消息队列:pulsar和其他消息队列的存储对比(kafka)

本文讨论了Apache Pulsar如何处理存储并将其与其他流行的数据处理技术(例如Apache Kafka)如何处理存储进行比较。
原文地址:
这个大佬正在写的书:
这是大家喜闻乐见的 XX in action
Scalable storage Apache Pulsar's multilayered architecture completely decouples the message serving layer from the message storage layer, allowing each to scale independently. Traditional distributed data processing technologies such as Hadoop and Spark have taken the approach of co-locating data processing and data storage on the same cluster nodes or instances. That design choice offered a simpler infrastructure and some possible performance benefits due to reducing transfer of data over the network, but at the cost of a lot of tradeoffs that impact scalability, resiliency and operations.
Pulsar's architecture takes a very different approach that's starting to gain traction in a number of cloud-native solutions. This approach is made possible in part by the significant improvements in network bandwidth that are commonplace today: separation of compute and storage. Pulsar's architecture decouples data serving and data storage into separate layers: Data serving is handled by stateless "broker" nodes, while data storage is handled by "bookie" nodes as shown in Figure 1.
本文讨论了Apache Pulsar如何处理存储并将其与其他流行的数据处理技术(例如Apache Kafka)如何处理存储进行比较。
可扩展的存储 Apache Pulsar的多层体系结构将消息服务层与消息存储层完全分离,从而使每个消息层都可以独立扩展。诸如Hadoop和Spark之类的传统分布式数据处理技术已采用将数据处理和数据存储共存于同一群集节点或实例上的方法。由于减少了通过网络的数据传输,因此该设计选择提供了更简单的基础结构和一些可能的性能优势,但是却付出了很多折衷的代价,这些折衷会影响可伸缩性,弹性和运营。 Pulsar的体系结构采用了一种截然不同的方法,这种方法开始在许多云原生解决方案中获得关注。这种方法之所以成为可能,部分原因是由于当今带宽的显着提高:计算和存储的分离。 Pulsar的体系结构将数据服务和数据存储分离成单独的层:数据服务由无状态的“代理”节点处理,而数据存储由“ bookie”节点处理,如图1所示。


Figure 1. Decoupled storage and serving layers
====================
This decoupling has many benefits. For one, it enables each layer to scale independently to provide infinite, elastic capacity. By leveraging the ability of elastic environments (such as cloud and containers) to automatically scale resources up and down, this architecture can dynamically adapt to traffic spikes. It also improves system availability and manageability by significantly reducing the complexity of cluster expansions and upgrades. Further, this design is container-friendly, making Pulsar the ideal technology for hosting a cloud native streaming system. Apache Pulsar is backed by a highly scalable, durable stream storage layer based on Apache BookKeeper that provides strong durability guarantees, distributed data storage and replication and built-in geo-replication.
这种解耦有很多好处。首先,它使每一层都可以独立缩放以提供无限的弹性容量。通过利用弹性环境(例如云和容器)的能力来自动扩展和缩减资源,该体系结构可以动态适应流量高峰。它还通过显着降低集群扩展和升级的复杂性来提高系统可用性和可管理性。此外,该设计是容器友好的,使Pulsar成为托管云原生流系统的理想技术。 Apache Pulsar得到了基于Apache BookKeeper的高度可扩展的持久流存储层的支持,该层提供了强大的持久性保证,分布式数据存储和复制以及内置的地理复制。
A natural extension of the multilayered approach is the concept of tiered storage in which less frequently accessed data can be offloaded to a more cost-effective persistence store such as S3 or Azure Cloud. Pulsar provides the ability to configure the automated offloaded of data from local disks in the storage layer to those popular cloud storage platforms. These offloads are triggered based upon a predefined storage size or time period and provide you with a safe backup of all your event data while simultaneously freeing up storage capacity on the local disk for incoming data.
多层架构的自然扩展是分层存储的概念,其中可以将访问频率较低的数据卸载到更具成本效益的持久性存储(例如S3或Azure云)中。 Pulsar提供了将数据从存储层中的本地磁盘自动卸载到那些流行的云存储平台的功能。这些卸载是根据预定义的存储大小或时间段触发的,可为您提供所有事件数据的安全备份,同时释放本地磁盘上用于输入数据的存储容量。
Comparison of Apache Pulsar vs. Kafka Both Apache Kafka and Apache Pulsar have similar messaging concepts. Clients interact with both systems via topics that are logically separated into multiple partitions. When an unbounded data stream is written to a topic, it is often divided into a fixed number of equal sized groupings known as partitions. This allows the data to be evenly distributed across the system and consumed by multiple clients concurrently. The fundamental difference between Apache Pulsar and Apache Kafka is the underlying architectural approach each system takes to storing these partitions. Apache Kafka is a partition- centric pub/sub system that is designed to run as a monolithic architecture in which the serving and storage layers are located on the same node.Apache Pulsar与Kafka的比较 Apache Kafka和Apache Pulsar都具有类似的消息传递概念。客户端通过逻辑上分为多个分区的主题与两个系统进行交互。当无限制的数据流写入主题时,通常将其分为固定数量的大小相等的分组,称为分区。这允许数据在系统中均匀分布,并被多个客户端同时使用。 Apache Pulsar和Apache Kafka之间的根本区别是每个系统用于存储这些分区的基础体系结构方法。 Apache Kafka是一个以分区为中心的发布/订阅系统,旨在以整体架构运行,其中服务层和存储层位于同一节点上。


