拥抱了函数,同时也没有牺牲 React 的精神原则。Hook 提供了问题的解决方案,无需学习复杂的函数式或响应式编程技术。
接下来我们分析一下常用hook的实现原理,主要有一下几个hook:
useState、useReducer、useEffect、useLayoutEffect、useCallback、useMemo。
二、基础知识
1、fiber概述
在现有React中,更新过程是同步的,这可能会导致性能问题。
当React决定要加载或者更新组件树时,会做很多事,比如调用各个组件的生命周期函数,计算和比对Virtual DOM,最后更新DOM树,这整个过程是同步进行的,也就是说只要一个加载或者更新过程开始,那React就会一鼓作气运行到底,中途绝不停歇。在此过程中浏览器渲染引擎处于挂起的状态,无法进行任何渲染,浏览器无法执行任何其他的任务,调用栈如下图


破解javascript中同步操作时间过长的方法其实很简单——分片。
把一个耗时长的任务分成很多小片,每一个小片的运行时间很短,虽然总时间依然很长,但是在每个小片执行完之后,都给其他任务一个执行的机会,这样唯一的线程就不会被独占,其他任务依然有运行的机会。
React Fiber把更新过程碎片化,执行过程如下面的图所示,每执行完一段更新过程,就把控制权交还给React负责任务协调的模块,看看有没有其他紧急任务要做,如果没有就继续去更新,如果有紧急任务,那就去做紧急任务。
有了分片之后,更新过程的调用栈如下图所示,中间每一个波谷代表深入某个分片的执行过程,每个波峰就是一个分片执行结束交还控制权的时机。

维护每一个分片的数据结构,就是Fiber。其数据结构的定义如下:
Fiber = {
tag, // 标记不同的组件类型
key, // ReactElement里面的key
elementType, // ReactElement.type,也就是我们调用`createElement`的第一个参数
type, // 一般是`function`或者`class`
stateNode, // 在浏览器环境,就是DOM节点
return, // 指向他在Fiber节点树中的`parent`,用来在处理完这个节点之后向上返回
child, // 单链表树结构,指向自己的第一个子节点
sibling, // 指向自己的兄弟结构,兄弟节点的return指向同一个父节点
index,
ref, // ref属性
pendingProps, // 即将更新的props
memoizedProps, // 更新props
memoizedState, // 当前状态
dependencies, // 一个列表,存放这个Fiber依赖的context
flags, // Effect,用来记录当前fiber的tag,插入、删除、更新的状态
subtreeFlags,
deletions,
updateQueue, // 该Fiber对应的组件产生的Update会存放在这个队列里面
nextEffect, // 单链表用来快速查找下一下side effect
firstEffect, // 自述中第一个side effect
lastEffect, // 子树中最后一个side effect
lanes, // 当前Fiber更新的优先级
childLanes,
// 在Fiber树更新的过程中,每个Fiber都会有一个跟其对应的Fiber
// 我们称他为`current <==> workInProgress`
// 在渲染完成之后他们会交换位置
alternate,
// 用来描述当前Fiber和他子树的`Bitfield`
// 共存的模式表示这个子树是否默认是异步渲染的
// Fiber被创建的时候他会继承父Fiber
// 其他的标识也可以在创建的时候被设置
// 但是在创建之后不应该再被修改,特别是他的子Fiber创建之前
mode,
// 其余为调试相关的,收集每个Fiber和子树渲染时间的
//...
