mysql -- 递归查询所有子节点
背景
有个需求,查询一个文件中的所有子目录的文件及文件夹。
实现
1. 数据库设计
首先, 建立一张 t_files 表, 模拟文件树结构。
create table `t_files` (
id int auto_increment,
file_name varchar(100) default '',
file_type tinyint(4) default 0,
parent_id int null,
update_time timestamp null,
primary key(id),
unique key(file_name, parent_id)
);模拟数据:
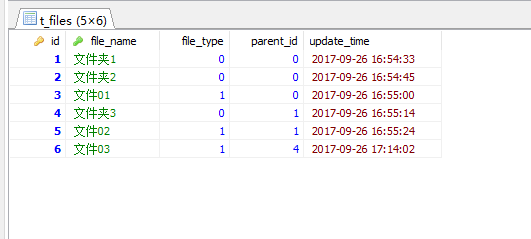
表中数据对应文件树结构为: 根目录下有两个文件夹, 1个文件; 文件夹1下有一个文件夹3和一个文件;而文件夹3下又有一个文件03。
需求: 如何用sql语句, 递归查询到文件夹1下的所有文件夹及文件?
2. 实现分析
思路:
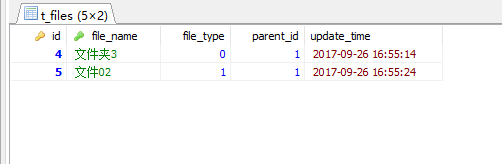
第一步: 先找到文件1下的子目录
select *from t_files where parent_id = 1;结果:
第二步: 找到子目录下文件夹下的子目录
这时候, 我们遇到了两个难点:
(1) 子目录下文件夹有多个, 怎么查询?
(2) 子目录下如果还有文件夹, 那么就需要一直循环下去, 什么时候结束?
解决方法:
(1) 多个同时查询, 我们需要用到mysql函数;
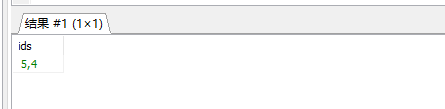
group_concat(): 多条记录合成一条记录
select group_concat(id) as ids from t_files where parent_id =1;结果:
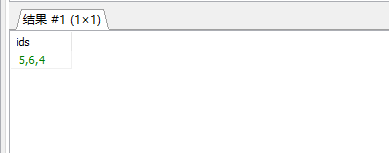
find_in_set(str, strlist) : 在多条记录中查询特定列
str 要查询的字符串
strlist 字段名 参数以”,”分隔 如 (1,2,6,8)
select group_concat(id) as ids from t_files where find_in_set(parent_id, '1, 4');结果:
(2) 循环如何结束, 需要用mysql FUNCTION 函数。
while id is null
– 自然语言
当所有子目录下没有文件夹就结束
3. mysql 实现完整语句
