







一、Spark环境测试
1.导入相关库
# import os
# os.environ['JAVA_HOME'] = 'D:\ProgramData\Spark\jdk1.8.0_302'
# os.environ['HADOOP_HOME'] = 'D:\ProgramData\Spark\winutils-master\hadoop-2.7.1'
# os.environ['SPARK_HOME'] = 'D:\ProgramData\Spark\spark-3.1.2-bin-hadoop2.7'
from pyspark.sql import SparkSession
import findspark
findspark.init()2.创建SparkSession实例
# local本地模式
# [*], 最大的线程数量
# [4], 线程数量设置为4
spark = SparkSession.Builder().master("local[*]").getOrCreate()
spark
# http://localhost:4040/
3.创建Spark的DataFrame
df = spark.createDataFrame(
data=[['python', '数据分析'],
['pyspark', '大数据']],
schema=('name', 'type'))
df.show()
# 关闭SparkSession
# spark.stop()+-------+--------+ | name| type| +-------+--------+ | python|数据分析| |pyspark| 大数据| +-------+--------+
4.创建Pandas的DataFrame
import numpy as np
import pandas as pd
pd_df = pd.DataFrame(np.random.rand(100, 3))
pd_df.head(10)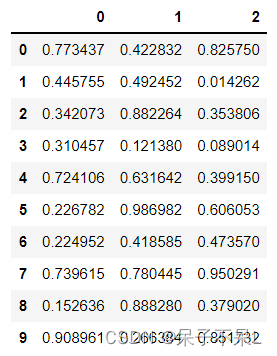
5.从Pandas的DataFrame创建Spark的DataFrame
spark_df = spark.createDataFrame(pd_df)
spark_df.show(10)+-------------------+-------------------+--------------------+ | 0| 1| 2| +-------------------+-------------------+--------------------+ | 0.7734370300584474|0.42283178859893444| 0.8257498529298667| |0.44575544415993906|0.49245180252222975|0.014261692547622662| | 0.3420733794127957| 0.8822635169563398| 0.35380553666355063| |0.31045724993989887|0.12137972216632553| 0.08901413277815406| | 0.7241060466628902| 0.6316423526465608| 0.3991496071189753| |0.22678194237871974| 0.9869818222587557| 0.6060528459473943| |0.22495181866362846| 0.4185845149128945| 0.47356977129591526| | 0.7396151249153267| 0.7804451983660282| 0.9502911251018666| |0.15263591158972922| 0.8882795838843202| 0.3790204587517769| | 0.9089614551221472| 0.2663836523951706| 0.8517316157986443| +-------------------+-------------------+--------------------+ only showing top 10 rows
6.将Spark的DataFrame转为Pandas的DataFrame
pd_df = spark_df.select("*").toPandas()
pd_df.head(10)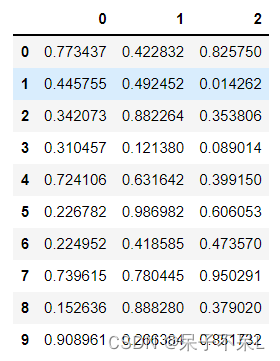
二、RDD
1.RDD——创建RDD
import pyspark
from pyspark import SparkContext, SparkConf
import findspark
findspark.init()
# 或sc = SparkContext(master='local[*]', appName='test')
# SparkContext,无法同时运行多个SparkContext环境
conf = SparkConf().setAppName('test').setMaster('local[*]')
sc = SparkContext(conf=conf)1.查看Spark环境信息
# 查看Python版本
sc.pythonVer
# '3.8'
# 查看Spark版本
sc.version
# 或pyspark.__version__
# '3.1.2'
# 查看主机URL
sc.master
# 'local[*]'
# 查看运行Spark的用户名称
sc.sparkUser()
# 'joe'
# 查看应用程序ID
sc.applicationId
# 'local-1665974057511'
# 查看应用程序名称
sc.appName
# 'test'
# 查看默认的并行级别(线程数量)
sc.defaultParallelism
# 4
# 查看默认的最小分区数量
sc.defaultMinPartitions
# 2
# 查看Spark Web URL
sc.uiWebUrl
# 'http://DESKTOP-H03ONKG:4041'
# 停止运行Spark
# sc.stop()
# '3.8'2.创建RDD
- 创建RDD主要有两种方式
