
【CUDA教程】二、主存与显存

僕は全身全霊懸けても 即使我拼尽全力投入征战
何時か一刀両断するから 总有一天也会一刀两断
見てみたいなら 如果你想看
待っててよ 就请耐心等待
必ず倒すからさぁ 我一定会打倒所有的困难
——MY FIRST STORY《絶体絶命》
上一篇我介绍了cuda的基本知识,本篇我将会介绍有关主存和显存的相关概念和二者的联系。
__host__,__device__与__global__修饰函数
cuda中引入了三个宏:__host__、__device__与__global__,用于修饰函数,使得函数被定位到不同的位置。
那修饰后的函数有什么作用呢?
__host__函数,其实就是我们平常写C/C++所定义的运行在CPU中的函数,这个修饰符通常可以不写,效果是等价的。而__device__函数和__global__函数则是必须运行在GPU的函数,因此必须要显式声明在函数前。
我们来看下例:
#include <cstring>
#include <cstdlib>
#include <cassert>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
__device__ double triple(double x) {
//返回x的三倍
return x * 3;
}
__global__ void kern_AddVector(double* c, double const* a, double const* b, size_t n) {
//求向量c = a + 3b
size_t Idx = blockIdx.x * blockDim.x + threadIdx.x;
if(Idx >= n) return; //超过数组大小,直接返回
c[Idx] = a[Idx] + triple(b[Idx]); //实现向量相加
}
__host__ void addVector(double* c, double const* a, double const* b, size_t n) {
//申请显存内地址
double *device_c, *device_a, *device_b;
assert(cudaSuccess == cudaMalloc(&device_c, sizeof(double) * n));
assert(cudaSuccess == cudaMalloc(&device_a, sizeof(double) * n));
assert(cudaSuccess == cudaMalloc(&device_b, sizeof(double) * n));
//将数据拷贝到显存之中
assert(cudaSuccess == cudaMemcpy(device_a, a, sizeof(double) * n, cudaMemcpyHostToDevice));
assert(cudaSuccess == cudaMemcpy(device_b, b, sizeof(double) * n, cudaMemcpyHostToDevice));
//执行核函数
size_t thread_count = 1024;
size_t block_count = (n - 1) / thread_count + 1;
kern_AddVector<<<block_count, thread_count>>> (device_c, device_a, device_b, n);
cudaDeviceSynchronize();
cudaError_t ct = cudaGetLastError();
assert(cudaSuccess == ct);
//将显存中的数据拷贝到主存中
assert(cudaSuccess == cudaMemcpy(c, device_c, sizeof(double) * n, cudaMemcpyDeviceToHost));
//释放临时变量
assert(cudaSuccess == cudaFree(device_a));
assert(cudaSuccess == cudaFree(device_b));
assert(cudaSuccess == cudaFree(device_c));
}
#include <cstdio>
int main() {
const size_t N = 10;
double a[N] = {0.1, 0.2, -0.3, 0.1, 0.5, -0.2, 0.2, -0.3, 0.4, 0.1};
double b[N] = {0.2, -0.1, -0.1, 0.2, -0.2, 0.2, 0.1, 0.1, 0.1, 0.3};
double c[N];
addVector(c, a, b, N);
for(double& e: c) {
printf("%lf, ", e);
}
return 0;
}
例子中addVector函数就是__host__函数,当然main函数也是__host__函数。
__host__函数可以直接调用__host__函数,但不能直接调用__device__函数;__host__函数可以通过传递运行时参数来调用__global__函数,同样也不能像调用__host__函数那样直接调用。而能调用__device__函数的只有__global__函数或者__device__函数。
比如如果main函数这样写,就会报错:
int main() {
//__host__函数直接调用__device__函数
double e3 = triple(e); //error: calling a __device__ function("triple") from a __host__ function("main") is not allowed
//不传递运行时参数调用__global__函数
kern_AddVector(c, a, b, N); //error: a __global__ function call must be configured
}