============
In Kafka, the partition data is stored as a single continuous piece of data on the leader node, and then replicated to a preconfigured number of replica nodes for redundancy. This design limits the capacity of the partition, and by extension the topic, in two ways. First, since the partition must be stored on local disk, the maximum size of the partition is that of the largest single disk on the host machine (approximately 4 TB in a "fresh" install scenario); second, since the data must be replicated, the partition can only grow to the size of smallest amount of disk space on the replica nodes.
在Kafka中,分区数据作为单个连续数据存储在引导节点上,然后复制到预配置数量的副本节点以实现冗余。 这种设计通过两种方式限制了分区的容量,并由此扩展了主题。 首先,由于分区必须存储在本地磁盘上,因此分区的最大大小是主机上最大的单个磁盘的大小(在“新”安装方案中约为4 TB); 其次,由于必须复制数据,因此分区只能增长到副本节点上最小磁盘空间的大小。
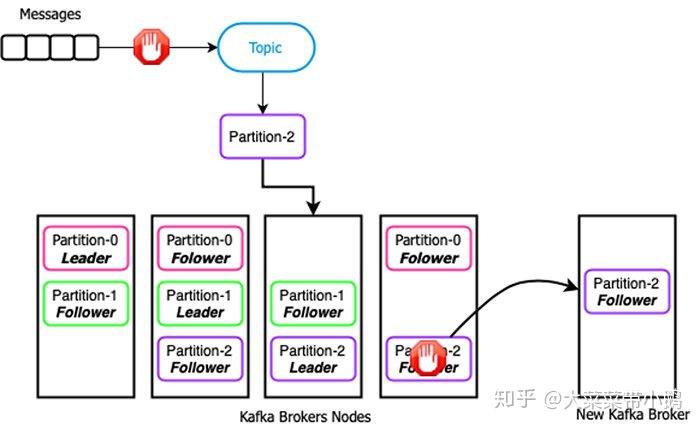