- 第一种:textFile方法
- 第二种:parallelize方法
2.1.textFile方法
- 本地文件系统加载数据
# 第2个参数,指定分区数量
file = "./data/hello.txt"
rdd = sc.textFile(file, 3)
# 展示所有元素
rdd.collect()
# ['python', 'numpy', 'pandas', 'matplotlib', 'pyspark']2.2.parallelize方法
# 第2个参数,指定分区数量
rdd = sc.parallelize(range(1, 11), 2)
rdd.collect()
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 查看RDD的id
rdd.id()
# 3
# 查看分区数量
rdd.getNumPartitions()
# 22.3.wholeTextFiles方法
# 读取文件夹下所有文件
folder = './data/folder/'
rdd = sc.wholeTextFiles(folder)
rdd.collect()
'''
[('file:/C:/课程/PySpark/data/folder/1.txt', '第1个text文件内容'),
('file:/C:/课程/PySpark/data/folder/2.txt', '第2个text文件内容'),
('file:/C:/课程/PySpark/data/folder/3.txt', '第3个text文件内容'),
('file:/C:/课程/PySpark/data/folder/4.txt', '第4个text文件内容'),
('file:/C:/课程/PySpark/data/folder/5.txt', '第5个text文件内容'),
('file:/C:/课程/PySpark/data/folder/6.txt', '第6个text文件内容')]
'''2.RDD——动作算子
import pyspark
from pyspark import SparkContext, SparkConf
import findspark
findspark.init()
conf = SparkConf().setAppName('test').setMaster('local[*]')
sc = SparkContext(conf=conf)- Action动作算子/行动操作
1.collect
rdd = sc.parallelize(range(10))
# 查看所有的元素
rdd.collect()
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]2.take
rdd = sc.parallelize(range(10))
# 查看指定数量的元素
rdd.take(4)
# [0, 1, 2, 3]3.first
rdd = sc.parallelize(range(10))
# 获取第1个元素
rdd.first()
# 04.top
rdd = sc.parallelize(range(10))
# 获取top n的元素
rdd.top(3)
# [9, 8, 7]5.takeOrdered
rdd = sc.parallelize([10, 7, 6, 9, 4, 3, 5, 2, 1])
# 按指定规则排序后,再抽取指定数量的元素
# 升序后抽取
rdd.takeOrdered(num=5)
# [1, 2, 3, 4, 5]
# 降序后抽取
rdd.takeOrdered(num=5, key=lambda x: -x)
# [10, 9, 7, 6, 5]6.takeSample
rdd = sc.parallelize(range(10))
# 随机抽取指定数量的元素
# 第1个参数,是否重复抽样
# 第2个参数,抽样数量
# 第3个参数,随机种子
rdd.takeSample(False, 5, 0)
# [7, 8, 1, 5, 3]
7.count
rdd = sc.parallelize(range(10))
# 查看元素数量
rdd.count()
# 108.sum
rdd = sc.parallelize(range(10))
rdd.sum() # 求和
rdd.max() # 最大值
rdd.min() # 最小值
rdd.mean() # 平均值
rdd.stdev() # 总体标准差
rdd.variance() # 总体方差
rdd.sampleStdev() # 样本标准差
rdd.sampleVariance() # 样本方差
rdd.stats() # 描述统计
# (count: 10, mean: 4.5, stdev: 2.8722813232690143, max: 9.0, min: 0.0)9.histogram
rdd = sc.parallelize(range(51))
rdd.count()
# 51
# 按指定箱数,分组统计频数
rdd.histogram(2)
# ([0, 25, 50], [25, 26])
# 第1组[0, 25): 25
# 第2组[25, 50]: 26
# ([0, 25, 50], [25, 26])
# 按指定区间,分组统计频数
rdd.histogram([0, 10, 40, 50])’
# ([0, 10, 40, 50], [10, 30, 11])10.fold
rdd = sc.parallelize(range(10))
# 按指定函数(add加法)对元素折叠
from operator import add
rdd.fold(0, add)
# 4511.reduce
rdd = sc.parallelize(range(10))
# 二元归并操作,如累加
# 逐步对两个元素进⾏操作
rdd.reduce(lambda x, y: x + y)
from operator import add
rdd.reduce(add)
# 4512.foreach
rdd = sc.parallelize(range(10))