}
在react-hooks源码解析中我们主要涉及到memoizedState、updateQueue、flags字段。
2、react工作流程
React16架构可以分为三层:
调度阶段 —— 调度任务的优先级,高优任务优先进入render阶段
render阶段 —— 负责找出变化的组件,生成effectList
commit阶段 —— 根据effectList,将变化的组件渲染到页面上,并且执行生命周期、useEffect、useLayoutEffect回调函数等。
3、函数组件执行的时机
函数组件是在render阶段执行的,而每次更新渲染都会进入render阶段,所以每次更新的时候,都会执行函数组件,类似class的render方法。
三、原理解析
我们先来讲解一下useState这个hook,这也是我们最常用的,它对标class组件的state。
1、useState
1)、示例解析
import React, { useState } from 'react'
function App() {
const [count, setCount] = useState(0);
return (
<div>
<div>{count}</div>
<div onClick={() => {
setCount(1);
setCount((state) => count + 2);
setCount((state) => count + 3);
}}>加</div>
</div>
)
}
export default App;
对于上面的示例,我们需要关注的点是第一次调用函数组件时做了什么事情(首次渲染)?setCount时执行了什么事情?再次执行函数组件时做了什么事情(再次渲染)?这里先概括一下:
(1)、首次渲染主要是初始化hook,将初始值存入hook内,将hook插入到fiber.memoizedState的末尾。
(2)、setCount主要是将更新信息插入到hook.queue.penging的末尾。这里注意一下为什么没有直接更新hook.memoizedState呢?答案是react是批量更新的,需要将更新信息先存储下来,等到合适的时机统一计算更新。
(3)、再次渲染主要是根据setCount存储的更新信息来计算最新的state。
好,我们上面大概讲了下useState做的主要的事情,那具体数据都是怎么流转的呢?react-fiber主要是围绕着fiber数据结构做一些更新存储计算等操作,那在这几个过程中fiber都经历了什么呢?带着这两个问题,我们来做一下讲解。
(1)、首次渲染
我们知道hook可以让你在不编写 class 的情况下使用 state 以及其他的 React 特性。所以hook很大一个功能是存储state。在class组件中我们的state是存储在fiber.memoizedState字段的,是一个对象。同理在函数组件内hook(所有的hook,不止是useState)的信息也是存储在fiber.memoizedState字段.的。以上示例中,当我们第一次执行 const [count, setCount] = useState(0) 时,我们得到的fiber.memoizedState的数据结构如图所示:
function mountState( initialState ) {
const hook = mountWorkInProgressHook();
if (typeof initialState === 'function') {
initialState = initialState();
}
hook.memoizedState = hook.baseState = initialState;
const queue = (hook.queue = {
pending: null,
dispatch: null,
lastRenderedReducer: basicStateReducer,
lastRenderedState: initialState,
});
const dispatch = queue.dispatch = dispatchAction.bind(
null, currentlyRenderingFiber, queue,
);
return [hook.memoizedState, dispatch];
}
字段释义:
baseState:每次更新时的基准state,大部分情况下和memoizedState一致,有异步更新时会有差别
memoizedState:保存本hook的信息,不同的hook存储的结构不一致,在useState上代表的是state值,在上例中就是0
queue:记录更新的信息
dispatchAction:在setCount时候所执行的方法
lastRenderedReducer:每次计算新state时候的方法
lastRenderedState:上一次state的值
pending:存储更新,setCount再讲一下其结构
baseQueue:表示上一次计算新state之后,剩下的优先级低的更新,结构同queue.pending
hook是这个结构,useReducer和useState完全一样,其他的hook只用到了memoizedState字段。
(2)、setCount
当我们点击按钮,在执行
setCoun(1)
setCount((state) => state + 2)
setCount((state) => state + 3)
时,我们得到的fiber的数据结构如图所示,其中hook.queue.pengding为环状链表:


解读一下queue.pending的数据结构
action:要更新的信息,可以是function、变量
eagetReducer:如果是第一个更新,在dispatchAction的时候就计算出来存储在这里
eagetReducer:如果是第一个更新,在dispatchAction的时候就存储reducer
lane:优先级
next: 指向下一个更新
Q:关于更新队列为什么是环状?
