






展开全部
创建set的copyiterator方法:
Set set = new HashSet();
Iterator it = set.iterator();
while(it.hasNext())//判断是否有下一个
it.next()取出bai元素。
以上du方法便是从Set集合中zhi取出数据。
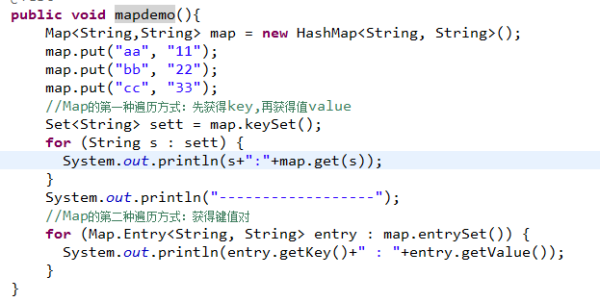
扩展资料dao:
Java中使用Set接口描述一个集合(集合不允许有“重复值”,注意重复的概念),集合Set是Collection的子接口,Set不允许其数据元素重复出现,也就是说在Set中每一个数据元素都是唯一的。Set接口定义的常用方法如下:
1、size() 获取Set尺寸(即Set包含数据元素的总数)。
2、 add(Object obj) 向Set中添加数据元素obj。
3、remove(Object obj) 从Set中移除数据元素obj。
4 、contains(Object obj) 判断当前Set中是否包含数据元素obj,如果包含返回true,否则返回false。
5、 iterator() 将Set装入迭代器。














 2887
2887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