事实上,我们现在大多数的显卡都已经支持了sm_50, compute_50及以上的计算能力(我们可以使用上一篇中提到的deviceQuery来获取自己显卡的计算能力),而这更加丰富了我们的调用关系——50之前cuda没有调用栈,所有__device__函数在编译的时候都是内联的;但50之后,__device__函数可以通过调用__device__函数实现直接或者间接的递归;而__device__和__global__函数也可以继续通过传递运行时参数调用__global__函数,实现二级甚至二级以上的并行。用拓扑结构图来表示则是:
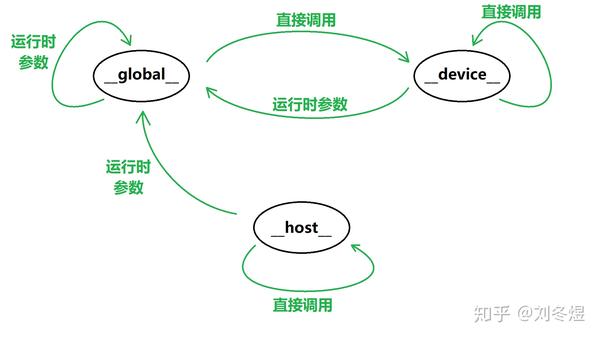

除了函数被宏修饰,变量也可以被修饰。
__device__,__shared__与__constant__修饰变量
__device__、__shared__与__constant__也是cuda的宏,用于修饰变量(别忘了__device__也可以修饰函数)。三种变量都不会被声明在CPU中,而是在GPU中。
__device__变量即设备端的全局变量,和C/C++的全局变量声明位置一样,只能在所有类和函数外声明。__host__函数无法直接访问__device__变量,但可以通过cuda运行库中的cudaMemcpyToSymbol()以及cudaMemcpyFromSymbol()函数传递或获取到它的值。__device__函数和__global__函数可以直接访问它们,只需要注意不要线程冲突就好。
__shared__变量即块内共享变量,只能在__device__函数或者__global__函数内被声明。__shared__变量不能跨过一个线程块,所以声明时其所在的__global__函数的运行时变量中的块数往往是1——当然也可以是更大的值,但某一个块中的__shared__变量就无法被其他块所访问到。变量声明时不能初始化,但可以对它进行赋值。
__constant__变量即设备端的常量,并不像它的名字那样一成不变——但至少它在__device__函数和__global__函数中的访问权限是只读的,这样它就可以被放在高速缓存中,极大地提升访问效率。声明方法又和C/C++不同:声明时赋初值是无效的,必须在__host__函数中通过cuda运行库中的cudaMemcpyToSymbol()函数传递给它;当然,__host__函数内部也可以用cudaMemcpyFromSymbol()函数获取到它的值。
于是我们又可以丰富上图:
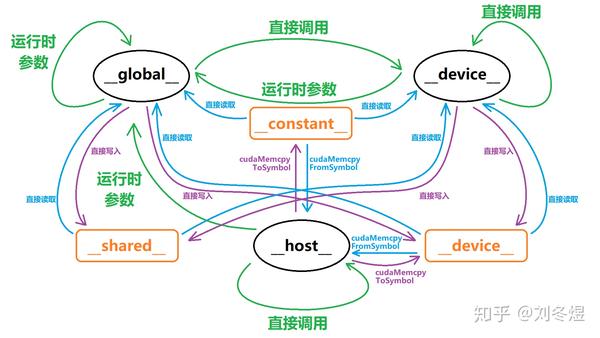

图片是1920×1080的,所以想拿去做壁纸也是没问题的(狗头)。
而如果变量前面没有修饰,那就是寄存器变量(就像C/C++里的寄存器变量),如果是在__device__函数或者__global__函数内,那么每个线程分别持有一个该变量,不会共享,对其读取和修改也只会发生在该线程内。
不过要注意,__device__和__constant__只能声明在全局变量区域,__shared__变量只能声明在核函数内部,类的成员变量和其他函数内的局部变量是无法被上述关键词修饰的。
下面代码是一个例子:
#include <cstdio>
#include <cassert>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#define N 10
__device__ int arr[N];
__global__ void print() {
size_t Idx = blockIdx.x * blockDim.x + threadIdx.x;
if(Idx >= N) return;
printf("%d\n", arr[Idx]);
}
int main() {
int a[N] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
assert(cudaSuccess == cudaMemcpyToSymbol(arr, a, sizeof(a)));
print<<<10, 1>>> ();
cudaDeviceSynchronize();
assert(cudaSuccess == cudaGetLastError());
}
这里没有使用前文例子中的thread_count和block_count,因为我们明确知道线程数是远小于1024的,甚至核函数内也不需要写大于N则返回的逻辑。
当然,由于是多线程,所以输出是乱序的。但如果交换核数和线程数,因为一个核内线程是轮转调度的,所以输出是顺序的。
cudaMalloc、cudaFree、cudaMemset与cudaMemcpy
cuda_runtime.h库中包含了一些和标准C语言库中的函数非常相近的__host__函数——注意,他们只能在__host__函数中被调用,__global__函数和__device__函数要调用函数原型。
这些函数原型是:
cudaError_t cudaMalloc(void **devPtr, size_t size);
cudaError_t cudaFree(void *devPtr);
cudaError_t cudaMemset(void *devPtr, int value, size_t count);
cudaError_t cudaMemcpy(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind);
cudaError_t cudaMemcpyToSymbol(const void *symbol, const void *src, size_t count, size_t offset = 0, enum cudaMemcpyKind kind = cudaMemcpyHostToDevice);
cudaError_t cudaMemcpyFromSymbol(void *dst, const void *symbol, size_t count, size_t offset = 0, enum cudaMemcpyKind kind = cudaMemcpyDeviceToHost);
前四个函数,我们可以通过名字找到它们在C/C++里的“近亲”:
