

NoSQL技术(Redis、MongoDB)
Redis
概念和基础
Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
基本数据类型
首先对redis来说,所有的key(键)都是字符串。我们在谈基础数据结构时,讨论的是存储值的数据类型,主要包括常见的5种数据类型,分别是:String、List、Set、Zset、Hash。
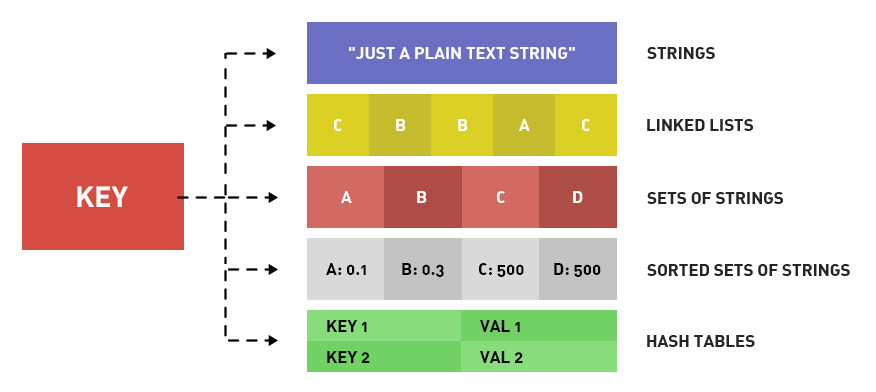
| 结构类型 | 结构存储的值 | 结构的读写能力 |
|---|---|---|
| String字符串 | 可以是字符串、整数或浮点数 | 对整个字符串或字符串的一部分进行操作;对整数或浮点数进行自增或自减操作; |
| List列表 | 一个链表,链表上的每个节点都包含一个字符串 | 对链表的两端进行push和pop操作,读取单个或多个元素;根据值查找或删除元素; |
| Set集合 | 包含字符串的无序集合 | 字符串的集合,包含基础的方法有看是否存在添加、获取、删除;还包含计算交集、并集、差集等 |
| Hash散列 | 包含键值对的无序散列表 | 包含方法有添加、获取、删除单个元素 |
| Zset有序集合 | 和散列一样,用于存储键值对 | 字符串成员与浮点数分数之间的有序映射;元素的排列顺序由分数的大小决定;包含方法有添加、获取、删除单个元素以及根据分值范围或成员来获取元素 |
String字符串
String类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。如数字,字符串,jpg图片或者序列化的对象。
下面是一些命令的使用:
| 命令 | 简述 | 使用 |
|---|---|---|
| GET | 获取存储在给定键中的值 | GET name |
| SET | 设置存储在给定键中的值 | SET name value |
| DEL | 删除存储在给定键中的值 | DEL name |
| INCR | 将键存储的值加1 | INCR key |
| DECR | 将键存储的值减1 | DECR key |
| INCRBY | 将键存储的值加上整数 | INCRBY key amount |
| DECRBY | 将键存储的值减去整数 | DECRBY key amount |
List列表
Redis中使用双端链表实现List
使用List结构,我们可以轻松地实现最新消息排队功能。List的另一个应用就是消息队列,可以利用List的 PUSH 操作,将任务存放在List中,然后工作线程再用 POP 操作将任务取出进行执行。
下面是一些命令的使用:
| 简述 | 使用 | |
|---|---|---|
| RPUSH | 将给定值推入到列表右端 | RPUSH key value |
| LPUSH | 将给定值推入到列表左端 | LPUSH key value |
| RPOP | 从列表的右端弹出一个值,并返回被弹出的值 | RPOP key |
| LPOP | 从列表的左端弹出一个值,并返回被弹出的值 | LPOP key |
| LRANGE | 获取列表在给定范围上的所有值 | LRANGE key 0 -1 |
| LINDEX | 通过索引获取列表中的元素。 -1 表示列表的最后一个元素。 | LINDEX key index |
Set集合
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
下面是一些命令的使用:
| 命令 | 简述 | 使用 |
|---|---|---|
| SADD | 向集合添加一个或多个成员 | SADD key value |
| SCARD | 获取集合的成员数 | SCARD key |
| SMEMBERS | 返回集合中的所有成员 | SMEMBERS key member |
| SISMEMBER | 判断 member 元素是否是集合 key 的成员 | SISMEMBER key member |
Hash散列
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
下面是一些命令的使用:
| 命令 | 简述 | 使用 |
|---|---|---|
| HSET | 添加键值对 | HSET hash-key sub-key1 value1 |
| HGET | 获取指定散列键的值 | HGET hash-key key1 |
| HGETALL | 获取散列中包含的所有键值对 | HGETALL hash-key |
| HDEL | 如果给定键存在于散列中,那么就移除这个键 | HDEL hash-key sub-key1 |
Zset有序集合
有序集合的成员是唯一的, 但分数(score)却可以重复。有序集合是通过两种数据结构实现:
- 压缩列表(ziplist): ziplist是为了提高存储效率而设计的一种特殊编码的双向链表。它可以存储字符串或者整数,存储整数时是采用整数的二进制而不是字符串形式存储。它能在O(1)的时间复杂度下完成list两端的push和pop操作。但是因为每次操作都需要重新分配ziplist的内存,所以实际复杂度和ziplist的内存使用量相关
- 跳跃表(zSkiplist): 跳跃表的性能可以保证在查找,删除,添加等操作的时候在对数期望时间内完成,这个性能是可以和平衡树来相比较的,而且在实现方面比平衡树要优雅,这是采用跳跃表的主要原因。跳跃表的复杂度是O(log(n))。
下面是一些命令的使用:
| 命令 | 简述 | 使用 |
|---|---|---|
| ZADD | 将一个带有给定分值的成员添加到有序集合里面 | ZADD zset-key 178 member1 |