# 对每个元素执行一个函数操作
# accumulator累加器
acc = sc.accumulator(value=0)
rdd.foreach(lambda x: acc.add(x))
acc.value
# 4513.collectAsMap
rdd = sc.parallelize([("a", 1), ("b", 2), ("c", 3)])
# 将RDD转换为字典
rdd.collectAsMap()
# {'a': 1, 'b': 2, 'c': 3}14.saveAsTextFile
rdd = sc.parallelize(range(5))
# 保存rdd为text文件到本地
# 如文件已存在, 将报错
rdd.saveAsTextFile("./data/rdd.txt")15.textFile
# 加载text文件
rdd = sc.textFile("./data/rdd.txt")
# 判断是否为空
rdd.isEmpty()
# False
rdd.collect()
# ['0', '1', '2', '3', '4']3.RDD——变换算子
import pyspark
from pyspark import SparkContext, SparkConf
import findspark
findspark.init()
conf = SparkConf().setAppName('test').setMaster('local[*]')
sc = SparkContext(conf=conf)- Transformation变换算子/转换操作
1.map
rdd = sc.parallelize(range(10))
rdd.collect()
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 对每个元素映射一个函数操作,如求平方
rdd.map(lambda x: x**2).collect()
# [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]2.filter
# 筛选数据,如筛选大于5的元素
rdd.filter(lambda x: x > 5).collect()
# [6, 7, 8, 9]3.flatMap
rdd = sc.parallelize(["hello world", "hello python"])
rdd.collect()
# flat展平
# ['hello world', 'hello python']
# 先以空格拆分为二维结构
rdd.map(lambda x: x.split(" ")).collect()
# [['hello', 'world'], ['hello', 'python']]
# 对每个元素映射一个函数操作
# 并将结果数据进行扁平化(展平)
rdd.flatMap(lambda x: x.split(" ")).collect()
# ['hello', 'world', 'hello', 'python']4.sample
rdd = sc.parallelize(range(10))
# 每个分区按比例抽样
# 第1个参数,是否重复抽样
# 第2个参数,抽样概率
# 第3个参数,随机种子
rdd.sample(False, 0.5, 666).collect()
# [1, 2, 3, 8]5.distinct
rdd = sc.parallelize([1, 1, 2, 2, 3, 3, 4, 5])
# 去重
rdd.distinct().collect()
# [4, 1, 5, 2, 3]6.subtract
a = sc.parallelize(range(10))
a.collect()
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
b = sc.parallelize(range(5, 15))
b.collect()
# [5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
# 差集,a-b
a.subtract(b).collect()
# [0, 1, 2, 3, 4]7.union
# 并集,a+b
a.union(b).collect()
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]8.intersection
# 交集
a.intersection(b).collect()
# [8, 9, 5, 6, 7]9.cartesian
a = sc.parallelize([1, 2])
b = sc.parallelize(["python", "pyspark"])
# 笛卡尔积
a.cartesian(b).collect()
# [(1, 'python'), (1, 'pyspark'), (2, 'python'), (2, 'pyspark')]10.sortBy
rdd = sc.parallelize([(1, 2, 3), (3, 2, 2), (4, 1, 1)])
# 按第3列排序,默认升序
rdd.sortBy(
keyfunc=lambda x: x[2],
ascending=True
).collect()
# [(4, 1, 1), (3, 2, 2), (1, 2, 3)]11.zip
rdd1 = sc.parallelize([1, 2, 3])
rdd2 = sc.parallelize(["python", "pandas", "pyspark"])
# 两个RDD必须具有相同的分区,每个分区元素数量相同
# 类似于python内置函数zip
rdd1.zip(rdd2).collect()
# [(1, 'python'), (2, 'pandas'), (3, 'pyspark')]12.zipWithIndex
rdd = sc.parallelize(["python", "pandas", "pyspark"])
# 将RDD和索引压缩, 类似于python内置函数enumerate
rdd.zipWithIndex().collect()
