
R语言基础-向量的保姆式教程

R语言 向量知识点总结
一、写在前言
本文,是对R语言的向量的总结,适合新手入门,老手巩固总结,顺便强调一下R语言中向量的重要性,向量被誉为R语言中的战斗机。希望你阅读完本文后,能对向量有一个新的理解!文章内容有点多,这是因为我把一些晦涩难懂的点,都说得比较详细。好了,just enjoy it :)
二、创建一个"标量"
r_int<-5L #interger 创建一个整数型标量。
r_double<-5 #double 创建一个浮点型标量
r_double2<-5.5 #double 创建一个浮点型标量
r_string<-"hello,R!" #character 创建一个字符串型标量
r_complex<-2+1i #complex 创建一个复数型标量
r_logical<-TRUE #logical 创建一个逻辑型标量当然,创建了一个整数型标量,可以理解为这个标量的数据类型是整数型。
下面来解析一下,当我创建了这个标量 r_int<-5L的时候,R中发生了什么。
首先,R会创建出标量 5L,然后通过赋值符 <-,将标量 5L在内存中的地址,绑定到变量r_int上。
先介绍一个函数,typeof(),查看变量是啥类型的函数,比如,typeof(r_int)
现在来说一下上面创建标量细节。
- 创建第一个整数型标量5L,为什么要在5后面加个大写字母L,这是因为R会将你手动输入的整数数字默认给你转成浮点型(double)。
- 创建字符串变量的时候,虽然可以使用单引号或者双引号,但是我建议,使用双引号。
- 创建复数型标量的时候,即使虚数部分为1,也不可以省略这个1,比如r_complex<-2+1i,这个1不可省略。
- 创建逻辑型标量的时候,注意,必须要全部大写,TRUE或者FALSE,或者使用缩写T或者F,但是为了直观性,建议使用前者。
- 同时,我建议,赋值符号,使用"<-",而不是使用等号"=",因为这是R中赋值符号的标准写法,使用赋值符号的时候要特别注意,千万别少打个横杠!
三、创建一个向量
现在来说一下,开始上一节的标题中,我为何给"标量"打上引号,这是因为,在R中,严格来说,并不存在标量,标量,其实是被当做特殊的一元向量来处理的。所以在上一节中,我们已经创建过一个向量啦!
下面,我们来介绍,如何创建多元向量。多元向量大家应该懂吧。。。就是向量中的元素有多个。
- 使用函数c()来创建
函数c(),单词concatenate的缩写,意为将不同的对象组合为向量或者列表。
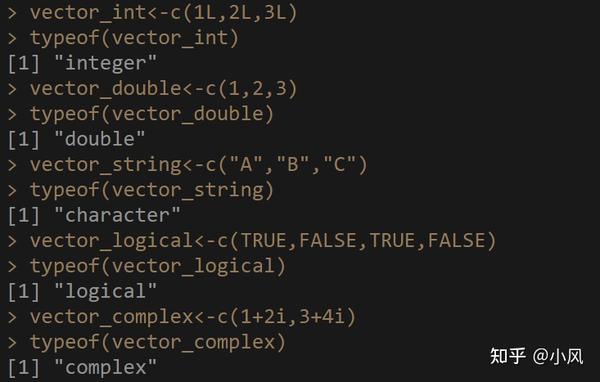
vector_int<-c(1L,2L,3L) #创建整数型向量
vector_int2<-1:3 #创建整数型向量 1:3表示 1,2,3
vector_double<-c(1,2,3) #创建浮点型向量,动手typeof(vector_double)查看下元素的数据类型吧!
vector_string<-c("A","B","C") #创建字符串型向量。
vector_logical<-c(TRUE,FALSE,TRUE,FALSE) #创建逻辑型向量
vector_complex<-c(1+2i,3+4i) #创建复数型向量。
v<-c(vector_int,vector_string)#这种套娃操作,会将vector_int和vector_string中的元素,都加入到向量v中。