A:这是因为方便定位到链表的第一个元素。pending指向它的最后一个update,pending.next指向它的第一个update。
试想一下,若不使用环状链表,pending指向最后一个元素,需要遍历才能获取链表首部。即使将pending指向第一个元素,那么新增update时仍然要遍历到尾部才能将新增的接入链表。而环状链表,只需记住尾部,无需遍历操作就可以找到首部。
(3)、再次渲染
执行了setCount之后,react会再次进入render阶段,执行我们的函数组件所对应的方法,再次渲染,react计算出来了最新的值。计算的方法就是看传递给setCount的参数是不是一个方法,是的话就执行(参数为上一次计算出来的最新的state)计算新值,否则传进来的参数给新值。将新值赋值在memoizedState上。
我们的例子中,setCount(1),新值为1;setCount((state) => state + 2),新值为1+2=3;setCount((state) => state + 3),新值为3+3=6。新值6赋值给memoizedState,得到fiber结构如下图所示:


2)、原理解析
当函数组件进入render阶段 时,会调用renderWithHooks方法,该方法内部会执行函数组件对应函数(即App())。你可以在这里 看到这段逻辑。
我们来看一个流程图,对 首次渲染-setCount-再次渲染 进行分析:


3)、源码实现
(1)、首次渲染
首次渲染主要是初始化hook,插入到fiber.memoizedState的末尾。
function mountState( initialState ) {
const hook = mountWorkInProgressHook();
if (typeof initialState === 'function') {
initialState = initialState();
}
hook.memoizedState = hook.baseState = initialState;
const queue = (hook.queue = {
pending: null,
dispatch: null,
lastRenderedReducer: basicStateReducer,
lastRenderedState: initialState,
});
const dispatch = queue.dispatch = dispatchAction.bind(
null, currentlyRenderingFiber, queue,
);
return [hook.memoizedState, dispatch];
}
mountWorkInProgressHook实现在这里。basicStateReducer是计算更新的方法,实现如下:
function basicStateReducer(state, action) {
return typeof action === 'function' ? action(state) : action;
}
(2)、setCount
在调用setCount的时候,真正调用了dispatchAction方法。主要做的事情是hook.queue.pending插入更新,并且进入调度。实现如下:
function dispatchAction( fiber, queue, action ) {
// 创建一个update
const eventTime = requestEventTime();
const lane = requestUpdateLane(fiber);
const update = { lane, action, eagerReducer: null, eagerState: null, next: null };
// 将此update插入到hook.queue.pending的最后一个
const pending = queue.pending;
if (pending === null) {// 这是第一个update,创建一个环状链表
update.next = update;
} else {// 将此update插入到hook.update.pending链表内
update.next = pending.next;
pending.next = update;
}
// queue.pending指向最新的update,意为最后一个,在循环的时候从first= queue.pending.next开始,到queue.pending.next止
queue.pending = update;
const alternate = fiber.alternate;
// ... 优化容错相关
// 进入调度
scheduleUpdateOnFiber(fiber, lane, eventTime);
// ..
}
(3)、再次渲染
再次渲染主要是根据setCount存储的更新信息来计算最新的state。
源码实现如下:
function updateReducer( reducer, initialArg, init ) {
const hook = updateWorkInProgressHook();
const queue = hook.queue;
queue.lastRenderedReducer = reducer;
const current = currentHook;
let baseQueue = current.baseQueue;
// 将queue.pending合并到baseQueue,清空queue.pending
const pendingQueue = queue.pending;
if (pendingQueue !== null) {
if (baseQueue !== null) {
// Merge the pending queue and the base queue.