'''
0 python
1 pandas
2 pyspark
[('python', 0), ('pandas', 1), ('pyspark', 2)]
'''
lst = ["python", "pandas", "pyspark"]
for i, v in enumerate(lst):
print(i, v)
'''
0 python
1 pandas
2 pyspark
'''4.RDD——PairRDD变换算子
import pyspark
from pyspark import SparkContext, SparkConf
import findspark
findspark.init()
conf = SparkConf().setAppName('test').setMaster('local[*]')
sc = SparkContext(conf=conf)- PairRDD变换算子
- 包含key和value的RDD,类似python的字典
1.KeyBy
rdd = sc.parallelize(["a", "b", "c"])
# 创建一个键值对RDD
# 以函数返回值作为key,原有元素作为value
rdd.keyBy(lambda x: 1).collect()
# [(1, 'a'), (1, 'b'), (1, 'c')]2.lookup
rdd = sc.parallelize(
[("python", 1),
("python", 2),
("pandas", 3),
("pandas", 4)])
# 获取RDD的键
rdd.keys().collect()
# ['python', 'python', 'pandas', 'pandas']
# 获取RDD的值
rdd.values().collect()
# [1, 2, 3, 4]
dct = {"python": 1, "pandas": 3}
dct.keys()
# dict_keys(['python', 'pandas'])
dct.values()
# dict_values([1, 3])
dct.items()
# dict_items([('python', 1), ('pandas', 3)])
dct['python']
# 1
# 通过key访问value,动作算子
rdd.lookup("python")
# [1, 2]3.reduceByKey
rdd.collect()
# [('python', 1), ('python', 2), ('pandas', 3), ('pandas', 4)]
# 以key分组对value执行二元归并操作,比如求和
rdd.reduceByKey(lambda x, y: x+y).collect()
# [('python', 3), ('pandas', 7)]4.reduceByKeyLocally
# 以key分组并按指定函数合并value,返回python字典
from operator import add
dct = rdd.reduceByKeyLocally(add)
dct
# {'python': 3, 'pandas': 7}5.foldByKey
# 以key分组并按指定函数(add加法)合并value
# 类似reduceByKey(分组求和)
# fold折叠,必须传递zeroValue的初始值
from operator import add
rdd.foldByKey(0, add).collect()
# [('python', 3), ('pandas', 7)]6.combineByKey
# 以key分组按指定函数合并value,合并后返回列表
# createCombiner,将value转换为列表
# mergeValue,将value添加至列表
# mergeCombiners,将多个列表合并为一个列表
def to_list(x):
return [x]
def append(x, y):
x.append(y)
return x
def extend(x, y):
x.extend(y)
return x
rdd.combineByKey(to_list, append, extend).collect()
# [('python', [1, 2]), ('pandas', [3, 4])]7.subtractByKey
x = sc.parallelize([("a", 1), ("b", 2), ("c", 3)])
y = sc.parallelize([("a", 2), ("b", 2)])
# 按key求差集
x.subtractByKey(y).collect()
# [('c', 3)]8.groupBy
rdd = sc.parallelize(range(10))
# 将RDD转换为迭代器
iterator = rdd.toLocalIterator()
type(iterator)
# generator
# groupBy:以函数返回值分组合并,合并后返回迭代器
# 如奇数为一个迭代器,偶数为一个迭代器
rdd_new = rdd.groupBy(lambda x: x % 2).collect()
rdd_new
'''
[(0, <pyspark.resultiterable.ResultIterable at 0x241bc7b8820>),
(1, <pyspark.resultiterable.ResultIterable at 0x241bc2c2370>)]
'''
[[x, list(y)] for x, y in rdd_new]
# [[0, [0, 2, 4, 6, 8]], [1, [1, 3, 5, 7, 9]]]9.groupByKey
rdd = sc.parallelize(
[("python", 1),
("python", 2),
("pandas", 3),
("pandas", 4)])
# 以key分组合并value,合并后返回迭代器
rdd_new = rdd.groupByKey().collect()
[[x, list(y)] for x, y in rdd_new]