- 使用n:m来创建整数型向量
r_int<-1:5 #创建一个整数型向量。
以上创建的,都是没有名字的向量,现在我们来创建一下,带名字的向量。 - 创建带有名字的向量
v_1<-c(name="james",age=36)
names(v_1) #查看向量的名字,如果该向量是无名向量,则返回NULL
二者,没有很大区别,大家不必担心。
四、向量元素类型的自动转换机制
也许,你没听说过这个,很正常,这是我自己总结的。
现在,我要跟大家说一下向量的一个重要特性,那就是,向量的元素,必须为同一类型!!
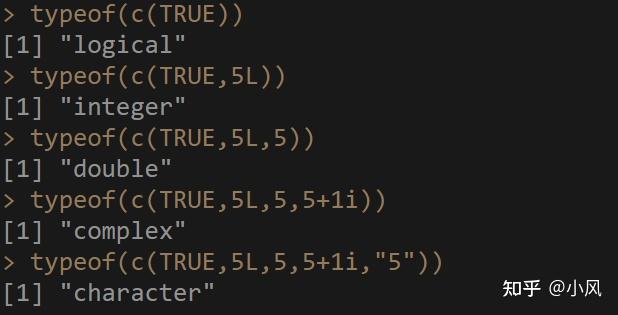
也许你和我一样好奇,我先创建个v4<-c("hello",5),回车,哈哈哈,没有报错!
然后,你可能会对上面那句话 “向量的元素,必须为同一类型”,产生质疑。
现在,我们来看看,刚才这个创建的向量v4

细心的你,一定发现了,这个5,从数值型,被转换成了字符串。
没错,这就是R语言向量的自动转换机制,那么这种转换的优先级是啥呢?
如果你的向量中有不同类型的元素,自动转换优先级:字符串>复数型>浮点型>整数型>逻辑型
通俗点理解,就是假如你的向量里,有不同类型的元素,如果有字符串元素,那么,所有的元素类型都会变成字符串类型。
然后依次类推,下面,来通过一个简单的小案例来看看吧!
我依次加入不同类型的元素,可以看到向量的元素类型,在发生如下改变。

现在你应该明白了,向量的元素类型,必须为同一类型,这句话的含义了吧。这就是向量的自动转换!
明白了上面这种自动转换机制后,来看看我以前踩过的坑。初学者可先不做了解,等以后学到dataframe再来查看即可。
提前用一下data.frame函数,以及rbind函数。
>df<-data.frame(name=c("a","b"),score=1:2) #创建一个dataframe数据框。
>df #查看一下df,相信你没有忘记我的那句话,应该知道这name,score向量的元素是啥类型了吧。
name score
1 a 1
2 b 2
>typeof(df$score) #来查看一下score列的类型,interger类型,nice,符合预期。
[1] "integer"
>df2<-rbind(df,c("c",80)) #利用rbind给df,再加一行。
>df2
name score
1 a 1
2 b 2
3 c 80
一切似乎很正常,看不出什么猫腻。
但是,事实真的是这样吗?
现在再来查看一下score列的类型,卧槽,咋变成字符串类型了?
>> typeof(df2$score)
[1] "character"
现在明白了吗,利用rbind添加的那一行c("c",80),向量对不同类型元素的自动转换,将浮点型80转换成了字符串类型"80"
然后字符串类型元素"80",加入到原来的向量score中,由于向量元素的自动转换,其他的整型元素都被转换成了字符串类型!
你说,向量的这种自动转换,你不明白的话,可不可怕?
尤其是在画图、以及计算的时候,你稍不注意,就会出错。五、向量元素类型的判断函数
这个没啥好说的,函数对向量进行判断,返回逻辑值TRUE或者FALSE。
is.character(x) #判断向量x是否为字符串型向量。
is.interger(x) #判断向量x是否为整数型向量。
is.numeric(x) #判断向量x是否为数值型型向量。整数型和浮点型可统称为数值型
is.double(x) #判断向量x是否为浮点型向量。
is.logical(x) #判断向量x是否为逻辑型向量。
is.complex(x) #判断向量x是否为复数型向量。初学向量的时候,心中一定要有杆秤,这个向量元素类型,是啥呢?
六、向量元素类型的显示转换函数
这些函数,用于向量元素类型强制转换。但是,前提是,被转换的向量和要转换成的向量间的元素,要能进行转换。
举个例子,你能把c("A")转换成数值型吗?,显然是不能。
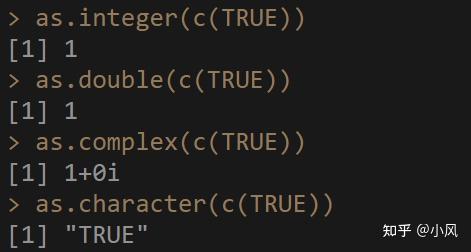
强制转换类型,也与向量元素的自动类型转换有联系。低优先级的,无条件可以转换成高优先级的。
但是高优先级的,强制转换成低优先级的时候,需要元素间确实能够进行转换!!
优先级从高到低:字符串>复数型>浮点型>整数型>逻辑型
as.character(x) #将向量x转换成字符串类型向量。
as.complex(x) #将向量x转换成复数型向量。
as.double(x) #将向量x转换成浮点型向量。
as.interger(x) #将向量x转换成整数型向量。
as.numeric(x) #将向量x转换成数值型向量。
as.logical(x) #将向量x转换成逻辑型向量。下面来看一下,从低优先级转换到高优先级的过程,可以无条件正确转换。