根据以上思路,我们可以通过以下mysql函数,完成递归查询。
DELIMITER //
CREATE FUNCTION `getChildLst`(rootId INT)
RETURNS varchar(1000) READS SQL DATA
BEGIN
DECLARE sTemp VARCHAR(1000);
DECLARE sTempChd VARCHAR(1000);
SET sTemp = '$';
SET sTempChd =cast(rootId as CHAR);
WHILE sTempChd is not null DO
SET sTemp = concat(sTemp,',',sTempChd);
SELECT group_concat(id) INTO sTempChd FROM t_files where FIND_IN_SET(parent_id,sTempChd)>0;
END WHILE;
RETURN sTemp;
END //
DELIMITER ;调动语句:
select *from t_files where find_in_set(id, getChildLst(1));结果:
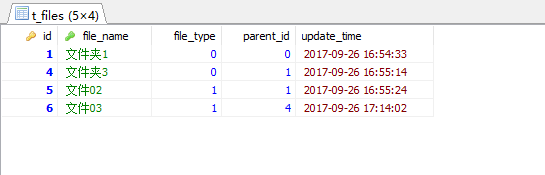
是的, 我们完成了需求: 查询到文件夹1下的所有文件夹及文件。
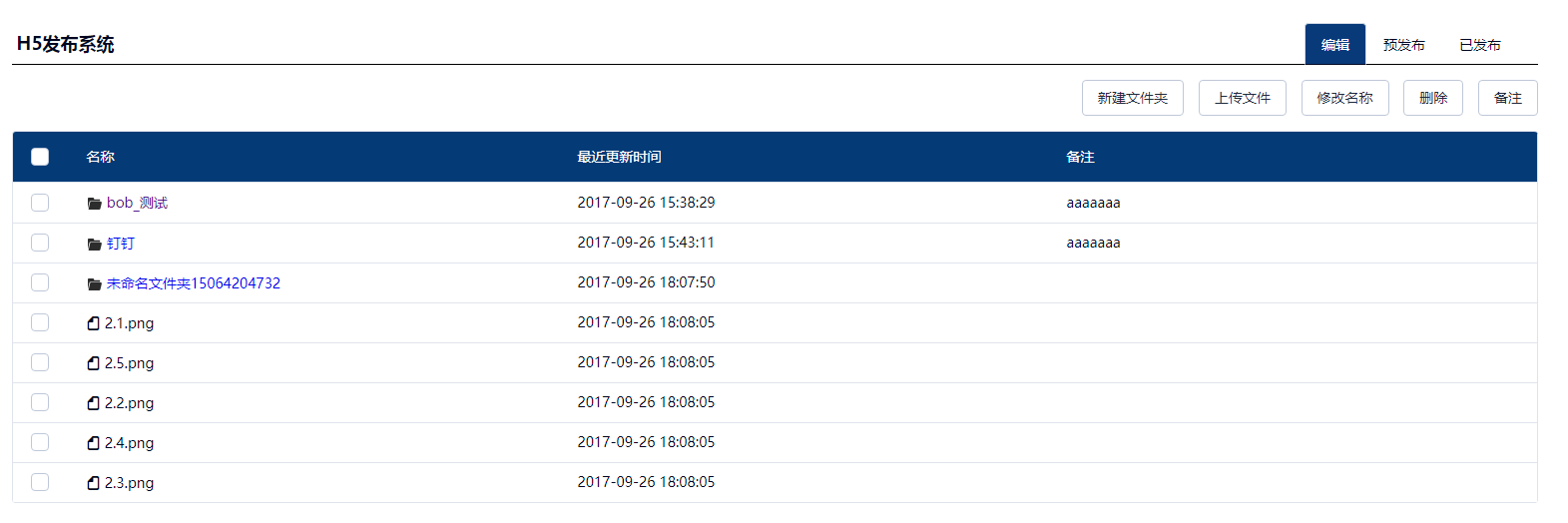
4. 效果图
我们应用它,实现了一个h5发布系统, 即可以在线操作文件。 效果如下:

总结
- 文件树结构, 数据库设计采用parent_id 这个字段, 来标识上一级目录。
- mysql 中 group_concat() 函数实现多条记录形成一条。
- mysql 中 find_in_set() 函数实现在集合中查询。
- mysql 中 使用自定义函数 function 可以实现较复杂的功能。
- 分享下,h5发布系统技术栈。
前端: vue2 + element + axios
后台: node + express + fs-extra + mysql
欢迎一起学习,交流。
智能推荐

Varnish部署cdn节点集群
varnish配置过程 实验环境: 三台虚拟机 server1(172.25.7.1)作为varnish主机,server2(172.25.7.2)与server3(172.25.7.3)均为apache主机 varnish 的安装部署 varnish主机上: 1.获取varnish安装包并下载安装包 配置文件: 2.修改varnish的监听端口 3.修改varnish配置文件 4.开启服务 se...