void* malloc(size_t _Size);
void free(void* _Block);
void* memset(void* _Dst, int _Val, size_t _Size);
void* memcpy(void* _Dst, void const* _Src, size_t _Size);
但是这些函数又清一色地返回了cudaError_t这一枚举类型,所以,我们在申请显存空间时,写法应为:
double* p; const size_t N = 10;
cudaError_t ct = cudaMalloc(&p, sizeof(double) * N);
assert(cudaSuccess == ct);
//对比在内存中的malloc:
p = (double*)malloc(sizeof(double) * N);
相信大家也猜到了cudaFree和cudaMemset的用法,事实上我并不喜欢额外创建一个cudaError_t变量,而是直接放在assert中:
assert(cudaSuccess == cudaMemset(p, 0, sizeof(double) * N));
assert(cudaSuccess == cudaFree(p));
//对比在内存中的memset、free:
memset(p, 0, sizeof(double) * N);
free(p);
cudaMemcpy函数不同于memcpy,它有第四个参数,是cudaMemcpyKind枚举类型,其声明如下:
enum __device_builtin__ cudaMemcpyKind
{
cudaMemcpyHostToHost = 0, /**< Host -> Host */
cudaMemcpyHostToDevice = 1, /**< Host -> Device */
cudaMemcpyDeviceToHost = 2, /**< Device -> Host */
cudaMemcpyDeviceToDevice = 3, /**< Device -> Device */
cudaMemcpyDefault = 4 /**< Direction of the transfer is inferred from the pointer values. Requires unified virtual addressing */
};
相信注释也写得非常清楚了:
- cudaMemcpyHostToHost就是从主机端拷贝到主机端,即此时cudaMemcpy等价于memcpy,不属于I/O,耗时最短;
- cudaMemcpyHostToDevice则是从主机端传送到设备端,即源数据在内存中,目标指针指向了一段显存范围,属于I/O,消耗时间较长;
- cudaMemcpyDeviceToHost则是从设备端传送到主机端,即源数据在显存中,目标指针指向了一段内存范围,同样属于I/O,消耗时间较长;
- cudaMemcpyDeviceToDevice则是从设备端拷贝到设备端,CPU只给显卡发送一个信号,不涉及数据交互,因此不属于I/O,不会消耗太多时间。大多数情况下可以异步执行。
下列代码则是一些例子:
/*
* host_a、host_b是经过malloc或new,或者全局、局部变量的数组,包含有N个int
* device_a、device_b是经过cudaMalloc的数组,同样包含有N个int
*/
cudaMemcpy(host_a, host_b, sizeof(int) * N, cudaMemcpyHostToHost); //正确
cudaMemcpy(device_b, host_b, sizeof(int) * N, cudaMemcpyHostToDevice); //正确
cudaMemcpy(host_a, device_a, sizeof(int) * N, cudaMemcpyDeviceToHost); //正确
cudaMemcpy(device_b, device_a, sizeof(int) * N, cudaMemcpyDeviceToDevice); //正确
cudaMemcpy(host_a, device_a, sizeof(int) * N, cudaMemcpyHostToDevice); //错误,函数返回一个cudaErrorInvalidValue
cudaMemcpy(device_b, device_a, sizeof(int) * N, cudaMemcpyHostToHost); //错误,函数返回一个cudaErrorInvalidValue
cudaMemcpy(device_b, host_b, sizeof(int) * N, cudaMemcpyDeviceToDevice); //错误,函数返回一个cudaErrorInvalidValue
cudaMemcpy(host_a, host_b, sizeof(int) * N, cudaMemcpyDeviceToHost); //错误,函数返回一个cudaErrorInvalidValue
而cudaMemcpyToSymbol()和cudaMemcpyFromSymbol()两个函数,前文也提到了,是用来初始化__device__显存全局变量和__constant__显存常量的。虽然函数有五个变量,但后两个变量我们一般只用其初始值,所以写法通常为:
__constant__ int arr[N];
__host__ void init() {
int a[N] = {9, 8, 7, 6, 5, 4, 3, 2, 1, 0};
int b[N];
assert(cudaSuccess == cudaMemcpyToSymbol(arr, a, sizeof(a)));
assert(cudaSuccess == cudaMemcpyFromSymbol(b, arr, sizeof(b)));
}
可是正如前文所说的,这些函数都是__host__函数,只能在__host__函数中被调用。那么__global__和__device__函数该如何申请、复制、修改和释放显存数据呢?
