
SQL中distinct的用法(四种示例分析)
SQL中distinct的用法(四种示例分析)
distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值。其原因是distinct只能返回它的目标字段,而无法返回其它字段,接下来通过本篇文章给大家分享SQL中distinct的用法,需要的朋友可以参考下
在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只 用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值。其原因是distinct只能返回它的目标字段,而无法返回其它字段,这个问题让我困扰很久,用distinct不能解决的话,我只有用二重循环查询来解决,而这样对于一个数据量非常大的站来说,无疑是会直接影响到效率的,所以浪费了我大量时间。
在表中,可能会包含重复值。这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值。关键词 distinct用于返回唯一不同的值。
表A:
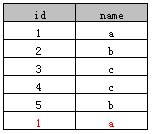
示例1
select distinct name from A
执行后结果如下:

示例2
select distinct name, id from A
执行后结果如下:
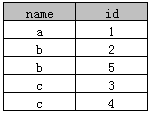
实际上是根据“name+id”来去重,distinct同时作用在了name和id上,这种方式Access和SQL Server同时支持。
示例3:统计
select count(distinct name) from A; --表中name去重后的数目, SQL Server支持,而Access不支持
select count(distinct name, id) from A; --SQL Server和Access都不支持
示例4
select id, distinct name from A; --会提示错误,因为distinct必须放在开头
其他
distinct语句中select显示的字段只能是distinct指定的字段,其他字段是不可能出现的。例如,假如表A有“备注”列,如果想获取distinc name,以及对应的“备注”字段,想直接通过distinct是不可能实现的。