但是你要从高优先级转换到低优先级的时候,就需要考虑到,元素间是否能互转了。
这里留给大家自己测试吧~
七、向量运算间的循环补齐
向量运算间的循环补齐,就是指短的向量,R会复制它的元素,来补齐到和长的向量相同的长度。
注意,下面所说长度相同的向量,意思就是元素个数相同的向量。
下面看下长度相同的向量间进行运算,此时就是向量对应位置的元素进行操作。
v1<-c(1,2)
v2<-c(3,4)
v1-v2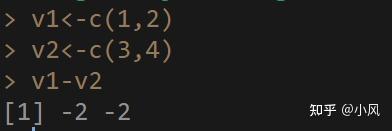
下面再看下不同长度的向量间的元素如何进行运算。
longv<-c(7,5,2,4,3,9,6) #长向量
shortv<-c(1,2) #短向量
longv-shortv #长向量减去短向量,会得到什么?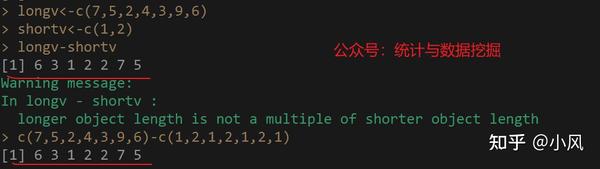

没有报错,但是给出了警告信息,这就是向量运算的循环补齐,下面我们来了解下。
现在 长向量longv<-c(7,5,2,4,3,9,6) 减去 短向量shortv<-c(1,2),究竟该如何循环补齐呢?
此时,我们可以这样理解。长向量的元素个数 7 除 短向量的元素个数2,结果就是商3,余1
即 7/2,商3,余数为1.。。。这个应该很好理解吧。
此时,短向量会根据上面的商为3,来复制自身的短向量3次,得到新向量c(1,2,1,2,1,2)
然后,短向量会根据上面的余数为1,来取出自身前1个元素,即元素1,加入到上面循环得到的新向量c(1,2,1,2,1,2)中,
然后就这样,循环补齐后的向量就为c(1,2,1,2,1,2,1)
然后,再开始进行运算:c(7,5,2,4,3,9,6)-c(1,2,1,2,1,2,1)
八、向量化运算符
这一节,初学者可先不了解,后续再学习即可。
以下图片来源《R语言编程艺术》P34-P36