const baseFirst = baseQueue.next;
const pendingFirst = pendingQueue.next;
baseQueue.next = pendingFirst;
pendingQueue.next = baseFirst;
}
current.baseQueue = baseQueue = pendingQueue;
queue.pending = null;
}
// 遍历baseQueue,依次计算state的值,得到最终的newState, newState赋值给memoizedState,清空baseQueue等字段
if (baseQueue !== null) {
let newState = current.baseState;
do {
const updateLane = update.lane;
const action = update.action;
newState = reducer(newState, action);
update = update.next;
} while (update !== null && update !== first);
hook.memoizedState = newState;
}
const dispatch = queue.dispatch;
return [hook.memoizedState, dispatch];
}
其中updateWorkInProgressHook实现在这里。
2、 useReducer vs useState
上面讲解了useState,有一个和他作用比较相似的hook,它就是useReducer,也是用来存储状态的,不同的是,计算新的状态的时候,是用户自己计算的,可以支持更复杂的场景,我们先来看一下它的用法。
1)、示例
const initialState = {count: 0};
function reducer(state, action) {
switch (action.type) {
case 'increment':
return {count: state.count + 1};
case 'decrement':
return {count: state.count - 1};
default:
throw new Error();
}
}
function Counter() {
const [state, dispatch] = useReducer(reducer, initialState);
return (
<>
Count: {state.count}
<button onClick={() => dispatch({type: 'decrement'})}>-</button>
<button onClick={() => dispatch({type: 'increment'})}>+</button>
</>
);
}
我们看到在用法上,useReducer和useState的返回值是一致的,区别是useReducer
第一个参数是一个function,是用于计算新的state所执行的方法,对标useState的basicStateReducer。我们看到reducer的实现和redux很相似,原因是Redux的作者Dan加入React核心团队,其一大贡献就是“将Redux的理念带入React”。
第二个参数是初始值
第三个参数是计算初始值的方法,其执行时候的参数是第二个参数
2)、使用场景
所有用useState实现的场景都可以用useReducer来实现,像如下复杂的场景更适合用useReducer,比如state逻辑较复杂且包含多个子值,或者下一个 state 依赖于之前的 state 等。
3、 useEffect vs useLayoutEffect
上面讲了存储状态相关的两个hook,接下来讲解下类比class组件生命周期的两个hook,useEffect和useLayoutEffect相当于class组件的以下生命周期:componentDidMount、componentDidUpdate、componentWillUnMount,二者使用方式完全一样,不同的点是调用的时机不同,以useEffect为示例来说明一下:
1)、示例解析
import React, { useState, useEffect } from 'react'
function App() {
const [count, setCount] = useState(0);
useEffect(() => {
console.log('useEffect:', count);
return () => {
console.log('useEffect destory:', count);
}
}, [count])
return (
<div>
<div>{count}</div>
<div onClick={() => setCount(count + 1) }>加1</div>
</div>
)
}
export default App;
上面的示例,我们需要关注的是useEffect的回调函数和其返回的函数,是什么时机执行的?又是通过什么机制来判定要不要执行呢?fiber的结构又是怎么变化的呢?这里先概括一下:
useEffect的实现,是在render阶段给fiber和hook设置标志位,在commit阶段根据标志位来执行回调函数和销毁函数,后面将按照 render阶段 - commit阶段 来进行讲解,commit阶段又分为3个阶段,分别是before mutation阶段(执行dom操作前)、mutation阶段(执行dom操作)、layout阶段(执行dom操作后)
上述示例中首次渲染执行到useEffect之后,挂载到fiber.memoizedState的数据结构如下:


再次渲染结果,此时destory是有值的,其他不变。结果如下:


数据结构解读:
create:useEffect和useLayoutEffect的回调函数
destory:useEffect和useLayoutEffect的回调函数的返回值
deps:依赖数组
tag:hook的标志位,commit阶段会根据这个标志来决定是不是要执行