# [['python', [1, 2]], ['pandas', [3, 4]]]10.mapValues
rdd = sc.parallelize(
[("python", [1, 2]),
("pandas", [3, 4])])
# 对value应用一个函数操作,比如求和
rdd.mapValues(sum).collect()
# [('python', 3), ('pandas', 7)]11.groupBy+mapValues
rdd = sc.parallelize(range(10))
# 以函数返回值分组合并,合并后返回列表
# 如奇数为一个列表,偶数为一个列表
rdd.groupBy(lambda x: x % 2).mapValues(list).collect()
# [(0, [0, 2, 4, 6, 8]), (1, [1, 3, 5, 7, 9])]12.groupByKey+mapValues
rdd = sc.parallelize(
[("python", 1),
("python", 2),
("pandas", 3),
("pandas", 4)])
# 以key分组合并value为列表
rdd.groupByKey().mapValues(list).collect()
# [('python', [1, 2]), ('pandas', [3, 4])]
# 以key分组求value之和
rdd.groupByKey().mapValues(sum).collect()
# [('python', 3), ('pandas', 7)]
# 以key分组求value最大值
rdd.groupByKey().mapValues(max).collect()
# [('python', 2), ('pandas', 4)]13.countByKey
# 以key分组计数,返回字典
rdd.countByKey().items()
# dict_items([('python', 2), ('pandas', 2)])14.countByValue
rdd1 = sc.parallelize([(1, 1), (1, 1), (3, 4), (2, 1)])
rdd2 = sc.parallelize([1, 2, 2, 3, 3, 3])
# 如为键值对RDD,则以键值对(k-v)分组计数,返回字典
rdd1.countByValue().items()
# {(1, 1): 2, (3, 4): 1, (2, 1): 1}
# 如为单元素RDD,则以值(v)分组计数,返回字典
rdd2.countByValue().items()
# [(1, 1), (2, 2), (3, 3)]15.cogroup
x = sc.parallelize([("a", 1), ("b", 2), ("a", 3)])
y = sc.parallelize([("a", 4), ("b", 5), ("b", 6)])
# groupWith等价于cogroup(combine group)
# 以key分组合并value,合并后返回迭代器
# 先对两个RDD分别goupByKey,再对合并结果groupByKey
rdd = x.cogroup(y).collect()
[[x, [list(z) for z in y]] for x, y in rdd]
# [['a', [[1, 3], [4]]], ['b', [[2], [5, 6]]]]16.sortByKey
rdd = sc.parallelize(
[("python", 1),
("python", 2),
("pandas", 3),
("pandas", 4)])
# 按key排序
rdd.sortByKey().collect()
# [('pandas', 3), ('pandas', 4), ('python', 1), ('python', 2)]17.sampleByKey
fruit = sc.parallelize(["apple", "banana"])
number = sc.parallelize(range(10))
# cartesian笛卡尔积
rdd = fruit.cartesian(number)
rdd.collect()
'''
[('apple', 0),
('apple', 1),
('apple', 2),
('apple', 3),
('apple', 4),
('apple', 5),
('apple', 6),
('apple', 7),
('apple', 8),
('apple', 9),
('banana', 0),
('banana', 1),
('banana', 2),
('banana', 3),
('banana', 4),
('banana', 5),
('banana', 6),
('banana', 7),
('banana', 8),
('banana', 9)]
'''
# 以key分组按比例随机抽样
# withReplacement是否放回抽样
# fractions抽样比例
# seed随机种子
frac = {"apple": 0.3, "banana": 0.5}
rdd.sampleByKey(False, frac, 999).collect()
'''
[('apple', 1),
('apple', 4),
('apple', 5),
('apple', 7),
('apple', 8),
('banana', 0),
('banana', 1),
('banana', 2),
('banana', 4),
('banana', 5),
('banana', 8),
('banana', 9)]
'''18.flatMapValues
rdd = sc.parallelize([("a", [1, 2, 3]),
("b", [4, 5, 6])])
# 将value进行扁平化(展平),类似pandas的explode
rdd.flatMapValues(lambda x: x).collect()
# [('a', 1), ('a', 2), ('a', 3), ('b', 4), ('b', 5), ('b', 6)]19.join
age = sc.parallelize(