九、向量如何索引元素
9.1 整数索引
#R语言中,向量的索引起始位置是从1开始,而不是从0开始的。如果索引位置0的元素,没有返回值。
#先来创建一个浮点型向量。double vector
dbv<-c(1,5,2,4,6,8,5)
#正整数索引,返回对应位置的值,如果该位置没有值,则返回NA
dbv[1] 索引得到元素1
dbv[c(1,3)] 索引位置为1,3的元素,得到1,2
dbv[8] 由于该位置没有元素,返回NA
#负整数索引,排除掉不想要的元素。
dbv[c(-1,-2)] 排除掉位置1,2的元素,即排除掉元素1,5,返回元素2,4,6,8,5
dbv[-c(1,2)] 同上
#注意,不可以在同一个整数索引中,同时使用正、负整数索引。
#假如你想排除第一个位置的元素后,索引出第二个位置的元素。
#你运行dbv[c(-1,2)],这样就会报错。
#正确的做法是,先排除掉第一个,然后从返回的向量中,由于第一个元素被删掉了,原来的第二个元素,就变成了第一个。
dbv[c(-1)][1]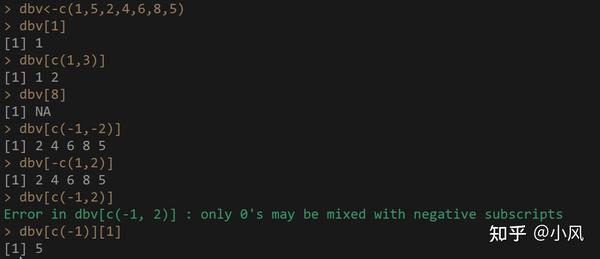

9.2 逻辑索引
逻辑索引,只会索引出原向量对应位置为TRUE的元素
#举个例子,本例使用这个向量 lglv logical vector
lglv<-c(1,3,5)
logical_index<-c(TRUE,FALSE,TRUE) #逻辑索引向量
#当逻辑索引向量的元素个数和原向量的元素个数相同时
lglv[logical_index] 逻辑索引向量c(TRUE,FALSE,TRUE)中位置1,3为TRUE,所以为索引出原向量位置1,3的元素。
#返回结果为,1,5
#当逻辑索引向量的元素个数和原向量的元素个数不同时
#那么此时便会用到循环补齐的概念。逻辑索引向量作为短向量,原向量作为长向量。
lgv[c(TRUE,FALSE)]

现在来做个小测验,如何取出一个向量中元素位置为奇数的元素,是不是感觉so easy了呢?
例子:eg9<-1:10;eg9[c(TRUE,FALSE)]


9.3 条件索引
条件索引是个啥,它就是个披上了条件判断外衣的,逻辑索引!
条件判断后,会转化成逻辑索引。
假设现在有向量a<-1:10
条件索引格式:向量名[条件] 比如a[a>5]
咱们拆解一下上面的这个条件索引。
首先,会进行条件判断,返回值为逻辑索引向量。
然后,逻辑索引向量,大家一定不陌生了吧!

9.4 名称索引
这个主要针对的是有名字的向量。
b<-c(name="james",age=36)
b["name"]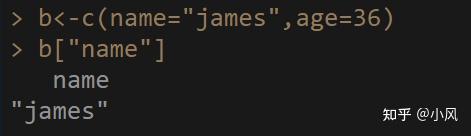

十、向量的增删改查
10.1 增
现在我们来创建一个向量
v<-c(1,5)
加入我现在想往里面,增加一个元素8,咋办呢?
老规矩,套娃操作呗。
v<-c(v,8) 现在v就变成了c(1,5,8)
或者使用append()函数
append(v,8)#这个函数知识将向量组合了,并没有真正在v中添加元素8,要想在v中增加元素8,还需要赋值给v
即v<-append(v,8) #很鸡肋的一个函数,我还不如继续套娃。。

或者,咱们还可以通过给不存在的元素位置赋值来给向量添加新元素
注意,如果该位置前面的位置没有元素的话,会被赋值为NA
比如v[5]<-110,现在来查看下向量v变成啥了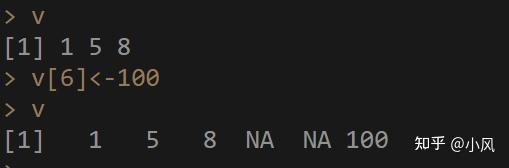

