
如何使用GPU运行TensorFlow
如何使用GPU运行TensorFlow

如何使用GPU运行TensorFlow
这里主要考虑如何让tensorflow和keras运行在GPU上:
1. 检查显卡类型和计算能力**
查看笔记本显卡型号,以及计算能力
下载个 GPU 查看器,名字为TechPowerUp GPU-Z
下载地址是:
https://www.techpowerup.com/download/gpu-z/
我的电脑显示是这样的:

我笔记本独立显卡产品型号是NVIDA GeForce MX250,但是核心型号是GP108。

确定对应显卡 GPU 的计算能力
去 NVIDIA 官网查看 https://developer.nvidia.com/cuda-gpus
不过我没有查到计算能力,只看到了相关产品参数https://www.geforce.com/hardware/notebook-gpus/geforce-mx250/features
2. 安装CUDA
下载地址:https://developer.nvidia.com/cuda-downloads
安装包有点大,下载慢,需要耐心等待。安装 cuda 的时候,会询问是否安装显卡驱动,说明 cuda 安装程序里包含了的显卡驱动;
建议先不要安装 cuda 里的显卡驱动,待安装完 cuda 后,执行例子程序,如果报错再检查显卡驱动是否正确,避免覆盖原来的显卡驱动。
安装完后执行 nvcc -V 检查
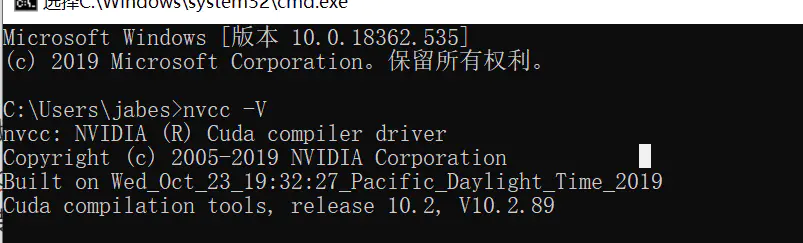
然后运行例子:
例子在C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\extras\demo_suite/deviceQuery.exe
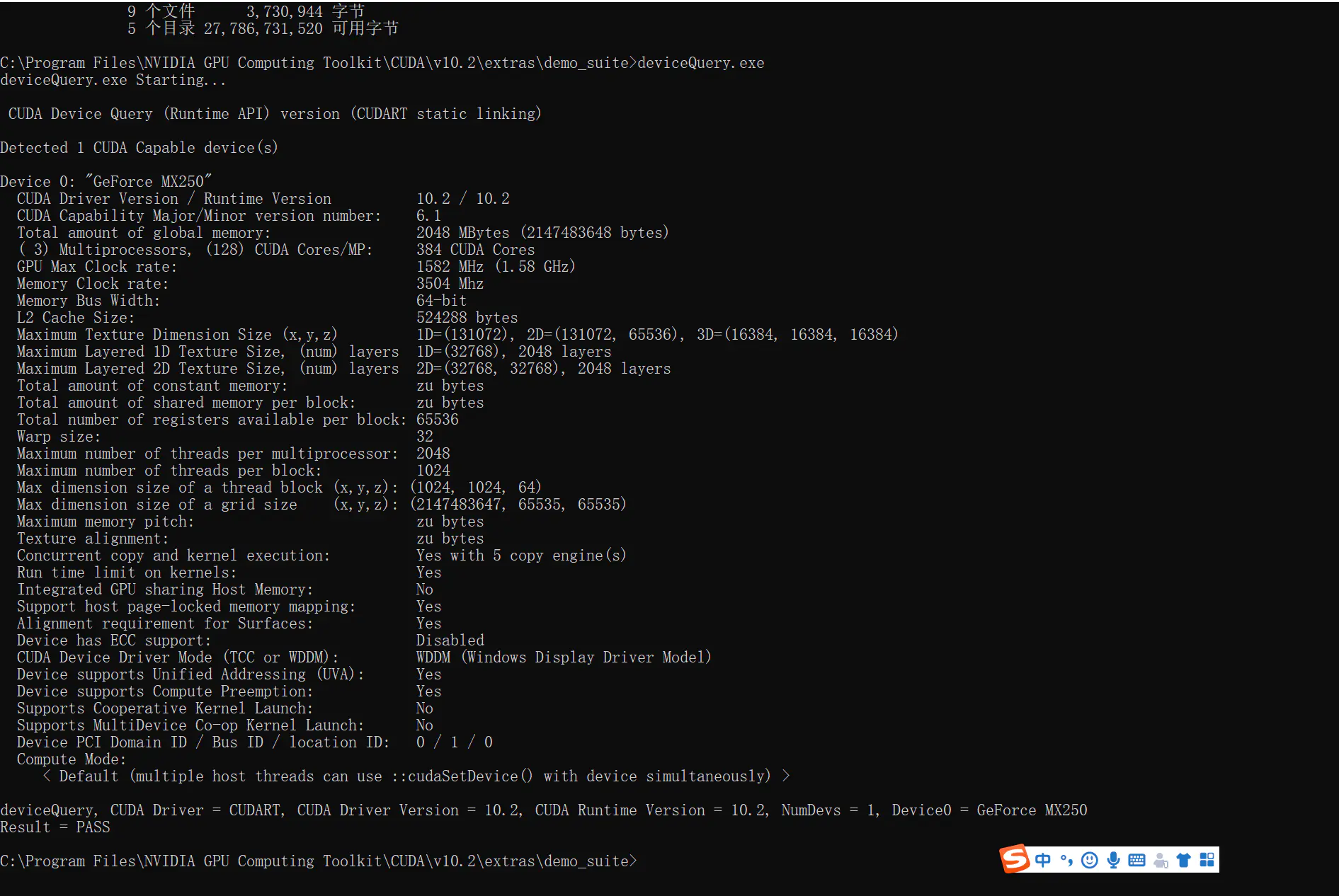
至此已经安装 cuda 成功
3. 安装cuDNN
cuDNN 是一个为了优化深度学习计算的类库,它能将模型训练的计算优化之后,再通过 CUDA 调用 GPU 进行运算,当然你也可直接使用 GUDA,而不通过 cuDNN ,但运算效率会低好多
cuDNN 下载地址:https://developer.nvidia.com/cudnn
下载过程会有一堆调查问卷,友好度不好!选择跟CUDA对应的版本 cuDNN
将文件解压,例如解压到D:\software\cuda
解压后有三个子目录:bin,include,lib。将bin目录(例如 D:\software\cuda\bin)添加到环境变量 PATH 中。或者将三个文件夹的内容拷贝到CUDA对应的目录即可。

