






决策树
决策树是一种树型结构,其中每个内部节结点表示在一个属性上的测试,每一个分支代表一个测试输出,每个叶结点代表一种类别。
决策树学习是以实例为基础的归纳学习
决策树学习采用的是自顶向下的递归方法,其基本思想是以信息熵为度量构造一棵熵值下降最快的树。到叶子节点的处的熵值为零,此时每个叶结点中的实例都属于同一类。
最近在学习决策树的分类原理(DecisionTreeClassifier),决策树的划分依据之一是信息增益。
决策树的criterion可以选择’gini‘或者是’entropy‘。
基尼系数:
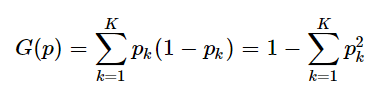
信息熵:
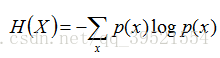
决策树实例(entropy):
下表记录小明每一次考试的状态与成绩好坏的关系
| 复习 | 睡眠质量 | 饱腹状态 | 情绪 | 成绩 |
|---|---|---|---|---|
| 有 | 好 | 饱 | 开心 | 好 |
| 有 | 差 | 饱 | 开心 | 好 |
| 有 | 中 | 饱 | 伤心 | 差 |
| 无 | 差 | 饿 | 伤心 | 差 |
| 无 | 好 | 饿 | 开心 | 好 |
| 有 | 好 | 饱 | 无感 | 好 |
| 有 | 差 | 饱 | 无感 | 差 |
import pandas as pd
from sklearn import tree
import numpy as np
import graphviz
df = pd.DataFrame(columns=['复习', '睡眠质量', '饱腹状态', '情绪', '成绩'],
data={'复习': ['有', '有', '有', '无', '无', '有', '有'],
'睡眠质量': ['好', '差', '差', '差', '好', '好', '差'],
'饱腹状态': ['饱', '饱', '饱', '饿', '饿', '饱', '饱', ],
'情绪': ['开心', '开心', '伤心', '伤心', '开心', '无感', '无感', ],
'成绩': ['好', '差', '好', '差', '好', '好', '差']})
print(df)
for i in ['复习', '睡眠质量', '饱腹状态', '情绪', '成绩']:
labels = df[i].unique().tolist() # 处理数据成二三分类
df[i] = df[i].apply(lambda x: labels.index(x))
print(df)
df1 = df.drop(['成绩'], axis=1)
x_data = np.array(df1)
y_target = np.array(df['成绩'])
print(y_target)
model = tree.DecisionTreeClassifier(criterion='entropy')
model = model.fit(x_data, y_target)
dot_data = tree.export_graphviz(model,
feature_names=['Review', 'Sleep quality', 'Full state', 'Mood'],
filled=True,
rounded=True
)
graph = graphviz.Source(dot_data)
graph.view()

颜色越深,代表的不纯度指标越低,就是数据越纯
比如第一个节点中values=[4,3],睡眠质量好的有3个,睡眠质量差的有4个,第一个节点的分类依据是Sleep quality
有些数学符号打不出来,我用代码写出来
#第一个entropy
-((4/7)*math.log2(4/7)+(3/7)*math.log2(3/7))=0.9852281360342516
#第二个entropy
-((3/4)*math.log2(3/4)+(1/4)*math.log2(1/4))=0.8112781244591328
#第三个entropy
-((2/3)*math.log2(2/3)+(1/3)*math.log2(1/3))=0.9182958340544896
决策树划分依据(entropy):
决策树以信息熵增益最大进行划分,继续以上面的表为例
下面计算第一个节点划分原理(log2用log代替)
H(x)=-[(4/7)*log(4/7)+(3/7)*log(3/7)]=0.9852281360342516
H(睡眠)=-[(3/7)*[(3/3)*log(3/3)+(0/3)*log(0/3)]]=0.4635
H(饱腹)=-[(5/7)*[(3/5)*log(3/5)+(2/5)*log(2/5)]+(2/7)*[(1/2)*[(1/2)*log(1/2)+(1/2)*log(1/2)]]]=-0.9792504246104775
H(复习)=-[(5/7)*[(3/5)*log(3/5)+(2/5)*log(2/5)]+(2/7)*[(1/2)*[(1/2)*log(1/2)+(1/2)*log(1/2)]]]=-0.9792504246104775
H(情绪)=-[(3/7)*[(2/3)*log(2/3)+(1/3)*log(1/3)]+(2/7)*[(1/2)*log(1/2)+(1/2)*log(1/2)]+(2/7)*[(1/2)*log(1/2)+(1/2)*log(1/2)]]=
0.9649839288804954
信息增益:
IG (T)=H (X)-H (X|T)
H(x)-H(睡眠)时,信息增益最大,所以第一个节点以睡眠质量划分














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









