SQL_DISTINCT 语句详细用法
一 测试数据构建
二 基本使用(单独使用)
三 聚合函数中的DISTINCT
下面全部是在MySQL 的环境下进行测试的!!!!!
一 测试数据构建
数据表 跟 数据
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for test_distinct
-- ----------------------------
DROP TABLE IF EXISTS `test_distinct`;
CREATE TABLE `test_distinct` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`province` varchar(255) DEFAULT NULL,
`city` varchar(255) DEFAULT NULL,
`username` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=gbk;
-- ----------------------------
-- Records of test_distinct
-- ----------------------------
INSERT INTO `test_distinct` VALUES ('1', 'BJ', 'BJ', 'houchenggong');
INSERT INTO `test_distinct` VALUES ('2', 'LN', 'DL', 'zhenhuasun');
INSERT INTO `test_distinct` VALUES ('3', 'LN', 'DL', 'yueweihua');
INSERT INTO `test_distinct` VALUES ('4', 'BJ', 'BJ', 'sunzhenhua');
INSERT INTO `test_distinct` VALUES ('5', 'LN', 'TL', 'fengwenquan');
INSERT INTO `test_distinct` VALUES ('6', 'LN', 'DL', 'renquan');
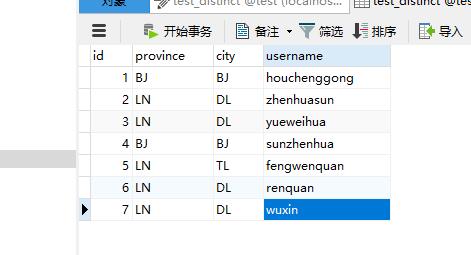
INSERT INTO `test_distinct` VALUES ('7', 'LN', 'DL', 'wuxin');样例数据
二 基本使用(单独使用)
介绍
distinct一般是用来去除查询结果中的重复记录的,而且这个语句在select、insert、delete和update中只可以在select中使用,
具体的语法如下:
select distinct expression[,expression...] from tables [where conditions];
这里的expressions可以是多个字段。
示例:
只能在SELECT 语句中使用,不能在 INSERT, DELETE, UPDATE 中使用
2.1 只对一列操作
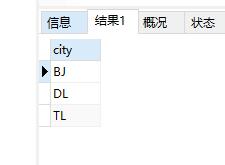
对一列操作,表示选取该列不重复的数据项,这是用的比较多的一种用法
测试数据
SELECT DISTINCT city FROM test_distinct;
2.2 对多列操作
对多列操作,表示选取 多列都不重复的数据,相当于 多列拼接的记录 的整个一条记录 , 不重复的记录。
测试数据:
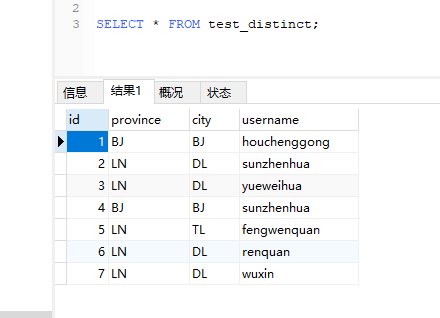
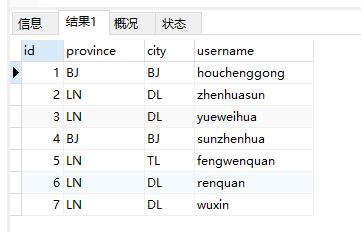
SELECT DISTINCT province, city FROM test_distinct;
结果:

注意:
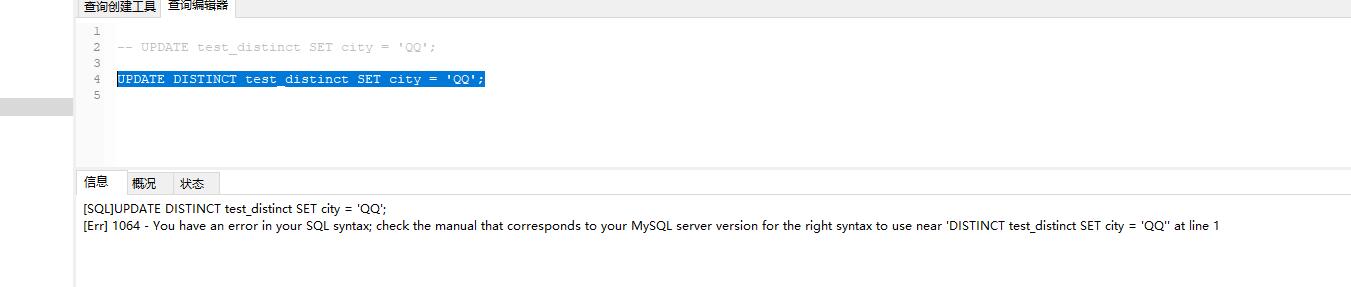
1. DISTINCT 必须放在第一个参数。
错误示例:

2.DISTINCT 表示对后面的所有参数的拼接取 不重复的记录,相当于 把 SELECT 表达式的项 拼接起来选唯一值。
测试数据:
SELECT DISTINCT province,city FROM test_distinct;
期望值: 只对 第一个参数 province 取唯一值。
province city
BJ BJ
LN DL
Record LN(province), TL(city) 被过滤掉,实际上
实际值:
解决方法:使得DISTINCT 只对其中某一项生效
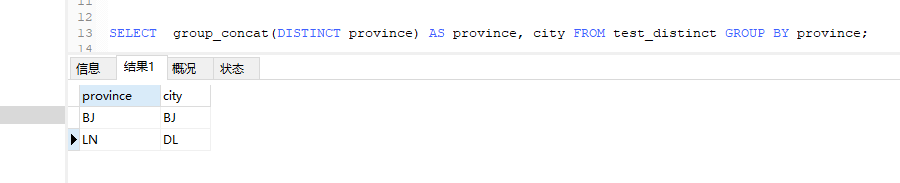
方法一: 利用 group_concat 函数
SELECT group_concat(DISTINCT province) AS province, city FROM test_distinct GROUP BY province;
方法二: 不利用DISTINCT , 而是利用group by (我认为第一种方法 其实就是 第二种方法, 第一种方法也就是第二种方法)
SELECT province, city FROM test_distinct GROUP BY province;

最后,比较下这两种方法的执行效率,分别EXPLAIN 一下。
方法一
EXPLAIN SELECT group_concat(DISTINCT province) AS province, city FROM test_distinct GROUP BY province;

方法二
EXPLAIN SELECT province, city FROM test_distinct GROUP BY province;

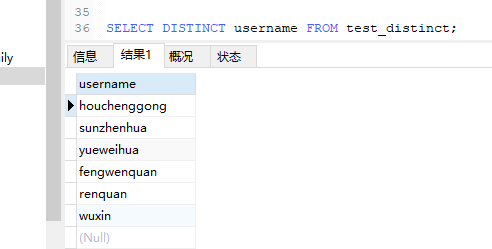
2.3 针对NULL的处理
distinct对NULL是不进行过滤的,即返回的结果中是包含NULL值的。
测试数据:

SELECT DISTINCT username FROM test_distinct;
2.4 与ALL不能同时使用
默认情况下,查询时返回所有的结果,此时使用的就是all语句,这是与distinct相对应的,如下:
测试数据:
SELECT ALL province, city FROM test_distinct;

2.5 与distinctrow同义
select distinctrow expression[,expression...] from tables [where conditions];
三 聚合函数中的DISTINCT
在聚合函数中DISTINCT 一般跟 COUNT 结合使用。
效果与 SELECT SUM (tmp.tmp_ct) FROM ( SELECT COUNT(name) AS tmp_ct GROUP BY name ) AS tmp 类似
但不相同 !!, COUNT 会过滤NULL , 而 第二种方法不会!!!!
示例:
测试数据:
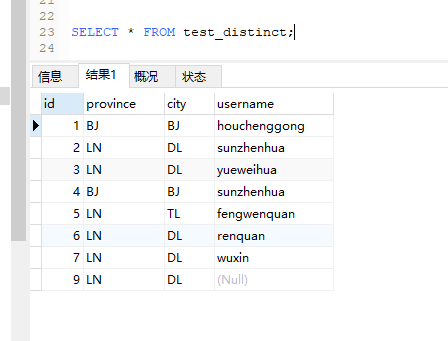
SELECT COUNT(DISTINCT username) FROM test_distinct;

注意 COUNT( ) 会过滤掉为NULL 的项
再用 GROUP BY 试一下
SELECT SUM(tmp.u_ct) FROM (SELECT COUNT(username) AS u_ct FROM test_distinct GROUP BY username) AS tmp;

我们在子查询中调查一下:
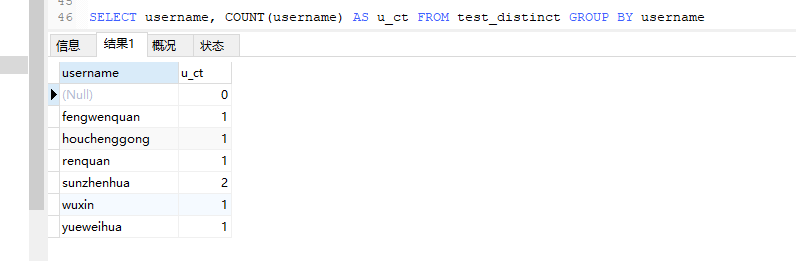
SELECT username, COUNT(username) AS u_ct FROM test_distinct GROUP BY username
智能推荐