4. 重新安装tensorflow
之前安装的tensorflow这样安装的pip install tensorflow==1.13.0,现在我换成了pip install tensorflow-gpu==1.15.0.
5. 测试代码
最后对GPU进行一下测试,使用如下代码:
#导入相关的库
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os
import time
from tensorflow.contrib.tensorboard.plugins import projector
import matplotlib.pyplot as plt
import numpy as np
#这里用slim这个API来进行卷积网络构建
slim = tf.contrib.slim
#定义卷积神经网络模型
#网络架构是卷积网络--最大池化--卷积网络--最大池化---flatten---MLP-softmax的全连接MLP
def model(inputs, is_training, dropout_rate, num_classes, scope='Net'):
inputs = tf.reshape(inputs, [-1, 28, 28, 1])
with tf.variable_scope(scope):
with slim.arg_scope([slim.conv2d, slim.fully_connected],
normalizer_fn=slim.batch_norm):
net = slim.conv2d(inputs, 32, [5, 5], padding='SAME', scope='conv1')
net = slim.max_pool2d(net, 2, stride=2, scope='maxpool1')
tf.summary.histogram("conv1", net)
net = slim.conv2d(net, 64, [5, 5], padding='SAME', scope='conv2')
net = slim.max_pool2d(net, 2, stride=2, scope='maxpool2')
tf.summary.histogram("conv2", net)
net = slim.flatten(net, scope='flatten')
fc1 = slim.fully_connected(net, 1024, scope='fc1')
tf.summary.histogram("fc1", fc1)
net = slim.dropout(fc1, dropout_rate, is_training=is_training, scope='fc1-dropout')
net = slim.fully_connected(net, num_classes, scope='fc2')
return net, fc1
def create_sprite_image(images):
"""更改图片的shape"""
if isinstance(images, list):
images = np.array(images)
img_h = images.shape[1]
img_w = images.shape[2]
n_plots = int(np.ceil(np.sqrt(images.shape[0])))
sprite_image = np.ones((img_h * n_plots, img_w * n_plots))
for i in range(n_plots):
for j in range(n_plots):
this_filter