redis-cli常用命令
1、设置键值对 2、获取指定键的值 3、同时设置一个或多个键值对 4、同时获取一个或多个键的值 5、将指定键的数值+1(key不存在,则初始化为0,再+1) 6、将指定键的值-1(key不存在,则初始化为0,再-1) 7、指定键自增多少 8、指定键自减多少 9、获取所有key列表 10、删除指定键 11、设置指定键的过期时间(秒为单位) 12、查看key的过期时间 13、选择库 14、清空整个re...
pat-1052 Linked List Sorting (64bit) (25分)
pat-1052 Linked List Sorting (64bit) (25分) 参加晴神的《算法笔记》 大概说几点我遇到的问题以及总结: 1.pat链表内容的题目还是挺常规的,除非是工程应用或者leetcode的题目,它会使用指针实现数组。但是我做到现在,pat的题目都是:思量是链表,但是实现的是静态的方式。(xxx这里我会给一些链表的模板,还是很简单的。这里留一个空) 2.关于代码的一个小...
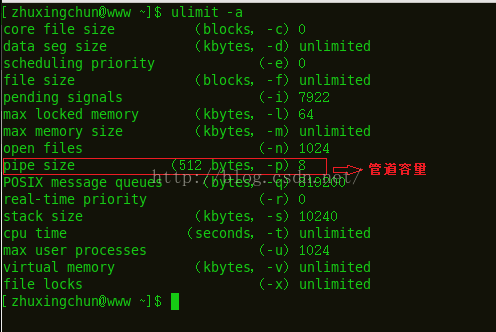
进程间通信——管道
原文地址:点击打开链接 一.管道容量:管道容量分为pipi capacity 和 pipe_buf .这两者的区别在于pipe_buf定义的是内核管道缓冲区的大小,这个值的大小是由内核设定的,这个值仅需一条命令就可以查到;而pipe capacity指的是管道的最大值,即容量,是内核内存中的一个缓冲区。pipe_buf: 命令:ulimit -a在终端输入该命令就会出现如下一表: 管道容量 siz...
“不会Linux,到底有多可怕?”高级程序员:这是必学技能!你说呢?
点击上方“Python大本营”,选择“置顶公众号” 最近我们发现,有很多程序员在CSDN博客发帖讨论:程序员是否需要学习Linux。 关于这个问题,其实答案很简单:这是程序员的必备技能。 为什么这么说? 1)应用广泛:回想下你用的各种软件、网站,比如:淘宝,用 QQ、微信等,其实这些软件和服务的背后,都是成千上万的 Linux 系统在支撑。 2)求职...
猜你喜欢

Java 5行代码搞定Excel导入导出
Java 5行代码搞定Excel导入导出 场景 使用 创建表格映射对象 导出演示 导入演示 引入 maven github 场景 在工作中,导出Excel的场景经常出现,比如管理后台导出的功能、批量订正数据库等,在这些场景中的表格数据往往对应数据库的一条记录,表格格式十分简单。但是,类似导入导出都要用不同的代码实现。产品经常给笔者一个Excel表格数据,导入到数据库。每次都要写一堆功能、流程类似的...
python学习——Anaconda与PyCharm
一、Anaconda与Pycharm简述 Anaconda是一个用于科学计算的Python发行版,核心功能是包管理和环境管理,可以很方便地解决多版本python并存、切换以及各种第三方包安装问题。 PyCharm是一种Python IDE,为用户提供IDE开发环境,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完...

jdbc总结3-以类加载的方式注册驱动
先看不用类加载的方式注入给数据库注册驱动: 这里两条语句实现两个功能: 1,创建一个com.mysql.jdbc.Driver类的对象 2,把这个对象传给DriverManager.registerDriver()这个方法 有没有办法把这两个操作合成一步?答案是有。 在jdbc驱动jar包下的driver类里面有一个静态代码块 部分代码: 在这个静态代码块里面执行了两个操作 1,创建一个com.m...