对URL传递的参数进行编码和解码
一 编码部分 1 代码 2 运行结果 单击图片,地址栏显示:http://localhost/test/24/5/index.php?picname=%27%C7%E0%C4%EA%B8%E8%CA%D6%B4%F3%C8%FC%27 说明编码成功! 二 解码部分 1、代码 2、运行结果 查看图片附件...
Spark应用 —— 快速构建用户推荐系统
大数据一个重要的应用是预测用户喜好,例如相关广告的推送、相关产品的推荐、相关图书电影的推荐等。这里我们使用Spark的机器学习来展示如何进行预测,并基于此快速构建一个电影评分及推荐应用。 找到文件 定义数据架构 载入数据并缓存 快速浏览一下数据结构 平均分最高的电影 结果类似于 有500条以上评价平均分最高的电影 协作过滤 协作过滤是一种利用用户整体(协作)偏好信息来进行自动预测的方法。它基于这样...

python爬虫从入门到放弃(五)安装selenium并学习
安装selenium selenium 是一个web的自动化测试工具,其优点有 免费,也不用再为**QTP而大伤脑筋 小巧,对于不同的语言它只是一个包而已,而QTP需要下载安装1个多G 的程序。 这也是最重要的一点,不管你以前更熟悉C、 java、ruby、python、或都是C# ,你都可以通过selenium完成自动化测试,而QTP只支持VBS 支持多平台:windows、linux、MAC ...

Codeforces Round #635 (Div. 2)D+Codeforces Round #633 (Div. 2)D
D. Xenia and Colorful Gems time limit per test3 seconds memory limit per test256 megabytes inputstandard input outputstandard output Xenia is a girl being born a noble. Due to the inflexibility and ha...

使用AES算法对文件进行加密解密(JAVA+Eclipse)
一、项目中引用第三方类库的方法 Bouncy Castle类库的用法(如何在自己的项目中使用第三方类库) 1)手动配置 将.jar,src,javadoc拷到项目目录下 项目名,右键选build path-configure build path &...
猜你喜欢

Linux基本命令(CentOS7)
Linux终端基本命令(CentOS7) 文件与目录管理常用命令 重启与关机 用户管理类(user) 创建和删除操作(touch、mkdir、rm) 拷贝和移动文件(cp、mv) 查看文件内容(cat、less、grep) 将文本文件的内容加以排序(sort) 查找文件(find) 查看日志信息(head、tail) 用户权限(chmod) 打包和压缩(tar、zip) yum命令 VI编辑器 进...

Spring Cloud同步场景分布式事务怎样做?试试Seata
作者简介: 陶陶老师 10年后端工作经验, 专注Java、SpringBoot、SpringCloud、分布式系统/微服务、中间件等领域。 公众号:陶陶技术笔记 一、概述 在微服务架构下,虽然我们会尽量避免分布式事务,但是只要业务复杂的情况下这是一个绕不开的问题,如何保证业务数据一致性呢?本文主要介绍同步场景下使用Seata的AT模式来解决一致性问题。 Seata是 阿里巴...

【.Net Core】单元测试项目的迁移
参考 将 .NET Framework 库移植到 .NET Core 从 .NET Framework 移植到 .NET Core 的概述 .NET 可移植性分析器 一、Dotnet-Try-Convert 试着用 dotnet-try-convert 转换项目,出现如下错误 参考GUID列表,应该是不支持测试项目直接使用该工具迁移 Visual Studio项目类型GUID的列表 所以比较遗憾,...

方法执行内存分析
方法执行内存分析 java方法在执行过程中,内存在JVM中是如何分配。如何变化的。 方法只定义不调用,就不运行,不会在JVM中分配分配方法运行所需要的内存空间。 在JVM内存划分中,主要有三个内存空间: 方法区内存,堆内存,栈内存 栈数据结构 栈,stack,是一种数据结构,反映的是数据的存储形态,数据结构是独立的一门学科 方法执行时代码片段和执行过程的内存 方法代码片段存在于方法区当中,属于.c...

设计模式之创建型模式
创建型模式 简单工厂模式 描述:通过工厂对象来决定创建哪一种产品的实例。 方式一:继承 注:子类可以向上转型 (用子类去实例化父类) 方式二:实现接口 注:实例化接口类返回所需产品 情景: 1.一个类不知道它创建的类 2.一个类希望由它的子类来指定它所创建的对象 3.希望使用者不知道究竟是哪个类进行了实例化。(如寄包裹,邮递员不知道内容) 简单工厂模式 注:一个JAVA类文件可以有多各类,但只能有...