10.2 删
R语言中的删除操作,可以通过负索引,排除掉想删除的内容。然后返回给
a<-1:8
现在我们想删除掉第五个元素
a<-a[-5] #首先,我们排除掉了第五个位置的元素,然后,我们又赋值给了a
a<-a[-c(1,2,3)] #批量删除
a<-a[!(a>5)] #删除大于5的元素,通过a>5,筛选出大于5的元素的逻辑索引,然后通过!进行取反操作。得到小于5的元素。10.3 改
改的方式很简单,就是先索引出对应的元素,然后重新赋值即可。
比如:a<-c(1,5,3,4)
a[1]<-100 #索引向量中,位置为1的元素,重新赋值为100
a[1:2]<-0 #索引出向量中位置为1到2的元素,重新赋值为0
a[a>3]<-5 #条件索引出a中大于3的元素,重新赋值为5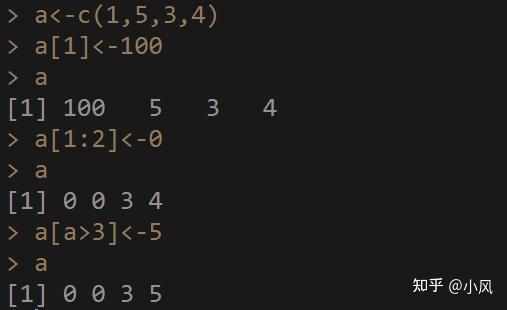

10.4 查
#先来看看一元向量的查询
b<-c("a","b","c","a")
#查询向量b中是否有一元字符串向量 "a"
b=="a" #长向量与短向量操作,短向量会自动进行循环补齐,然后变成了逻辑向量。
b[b=="a"] #此时,就会索引出向量b中的所有字符串。
#再来看下多元向量的查询,这个操作非常有用。
比如,我想查询下,上面向量b,是否包含字符串"b"和"c"
我们可以这样写。
c("b","c","a")%in%b
此时,左侧的三元向量,每个元素,都会查询自己是否在右边的向量b中,
并返回一个逻辑向量,长度与左侧的向量长度一致。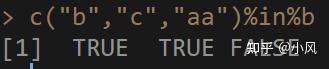
十一、常用函数
首先,列举一下常用的函数,其中的参数没有列举完。如果你对某个函数不太熟悉,可以使用命令help("函数名"),比如help("sum")
或者使用?sum,注意,问号要是英文状态下的问号。
- length(x):获取向量x中元素的个数
- rep():重复向量或者列表。
格式:rep(x,times=1,each=1)
times:为数字时表示将整个向量重复多少次,为向量时,表示将对应的元素复制多少次。
each:表示将向量中的每个元素重复多少次。
假设给定向量a<-
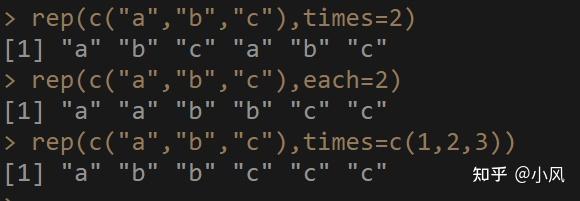
#1将向量重复2次
rep(c("a","b","c"),times=2)--------->c("a","b","c","a","b","c")
#将向量的每个元素重复2次
rep(c("a","b","c"),each=2)---------->c("a","a","b","b","c","c")
#将向量的每个元素,重复不同的次数
rep(c("a","b","c"),times=c(1,2,3))------->c("a","b","b","c","c","c")
"a"复制次数为times中的第一个元素
"b"复制次数为times中的第二个元素
"c"复制次数为times中的第三个元素

- seq():产生等差序列
格式:seq(from=1,to=1,by=1)
from:从哪里开始产生
to:到哪里结束
by:步长是多少
这个比较简单,就不截图了,具体操作可以自己尝试。 - which():返回逻辑值为TRUE的索引向量的位置
比如which(c(TRUE,FALSE,TRUE))------->返回c(1,3),即位置1,3的值为TRUE
这个函数比较有用,比如我们想查看某个向量中,某个值在哪个位置。
可以这样操作。which(a=="b")