[("jack", 20),
("rose", 18),
("tony", 20)])
gender = sc.parallelize(
[("jack", "male"),
("rose", "female"),
("tom", "male")])
# 按key内连接
age.join(gender).collect()
# [('jack', (20, 'male')), ('rose', (18, 'female'))]20.leftOuterJoin
# 按key左连接
age.leftOuterJoin(gender).collect()
# [('jack', (20, 'male')), ('tony', (20, None)), ('rose', (18, 'female'))]21.rightOuterJoin
# 按key右连接
age.rightOuterJoin(gender).collect()
# [('tom', (None, 'male')), ('jack', (20, 'male')), ('rose', (18, 'female'))]22.fullOuterJoin
# 按key全连接
age.fullOuterJoin(gender).collect()
'''
[('tom', (None, 'male')),
('jack', (20, 'male')),
('tony', (20, None)),
('rose', (18, 'female'))]
'''5.RDD——分区
import pyspark
from pyspark import SparkContext, SparkConf
import findspark
findspark.init()
conf = SparkConf().setAppName('test').setMaster('local[*]')
sc = SparkContext(conf=conf)1.glom
rdd = sc.parallelize(range(10), 2)
rdd.collect()
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 将每个分区的元素转换为列表
rdd.glom().collect()
# [[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]2.coalesce
# hive: coalesce空值处理
rdd = sc.parallelize(range(10), 3)
rdd.glom().collect()
# [[0, 1, 2], [3, 4, 5], [6, 7, 8, 9]]
# 重置分区数量
# shuffle=True,增加至指定分区数量
# shuffle=False,减少至指定分区数量
rdd_new = rdd.coalesce(2, shuffle=False)
rdd_new.glom().collect()
# [[0, 1, 2], [3, 4, 5, 6, 7, 8, 9]]3.repartition
# 单元素RDD重置分区数量
rdd1 = sc.parallelize(range(10), 3)
# 键值对RDD重置分区数量
rdd2 = sc.parallelize(
[("a", 1),
("a", 2),
("a", 3),
("c", 4)])
# 增加分区数量,实际上调用coalesce(shuffle=True)
# 减少分区数量,实际上调用coalesce(shuffle=False)
rdd1.repartition(4).glom().collect()
# [[6, 7, 8, 9], [3, 4, 5], [], [0, 1, 2]]
# 按key打乱,相同key不一定在同一分区
rdd2.repartition(2).glom().collect()
# [[('a', 1), ('a', 3), ('c', 4)], [('a', 2)]]4.partitionBy
# 键值对RDD重置分区数量
rdd2 = sc.parallelize(
[("a", 1),
("a", 2),
("a", 3),
("c", 4)])
# 相同key一定在同一个分区
rdd2.partitionBy(2).glom().collect()
# [[('c', 4)], [('a', 1), ('a', 2), ('a', 3)]]5.mapPartitions
rdd = sc.parallelize(range(10), 2)
# 对每个分区分别应用一个函数,如求和
# 函数必须使用yield关键字(即生成器), 生成器返回迭代器
def func(x): yield sum(x)
rdd.mapPartitions(func).collect()
# [10, 35]6.mapPartitionsWithIndex
rdd = sc.parallelize(range(10), 2)
# 对每个分区分别应用一个函数,如求和
# 并且对每个分区添加索引
# 函数必须使用yield关键字(即生成器)
def func(i, x): yield i, sum(x)
rdd.mapPartitionsWithIndex(func).collect()
# [(0, 10), (1, 35)]7.repartitionAndSortWithinPartitions
rdd = sc.parallelize(
[(0, 1),
(3, 2),
(1, 3),
(0, 4),
(3, 5),
(2, 6)])
# 按指定函数进行重新分区repartition
# 并在每个分区内按key排序SortWithinPartitions
rdd_new = rdd.repartitionAndSortWithinPartitions(
numPartitions=2,
partitionFunc=lambda x: x % 2,
ascending=True)
rdd_new.glom().collect()
# [[(0, 1), (0, 4), (2, 6)], [(1, 3), (3, 2), (3, 5)]]8.foreachPartition
rdd = sc.parallelize(range(10), 2)