Figure 3. Kafka failure scenario and expansion
Let's consider a scenario in which you were fortunate enough to have your leader be placed on a new node that can dedicate an entire 4 TB disk to the storage of the partition, and the two replica nodes each only have 1 TB of storage capacity. After you have published 1 TB of data to the topic, Kafka would detect that the replica nodes are unable to receive any more data and all incoming messages on the topic would be halted until space is made available on the replica nodes, as shown in Figure 3. This scenario could potentially lead to data loss, if you have producers that are unable to buffer the messages during this outage.
Once you have identified the issue, your only remedies are to either make more room on the existing replica nodes by deleting data from the disks, which will result in data loss, since the data is from other topics and most likely has not been consumed yet. The other option is to add additional nodes to the Kafka cluster and "rebalance" the partition so that the newly added nodes will serve as the replicas. Unfortunately, this requires recopying the entire 1 TB partition, which is an expensive, time-consuming and error-prone process that requires an enormous amount of network bandwidth and disk I/O. What's worse is that the entire partition is completely offline during this process, which is not an ideal situation for a production application that has stringent uptime SLAs. Unfortunately, recopying of partition data isn't limited to only cluster expansion scenarios in Kafka. Several other failures can trigger data recopying, including replica failures, disk failures or machine failures. This limitation is often missed until users experience a failure in a production scenario.
让我们考虑一个场景,在这种情况下,您有幸将领导者放置在一个可以将整个4 TB磁盘专用于分区存储的新节点上,并且两个副本节点每个仅具有1 TB的存储容量。在向该主题发布1 TB数据之后,Kafka将检测到副本节点无法再接收任何数据,并且在该副本节点上有可用空间之前,该主题上的所有传入消息都将被暂停,如图2所示。 3.如果您有生产者在此中断期间无法缓冲消息,则此方案可能导致数据丢失。 一旦发现问题,您唯一的解决方法是通过从磁盘上删除数据来在现有副本节点上腾出更多空间,这将导致数据丢失,因为数据来自其他主题,并且很可能尚未使用。另一个选择是将其他节点添加到Kafka群集并“重新平衡”分区,以便新添加的节点将用作副本。不幸的是,这需要重新复制整个1 TB分区,这是一个昂贵,耗时且容易出错的过程,需要大量的网络带宽和磁盘I / O。更糟糕的是,在此过程中,整个分区完全处于脱机状态,这对于具有严格的正常运行时间SLA的生产应用程序来说不是理想的情况。 不幸的是,分区数据的重新复制不仅限于Kafka中的集群扩展方案。其他几种故障也可以触发数据重新复制,包括副本故障,磁盘故障或计算机故障。在用户遇到生产场景中的故障之前,通常会错过此限制。

Figure 4. Pulsar segments Segment-centric storage in Pulsar
Within a segment-centric storage architecture, such as the one used by Apache Pulsar, partitions are further broken down into segments that are rolled over based on a preconfigured time or size limit. These segments are then evenly distributed across a number of bookies in the storage layer for redundancy and scale.
Using the previous scenario we discussed with Apache Kafka in which one of the bookies disks fills up and can no longer accept incoming data, let's now look at the behavior of Apache Pulsar. Since the partition is further broken down into small segments, there is no need to replicate the content of the entire bookie to the newly added bookie. Instead, Pulsar would continue to write incoming message segments to the remaining bookies with storage capacity until the new bookie is added. At that point, the traffic will instantly and automatically ramp up on new nodes or new partitions, and old data doesn't have be recopied. 在以段为中心的存储架构(例如Apache Pulsar使用的架构)中,分区会进一步细分为可根据预先配置的时间或大小限制进行滚动的段。 然后,将这些段均匀分布在存储层中的许多bookies中,以实现“冗余”和规模化。
使用我们之前讨论过的与Apache Kafka讨论的场景,其中一个bookies磁盘已装满并且不再能够接受传入数据,现在让我们看一下Apache Pulsar的行为。 由于该分区进一步细分为小段,因此无需将整个bookie的内容复制到新添加的bookie。 取而代之的是,Pulsar将继续将传入的消息段写入具有存储容量的其余bookies,直到添加新bookie。 届时,流量将立即自动在新节点或新分区上增加,并且无需重新复制旧数据。
=============
As we can see in Figure 5, during the period when the fourth bookie stopped accepting segments, incoming data segments 4, 5, 6 and 7 were routed to the remaining active bookies. Once the new bookie was added, segments were routed to it automatically. During this entire process, Pulsar experienced no downtime and was able to continue serving producers and consumers. As you can see, Pulsar's storage system is more flexible and scalable in this type of situation.
从图5中可以看到,在第四名bookie停止接受段的期间,传入的数据段4、5、6和7被路由到其余活动的bookie。 一旦添加了新的Bookie,细分就会自动路由到它。 在整个过程中,Pulsar不会停机,并且能够继续为生产商和消费者提供服务。 如您所见,在这种情况下,Pulsar的存储系统更加灵活和可扩展。