- sort():给向量排序
格式:sort(x,decreasing=FALSE,na.last=NA)
x:向量
decreasing:是否按降序排列,默认为FALSE,则表示按升序排列。
na.last:默认为NA,表示排序的时候剔除掉NA,可以设置为TRUE,表示将NA值放到最后。 - order:返回向量中的元素,在排序好后的向量中的位置。
order(x,na.last=TRUE,decreasing=FALSE)
x:向量
decreasing:是否按降序排列,默认为FALSE,则表示按升序排列。
na.last:默认为TRUE,表示排序的时候将NA值放到最后。
举个例子:x<-c(4,1,5)
order(x)------->返回结果c(2,1,3)
注意看定义!
首先,x被按照从小到大的顺序排序完成后为------>c(1,4,5)
然后,我们现在来看x,x为(4,1,5),其中元素4在上面排序好中的向量的位置为2,元素1在上面排序好中的向量的位置为1,
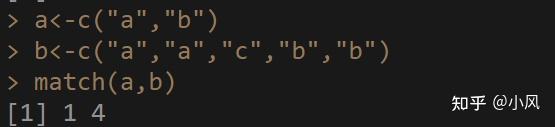
元素5在上面排序好中的向量的位置为3,所以order(x)---->返回值为c(2,1,3) - match():返回匹配的值的第一次的位置
格式:match(a,b)
a:想查找的值
b:在哪里查找
这个函数的功能就是:在b中依次匹配a中的元素,如果查找到了,返回第一次查找到的位置,否则返回与a等长的NA向量。
a<-c("a","b")
b<-c("a","a","c","b","b")
match(a,b)
注意,是只返回第一次匹配的位置。

- all()和any:检验参数是否全部为TRUE或者至少有一个为TRUE
all(c(TRUE,TRUE))----->因为向量中,元素值都为TRUE,所以返回TRUE。
any(c(TRUE,FALSE))----->因为向量中,元素值有一个为TRUE,所以返回TRUE
上述两个函数通常搭配条件判断来使用,为啥,因为条件判断,最后会变成逻辑向量。
而这两个函数,就是用来检验逻辑向量的。
通常,我们会用来检验是否存在缺失值。
使用:any(is.na(x))
先用is.na(x),对x中的每个值进行条件判断,判断是否为空,如果x是向量,那么is.na(x)返回的也是向量。
如果x是矩阵、数据框,那么is.na(x)返回的也是矩阵、数据框。只是所有的值都变成了逻辑值。
- table():统计向量中元素的频数
table(x)----->返回向量中各元素的统计频次,注意,返回的是一个向量,只是说这个向量是有名字的向量。
我们可以通过names()来获取向量的名字。 - rev(x):用于反转向量x的元素
- 其它函数
以下基本都是处理数值型向量的函数:
max(x):找出x向量中的最大值
min(x):找出x向量中的最小值
range(x):找出x向量中的最小值和最大值
sum(x):求x向量的元素和
prod(x):求x向量的元素积
mean(x):求x向量的平均值
median(x):求x向量的中位数
var(x):求x向量的方差
sd(x):求x向量的标准差,注意,分母为(n-1)
cor(x, y):求x向量和y向量的相关系数
quantile(x):返回x向量的最小值、下分位数、中位数、上分位数和最大值
cumsum(x):返回x向量的累计和
cumprod(x):返回x向量的累计积
cummax(x):返回x向量的累计最大值
cummin(x):返回x向量的累计最小值
pmax(x, y, z):返回x、y、z向量对应位置上的最大值
pmin(x, y, z):返回x、y、z向量对应位置上的最小值
diff(x):返回x向量的相邻两元素之差,常用在时间序列中的差分操作。
union(x, y):x向量和y向量的并集
intersect(x, y):x向量和y向量的交集
setdiff(x, y):在x中,却不在y中的元素
处理字符串类型的函数,可以参考公众号内另外一篇文章:stringr包那篇。
学会处理数值型和字符串型向量,基本能解决向量90%的问题了。十二、总结
- 标量是一元向量、一元向量和多元向量,区别在于元素个数的多少。
- 在处理向量时,必须要知道向量中元素的类型是什么。
- 向量的元素类型必须为同一类型,在进行向量组合时,要特别注意向量元素的自动转换机制。
- 向量的索引非常重要,尤其是条件索引,这些都需要自己平常多练习和积累。
- 向量运算间的循环补齐也要大致了解,究竟是怎么回事。
- 向量是R语言中极其重要的一个对象,务必掌握好,多动手,多练习。