rdd.glom().collect()
# [[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
# 对每个分区分别执行一个函数操作
# 先对每个分区求和
# 再对每个分区的执行结果求和
acc = sc.accumulator(value=0)
def func(x): acc.add(sum(x))
rdd.foreachPartition(func)
acc.value
# 459.aggregate
aggregate函数
# aggregate(zeroValue, seqOp, combOp)
# zeroValue:必须传递初始值
# seqOp:先对每个分区分别执行一个函数操作
# combOp:再对每个分区的执行结果,执行另一个函数操作
# 求元素之和及元素个数
rdd = sc.parallelize(range(1, 10), 3)
print(rdd.glom().collect())
# 第1个分区的元素:[1, 2, 3]
# 第2个分区的元素:[4, 5, 6]
# 第3个分区的元素:[7, 8, 9]
seqOp = (lambda x, y: (x[0] + y, x[1] + 1))
combOp = (lambda x, y: (x[0] + y[0], x[1] + y[1]))
rdd.aggregate(
zeroValue=(0, 0),
seqOp=seqOp,
combOp=combOp)
# (45, 9)seqOp执行过程
# seqOp:先对每个分区分别执行一个函数操作
# 第1个分区的元素:[1, 2, 3]
# 第2个分区的元素:[4, 5, 6]
# 第3个分区的元素:[7, 8, 9]
seqOp = (lambda x, y: (x[0] + y, x[1] + 1))
x[0] + y:累计求和;x[1] + 1:累计计数
x等于zeroValue初始值
第1个分区的执行结果:(6, 3)
x=(0, 0), y=[1, 2, 3]
(0+1, 0+1):x与y的第1个元素
(1+2, 1+1):上一步结果与y的第2个元素
(3+3, 2+1):上一步结果与y的第3个元素
第2个分区的执行结果:(15, 3)
x=(0, 0), y=[4, 5, 6]
(0+4, 0+1):x与y的第1个元素
(4+5, 1+1):上一步结果与y的第2个元素
(9+6, 2+1):上一步结果与y的第3个元素
第3个分区的执行结果:(24, 3)
x=(0, 0), y=[7, 8, 9]
(0+7, 0+1):x与y的第1个元素
(7+8, 1+1):上一步结果与y的第2个元素
(15+9, 2+1):上一步结果与y的第3个元素combOp执行过程
# combOp:再对每个分区的执行结果,执行另一个函数操作
# 第1个分区的执行结果:(6, 3)
# 第2个分区的执行结果:(15, 3)
# 第3个分区的执行结果:(24, 3)
combOp = (lambda x, y: (x[0] + y[0], x[1] + y[1]))
x[0] + y[0]:累计求和,x[1] + y[1]:累计求和
x等于zeroValue初始值
第一步:zeroValue初始值与第1个分区的执行结果相加
x=(0, 0), y=(6, 3)
(0+6, 0+3)
第二步:上一步结果与第2个分区的执行结果相加
x=(6, 3), y=(15, 3)
(6+15, 3+3)
第三步:上一步结果与第3个分区的执行结果相加
x=(21, 6), y=(24, 3)
(21+24, 6+3)
# 最终结果
(45, 9)rdd = sc.parallelize(range(1, 10), 3)
rdd.glom().collect()
# [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# 求元素之和及元素个数
# seqOp:先对每个分区分别执行一个函数操作
# combOp:再对每个分区的执行结果,执行另一个函数操作
# zeroValue:必须传递初始值
# x累计求和,y累计计数
seqOp = (lambda x, y: (x[0] + y, x[1] + 1))
combOp = (lambda x, y: (x[0] + y[0], x[1] + y[1]))
# aggregate是动作算子
rdd.aggregate(
zeroValue=(0, 0),
seqOp=seqOp,
combOp=combOp)
# (45, 9)10.aggregateByKey
rdd = sc.parallelize(
[("orange", 1),
("orange", 2),
("banana", 3),
("orange", 4),
("banana", 5),
("banana", 6)], 2)
rdd.glom().collect()
'''
[[('orange', 1), ('orange', 2), ('banana', 3)],
[('orange', 4), ('banana', 5), ('banana', 6)]]
'''
# seqFunc:先对每个分区按key执行一个函数
# combFunc:再对每个分区的执行结果,按key执行另一个函数
# zeroValue:必须传递初始值
# 按key分组求value的最大值
# 高性能算子,执行效率高
rdd_new = rdd.aggregateByKey(
zeroValue=0,
seqFunc=lambda x, y: max(x, y),
combFunc=lambda x, y: max(x, y))
rdd_new.collect()
# [('orange', 4), ('banana', 6)]6.RDD——缓存
import pyspark
from pyspark import SparkContext, SparkConf
import findspark
findspark.init()
conf = SparkConf().setAppName('test').setMaster('local[*]')