next: 指向下一个effect
在commit阶段就是根据fiber.flags和hook.tag来半段是否执行create或者destory。
2)、原理解析
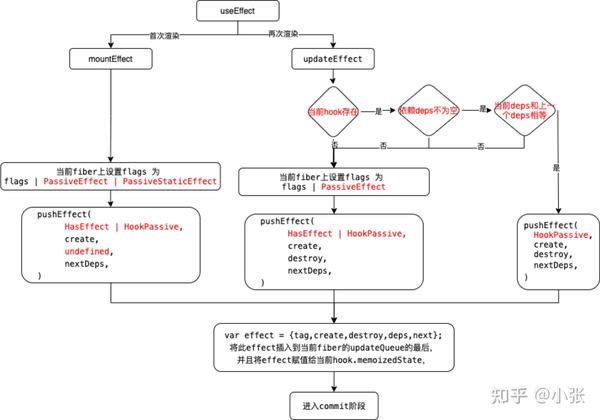
每个阶段分别作了什么事情,我们来看一下,render阶段流程图:

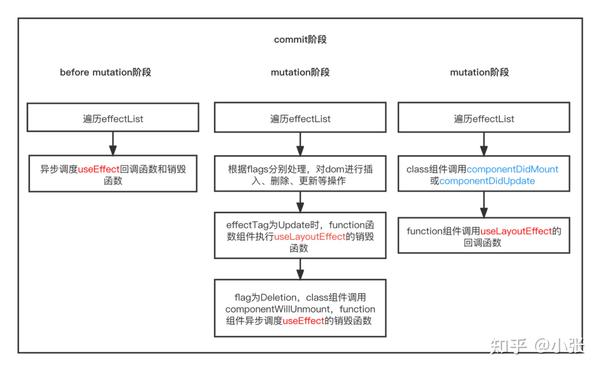
commit阶段流程图:

划一下重点:
(1)、render阶段
A、首次渲染
l 给fiber设置标志位
l 将生成的effect = {tag, create, destroy: undefined, deps, netx: null},插入到fiber.updateQueue末尾
l 将effect插入到hook.memoizedState末尾
B、再次渲染
l 与首次渲染的区别是在设置标志位之前,需要先比较一下上一次的依赖项和本次的依赖项是否一致,不一致和一致设置的标志位不一样。
(2)、commit阶段
A、befor before mutation阶段(执行DOM操作前)
l 异步调度useEffect
B、mutation阶段(执行DOM操作)
l 根据flags分别处理,对dom进行插入、删除、更新等操作
l flags为Update时,function函数组件执行useLayoutEffect的销毁函数
l flags为Deletion,class组件调用componentWillUnmount,function组件调度useEffect的销毁函数
C、layout阶段
l class组件调用componentDidMount或componentDidUpdate
l function组件调用useLayoutEffect的回调函数
异步调度的原理:如下图左,需要注意的是GUI线程和js引擎线程是互斥的,当js引擎执行时,GUI线程会被挂起,相当于被冻结了,GUI更新会被保存在一个队列中,等js引擎空闲时(可以理解js运行完后)立即被执行。
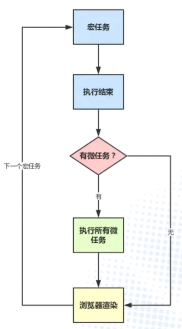

如上右图,我们的调度可以简单的理解为是类似setTimeout的宏任务,当然其内部实现要比这个复杂多了。当commit阶段整个执行完毕之后,浏览器会启动 GUI渲染引擎 进行一次绘制,绘制完毕之后,浏览器会取出一个宏任务来执行(react会保证我们异步调度的useEffect的函数会在下一次更新之前执行完毕)。
因此,在这个mutaiton阶段,我们已经把发生的变化映射到真实 DOM 上了,但由于 JS 线程和浏览器渲染线程是互斥的,因为 JS 虚拟机还在运行,即使内存中的真实 DOM 已经变化,浏览器也没有立刻绘制到屏幕上。
commit 阶段是不可打断的,会一次性把所有需要 commit 的节点全部 commit 完,至此 react 更新完毕,JS 停止执行
浏览器渲染线程把发生变化的 DOM 绘制到屏幕上,到此为止 react 把所有需要更新的 DOM 节点全部更新完成。
绘制完成后,浏览器通知 react 自己处于空闲阶段,react 开始执行自己调度队列中的任务,此时才开始执行 useEffect(create, deps) 的产生的函数。
3)、源码实现
(1)、render阶段
mountEffect实现在这里,updateEffect实现在这里,mountLayoutEffect实现在这里,updateLayoutEffect实现在这里,useEffectLayout vs useEffect 标志位情况如下:
| 时机 | fiber.flags | hook.memoizedState | |
| useEffect | 首次渲染 | flags | UpdateEffect | PassiveEffect | tag: HookHasEffect | HookPassive,destory:undefined |
| useEffect | 再次渲染deps相同 | flags | UpdateEffect | PassiveEffect | tag: HookPassive,destory |
| useEffect | 再次渲染deps不同 | flags | UpdateEffect | PassiveEffect | tag: HookHasEffect | HookPassive, destory |
| useLayoutEffect | 首次渲染 | flags | UpdateEffect | tag: HookHasEffect | HookLayout,destory:undefined |
| useLayoutEffect | 再次渲染deps相同 | flags | UpdateEffect | tag:HookLayout,destory |
| useLayoutEffect | 再次渲染deps不同 | flags | UpdateEffect | tag: HookHasEffect | HookLayout,destory |
其中这几个标志位是二进制,如下:
// flags相关
export const UpdateEffect = 0b000000000000000100;
export const PassiveEffect = 0b000000001000000000;
export const PassiveStaticEffect = 0b001000000000000000;
export const MountLayoutDevEffect = 0b010000000000000000;
export const MountPassiveDevEffect = 0b100000000000000000;
// hook相关
export const HookHasEffect = 0b001;
export const HookPassive = 0b100;
export const HookLayout = 0b010;
export const NoHookEffect = 0b000;
我们看到,在设置标志位的时候,都是用的逻辑或,即是在某一位上添加上1,在判断的时候,我们只需要判断fiber或者hook上在某一位上是不是1即可,这时候应该用逻辑与来判断。