设备端的malloc、free、memset和memcpy
没错,这就是答案——在__global__和__device__函数中使用函数的原型:
template<typename T>
__global__ void buildList(T** arrs, size_t size, size_t tot_list) {
size_t Idx = blockIdx.x * blockDim.x + threadIdx.x;
if(Idx >= tot_list) return;
arrs[Idx] = (T*)malloc(sizeof(T) * size);
memset(arrs[Idx], 0, sizeof(T) * size);
}
template<typename T>
__global__ void copyList(T** dsts, const T* const* srcs, size_t size, size_t tot_list) {
size_t Idx = blockIdx.x * blockDim.x + threadIdx.x;
if(Idx >= tot_list) return;
memcpy(dsts[Idx], srcs[Idx], sizeof(T) * size);
}
template<typename T>
__global__ void clearList(T** arrs, size_t tot_list) {
size_t Idx = blockIdx.x * blockDim.x + threadIdx.x;
if(Idx >= tot_list) return;
free(arrs[Idx]);
}
这三个函数实现了长度为tot_list的指针数组的每一个元素并行申请大小为size的内存并初始化,深拷贝指针数组,以及并行释放指针数组中的每一个元素的功能。
编程中可能出现的异常
说了半天,也没有提到cudaError_t具体会返回什么异常。
首先我们看一下枚举类型cudaError_t的常见值:
- cudaSuccess = 0。这是几乎所有程序继续运行下去的基础,即未发生任何错误。
- cudaErrorInvalidValue =1。在初学者身上比较常见意为传入API函数的值不在合法区间范围内。通常是一些低级错误,比如在初始化常量时没有使用cudaMemcpyToSymbol而是错误使用了cudaMemcpy、或是在cudaMalloc、cudaMemcpy等函数中传递了空指针等。
- cudaErrorMemoryAllocation = 2。通常是需要申请内存的函数如cudaMalloc会返回这个错误,一般是申请的内存超过了可用显存大小。
- cudaErrorInitializationError = 3。任何runtime库中的函数都有可能返回这个异常,但只有可能在第一次调用时返回。因为cuda的初始化方法是lazy context initialization,即直到调用才会初始化,并不会在程序一开始就初始化。
- cudaErrorCudartUnloading = 4。出现这个异常大多都是误删了cuda驱动。如果出现这个异常,请自行忏悔。
- cudaErrorInvalidConfiguration = 9。通常是传递运行时参数时超过了显卡的负载,如线程数大于deviceQuery输出的每个核的最大线程数、核数大于网格中最大核数等等。
- cudaErrorInvalidPitchValue = 12。一般是在使用cudaMemcpy2D、cudaMemcpy3D等拷贝高维数组时,Pitch出现了问题——可能没有申请Pitch,或者Pitch的地址出错等等。
- cudaErrorInvalidSymbol = 13。即对显存全局变量和常量进行相关操作时,符号名称出错,或进行了多余的格式转换。如你想将数组a拷贝给显存常量arr时,传递的第一个参数可以是单纯的arr,也可以是加引号的"arr",如果写成是转化过的(void*)arr,就会返回这一错误。
- cudaErrorDuplicateVariableName = 43。意为你在定义全局变量时,出现了多个变量重名的情况,可能在同一文件中,也可能在链接前的不同文件中。
- cudaErrorNoDevice = 100。你需要检查你的显卡是否支持cuda。
- cudaErrorFileNotFound = 301。找不到指定文件。
- cudaErrorSymbolNotFound = 500。找不到符号名。通常是在通过字符串寻找设备符号时出现的,此时需要检查你的拼写。
- cudaErrorIllegalAddress = 700。你可能搞错了传入API的指针究竟指向了内存空间还是显存空间,或者在核函数访问时发生了数组越界等等,产生了非法地址。一旦出现了这个问题,程序就必须终止才能继续使用cuda。
- cudaErrorLaunchOutOfResources = 701。你可能使用了过多的线程数或寄存器数,可以deviceQuery一下,然后在项目设置中限制一下寄存器的使用。
- cudaErrorAssert = 710。即在__global__或__device__函数中的断言assert被触发,在触发的同时cuda往往也会将具体行数、核坐标、线程坐标的信息打印出来。一旦出现了这个问题,程序就必须终止才能继续使用cuda。
- cudaErrorHardwareStackError = 714。通常是栈溢出,可能是你在递归__global__或__device__函数的层数太多,或函数内局部变量数组开得太大。一旦出现了这个问题,程序就必须终止才能继续使用cuda。
- cudaErrorLaunchFailure = 719。在执行核函数时发生了内核异常,通常是设备共享内存越界、取消引用无效设备指针等等。一旦出现了这个问题,程序同样必须终止之后才能继续使用cuda。
有关错误代码我将在CUDA教程四中详细介绍。
有关主存、显存、runtime库的基本函数以及cudaError_t的介绍就是这些了。
明天就要考科一了,祝我好运。