sc = SparkContext(conf=conf)1.缓存的好处
# 什么缓存?
# 缓存是一种可以实现内存与CPU之间高速交换数据的存储器
# 工作原理: 当CPU要读取一个数据, 优先从缓存中查找, 找到就立即读取并发给CPU处理# 如果一个RDD被多个任务调用, 那么可以缓存到内存中, 提高计算效率
# 如果一个RDD后续不再被调用, 那么可以立即释放缓存, 避免资源浪费
2.缓存到内存
rdd = sc.parallelize(range(10000), 5)
rdd.cache()
# PythonRDD[1] at RDD at PythonRDD.scala:53
rdd.getStorageLevel()
# 常见的两种存储级别
# 第1种: 缓存到内存
# 第2种: 缓存到内存和磁盘
# StorageLevel(False, True, False, False, 1)
# 是否使用磁盘, False
# 是否使用内存, True
# 是否使用堆外内存, False
# - java虚拟机概念(jvm)
# - 堆外内存受操作系统管理
# - 堆内内存受jvm管理
# 是否以java反序列化格式存储, False
# - 序列化: 将对象转换为可传输的字节序列的过程
# - 反序列化: 将字节序列还原为对象的过程
# 备份数量, 1
# StorageLevel(False, True, False, False, 1)
rdd_cnt = rdd.count()
rdd_sum = rdd.reduce(lambda x, y: x+y)
rdd_mean = rdd_sum/rdd_cnt
print(rdd_mean)
# 立即释放缓存
rdd.unpersist()
# 4999.5
# PythonRDD[1] at RDD at PythonRDD.scala:533.缓存到内存和磁盘
rdd = sc.parallelize(range(10000), 5)
from pyspark.storagelevel import StorageLevel
# 缓存到内存和磁盘中, MEMORY_AND_DISK
# 如果内存存储不了, 其余部分存储至磁盘中
rdd.persist(StorageLevel.MEMORY_AND_DISK)
# 缓存到内存中
# 等价于rdd.cache()
# rdd.persist(StorageLevel.MEMORY_ONLY)
# PythonRDD[3] at RDD at PythonRDD.scala:53
rdd.getStorageLevel()
# StorageLevel(True, True, False, False, 1)
rdd_sum = rdd.reduce(lambda x, y: x+y)
rdd_cnt = rdd.count()
rdd_mean = rdd_sum/rdd_cnt
print(rdd_mean)
# 立即释放缓存
rdd.unpersist()
# 4999.5
# PythonRDD[3] at RDD at PythonRDD.scala:537.RDD——共享变量
import pyspark
from pyspark import SparkContext, SparkConf
import findspark
findspark.init()
conf = SparkConf().setAppName('test').setMaster('local[*]')
sc = SparkContext(conf=conf)1.广播变量
# 设置广播变量, 提高计算效率
rdd = sc.parallelize(range(10))
rdd.collect()
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
broad = sc.broadcast(100)
broad.value
# 100
rdd.map(lambda x: x+broad.value).collect()
# [100, 101, 102, 103, 104, 105, 106, 107, 108, 109]
# 立即释放
broad.unpersist()2.累加器-求和
rdd = sc.parallelize(range(10))
rdd.collect()
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
acc = sc.accumulator(0)
rdd.foreach(lambda x: acc.add(x))
acc.value
# 453.累加器求均值
rdd = sc.parallelize(range(10000))
# 累计求和
acc_sum = sc.accumulator(0)
# 累计计数
acc_cnt = sc.accumulator(0)
def func(x):
acc_sum.add(x)
acc_cnt.add(1)
rdd.foreach(func)
acc_sum.value/acc_cnt.value
# 4999.5
rdd.count()
# 10000
rdd.sum()
# 49995000
rdd.sum() / rdd.count()
# 4999.5













 3400
3400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