(2)、commit阶段
A、before mutation阶段
a、before mutation异步调度实现:
if ((flags & Passive) !== NoFlags) {
scheduleCallback(NormalSchedulerPriority, () => {
flushPassiveEffects();
return null;
});
}
B、mutation阶段
a、根据effectTag分别处理,对dom进行插入、删除、更新等操作
b、effectTag为Deletion,class组件调用componentWillUnmount,function组件异步调度useEffect的销毁函数,以下为异步调度的方法同A.a。
c、effectTag为Update时,function函数组件执行useLayoutEffect的销毁函数,实现在这里。
C、layout阶段
a、class组件调用componentDidMount 或componentDidUpdate
b、function组件调用useLayoutEffect的回调函数,实现在这里。
那么useEffect是怎样异步执行的呢?我们来看一下
(1)、在beforeMutation和mutation阶段异步调度flushPassiveEffects。
(2)、flushPassiveEffects实现在这里。遍历root.current,依次执行。
4)、使用场景
useEffect: 适用于许多常见的副作用场景,比如设置订阅和事件处理等情况,不会在函数中执行阻塞浏览器更新屏幕的操作。
useLayoutEffect: 适用于在浏览器执行下一次绘制前,用户可见的 DOM 变更就必须同步执行,这样用户才不会感觉到视觉上的不一致。
4、useCallback
其上面讲述了类似class组件生命周期相关的hook,componentDidMount、componentDidUpdate、componentWillUnMount,这里讲一下性能优化相关的hook,useCallback和useMemo。
1)、示例解析
import React, { useState, useCallback } from 'react'
function App() {
const {count, setCount} = useState(0);
const memoizedCallback = useCallback(() => count, [count]);
return (
<div>
<div>{count}</div>
<div>{memoizedCallback}</div>
</div>
)
}
export default App;
2)、源码实现
A、首次渲染
function mountCallback( callback, deps ) {
const hook = mountWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
hook.memoizedState = [callback, nextDeps];
return callback;
}
B、再次渲染
function updateCallback(callback, deps ) {
const hook = updateWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
const prevState = hook.memoizedState;
if (prevState !== null) {
if (nextDeps !== null) {
const prevDeps: Array<mixed> | null = prevState[1];
if (areHookInputsEqual(nextDeps, prevDeps)) {
return prevState[0];
}
}
}
hook.memoizedState = [callback, nextDeps];
return callback;
}
5、useMemo vs useCallback
1)、示例解析
import React, { useState, useMemo } from 'react'
function App() {
const {count, setCount} = useState(0);
const memoizedMemo = useMemo(() => count, [count]);
return (
<div>
<div> {count}</div>
<div>{memoizedMemo}</div>
</div>
)
}
export default App;
我们看下useMemo和useCallback的区别,用法一样,返回值useMemo是返回的执行方法之后得到的结果,memoizedState存储的第一项也是执行方法之后得到的结果。
2)、源码实现
A、首次渲染
function mountMemo( nextCreate, deps ) {
const hook = mountWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
const nextValue = nextCreate();
hook.memoizedState = [nextValue, nextDeps];
return nextValue;
}
B、再次渲染
function updateMemo<T>( nextCreate, deps ) {
const hook = updateWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
const prevState = hook.memoizedState;
if (prevState !== null) {
if (nextDeps !== null) {
const prevDeps = prevState[1];
if (areHookInputsEqual(nextDeps, prevDeps)) {