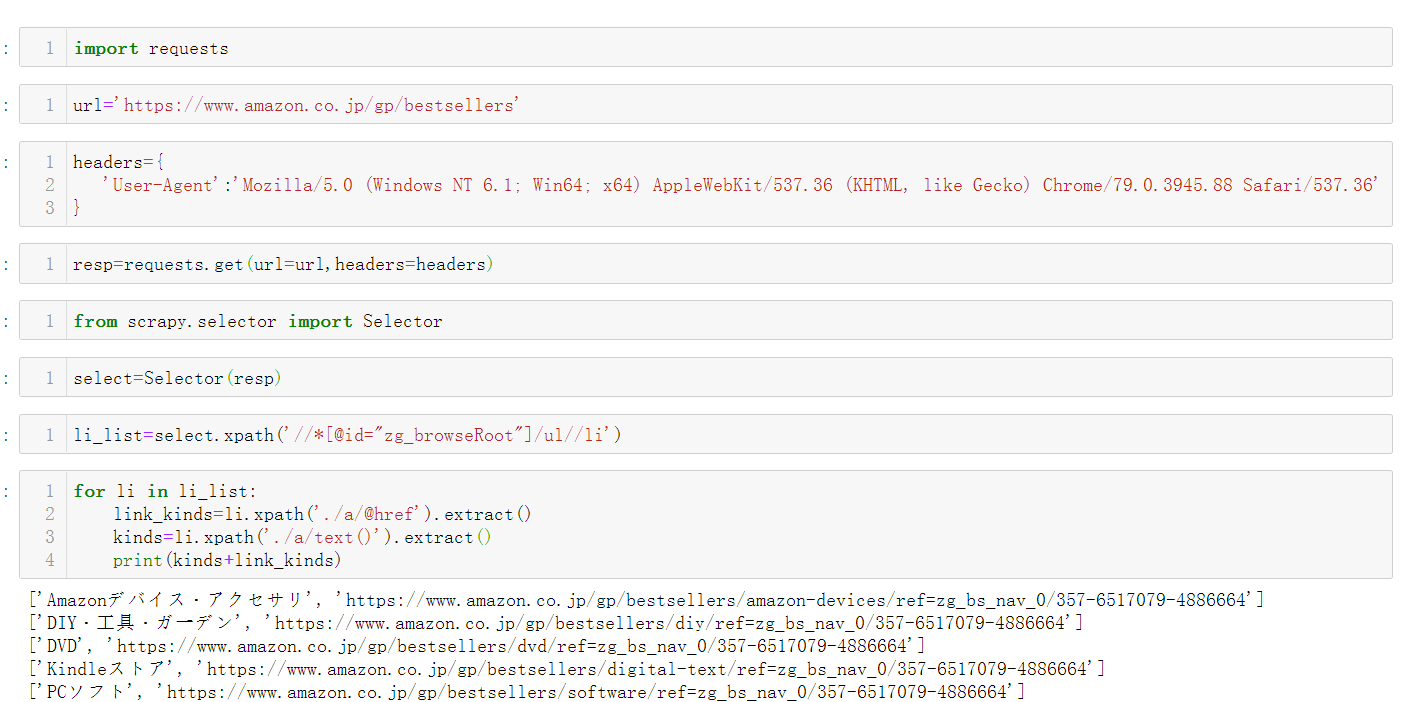
爬取亚马逊bestsellers首页的链接
为了方便构造小类目的链接,你的首先知道大类目的链接, 比如你 知道了大类名称之后,在其的小类目的id直接凭借到其后面就可了 1.代码如下: 2.另外还有一种解析为xpath的包效果一样的,,...

elasticsearch安装head插件
elasticsearch head插件是一个入门级的elasticsearch前端插件; 前提条件: 安装好nodejs 和git 使用git下载head插件 配置elasticsearch,允许head插件访问 进入elasticsearch config目录 打开 elasticsearch.yml 最后加上 测试: 启动elasticsearch,再进入head目录,执行npm run s...