return prevState[0];
}
}
}
const nextValue = nextCreate();
hook.memoizedState = [nextValue, nextDeps];
return nextValue;
}
3)、使用场景
class组件一个性能优化的点:shouldComponentUpdate,function组件没有shouldComponentUpdate,有较大的性能损耗,useMemo 和useCallback就是解决性能问题的杀手锏。
A、useCallback
如下面的例子,父组件传递给子组件一个callback函数,那么当input框内有变化时,都会触发更新渲染操作,Parent方法组件都会执行,每次callback都是新定义的一个方法变量,那每次指针也都是不一致的,所以每次也会触发Child方法组件的更新,而我们看到Child组件只是用到了count,并没有用到name,所以我们希望的是input有变化(也就是name变化时)不重新渲染Child,这个时候就可以用useCallback了
import React, { useState, useEffect, useCallback } from 'react';
function Parent() {
const [count, setCount] = useState(1);
const [val, setVal] = useState('');
const callback = () => {
return count;
}
return (
<div>
<h4>{count}</h4>
<Child callback={callback} />
<div>
<button onClick={ () => setCount(count + 1) }>+</button>
<input value={val} onChange={ event => setVal(event.target.value) }/>
</div>
</div>
);
}
function Child({ callback }) {
const [count, setCount] = useState( () => callback() );
useEffect(() => {
setCount(callback());
}, [callback]); // 函数可以作为依赖项参与到数据流中
return <div>{count}</div>;
}
我们对callback做如下改造
const callback = useCallback( () => {
return count;
}, [count])
如此一来,只有当count改变的时候,callback才会重新赋值,当count不改变的时候,就会从内存中取值了。
B、useMemo
import React from 'react';
export default function WithoutMemo() {
const [count, setCount] = useState(1);
const [val, setValue] = useState('');
function expensive() {
console.log('compute');
let sum = 0;
for (let i = 0; i < count * 100; i++) {
sum += i;
}
return sum;
}
return <div>
<h4>{count}-{val}-{expensive()}</h4>
<div>
<button onClick={() => setCount(count + 1)}>+c1</button>
<input value={val} onChange={event => setValue(event.target.value)}/>
</div>
</div>;
}
这里创建了两个state,然后通过expensive函数,执行一次昂贵的计算,拿到count对应的某个值。我们可以看到:无论是修改count还是val,由于组件的重新渲染,都会触发expensive的执行(能够在控制台看到,即使修改val,也会打印);但是这里的昂贵计算只依赖于count的值,在val修改的时候,是没有必要再次计算的。在这种情况下,我们就可以使用useMemo,只在count的值修改时,执行expensive计算:
const expensive = useMemo(() => {
console.log('compute');
let sum = 0;
for (let i = 0; i < count * 100; i++) {
sum += i;
}
return sum;
}, [count])
上面我们可以看到,使用useMemo来执行昂贵的计算,然后将计算值返回,并且将count作为依赖值传递进去。这样,就只会在count改变的时候触发expensive执行,在修改val的时候,返回上一次缓存的值。
小结:
1、如果有函数传递给子组件,使用useCallback
2、缓存一个组件内的复杂计算逻辑需要返回值时,使用useMemo
3、如果有值传递给子组件,使用useMemo
四、小结
总结以下这几个hook的整体流程,其中相似的hook我们只讲一个,如下表:
| 触发更新 | 调度阶段 | render阶段 | commit阶段 |
| reactDom.render | 调度fiber | 调用函数组件方法(App()): 1、useState,初始化hook,赋值初始值给hook 2、useEffect,初始化hook,给fiber和hook设置标志位 3、useCallback,初始化hook,赋值回调函数和依赖项 | 2、useEffect根据标志位来执行回调函数和销毁函数 |
| setCount 在fiber上设置更新信息 | 调度fiber | 调用函数组件方法(App()): 1、useState,根据更新信息计算新值给hook 2、useEffect,依赖项有变化,给hook设置标志位 3、useCallback,依赖项有变化,重置回调函数 | 2、useEffect根据标志位来执行回调函数和销毁函数 |