| ZRANGE | 根据元素在有序集合中所处的位置,从有序集合中获取多个元素 | ZRANGE zset-key 0-1 withccores |
| ZREM | 如果给定元素成员存在于有序集合中,那么就移除这个元素 | ZREM zset-key member1 |
特殊数据类型
HyperLogLogs(基数统计)
这个结构可以非常省内存的去统计各种计数,比如注册 IP 数、每日访问 IP 数、页面实时UV、在线用户数,共同好友数等。
下面是一些命令的使用:
| 命令 | 简述 | 使用 |
|---|---|---|
| PFADD | 创建一组元素 | pfadd key1 元素 |
| PFCOUNT | 统计元素的基数数量 | pfcount key1 |
| PFMERGE | 合并两组元素 | pfmerge key3 key1 key2 |
Bitmap (位存储)
Bitmap 即位图数据结构,都是操作二进制位来进行记录,只有0 和 1 两个状态。
下面是一些命令的使用:
| 命令 | 简述 | 使用 |
|---|---|---|
| SETBIT | 设置bit | setbit xxx key value |
| GETBIT | 获取bit | getbit xxx key |
| BITCOUNT | 统计bit | bitcount xxx |
Stream
Redis5.0 中还增加了一个数据结构Stream,从字面上看是流类型,但其实从功能上看,应该是Redis对消息队列(MQ,Message Queue)的完善实现。
PUB/SUB,订阅/发布模式
- 但是发布订阅模式是无法持久化的,如果出现网络断开、Redis 宕机等,消息就会被丢弃;
基于List LPUSH+BRPOP 或者 基于Sorted-Set的实现
- 支持了持久化,但是不支持多播,分组消费等
其他特殊类型
其他特殊类型还有地理位置信息geospatial等,可以在官方文档中查看这里不详细讲解。
MongoDB
概念和基础
MongoDB是面向文档的NoSQL数据库,用于大量数据存储。每个数据库都包含集合,而集合又包含文档。每个文档可以具有不同数量的字段。每个文档的大小和内容可以互不相同。 文档结构更符合开发人员如何使用各自的编程语言构造其类和对象。
基本操作
show dbs # 查看数据库
use mydb # 使用/创建一个名为mydb的数据库
db.dropDatabase() # 删除数据库
# 查看集合
show tables
show collections
# 创建集合
db.createCollection(name, options)
# 删除集合
db.collection.drop()
创建集合时,options可以是以下参数:
| 字段 | 类型 | 描述 |
|---|---|---|
| capped | 布尔 | (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。 当该值为 true 时,必须指定 size 参数。 |
| autoIndexId | 布尔 | 3.2 之后不再支持该参数。(可选)如为 true,自动在 _id 字段创建索引。默认为 false。 |
| size | 数值 | (可选)为固定集合指定一个最大值,即字节数。 如果 capped 为 true,也需要指定该字段。 |
| max | 数值 | (可选)指定固定集合中包含文档的最大数量。 |
文档操作
插入
# insert 已存在不插入
db.COLLECTION_NAME.insert(document)
# save 已存在更新
db.COLLECTION_NAME.save(document)
# 插入一条
db.collection.insertOne(
<document>,
{
writeConcern: <document>
}
)
# 插入多条
db.collection.insertMany(
[ <document 1> , <document 2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
)
# document:要写入的文档。
# writeConcern:写入策略,默认为 1,即要求确认写操作,0 是不要求。
# ordered:指定是否按顺序写入,默认 true,按顺序写入。
更新
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
# query : update的查询条件,类似sql update查询内where后面的。
# update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
# upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
# multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
# writeConcern :可选,抛出异常的级别。
删除
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
# query :(可选)删除的文档的条件。
# justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。
# writeConcern :(可选)抛出异常的级别。
查询
简单查询:
db.collection.find(query, projection)
# query :可选,使用查询操作符指定查询条件
# projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
db.col.find().pretty() # 格式化查询
# 跳过num2条数据,查询出num1条数据
db.COLLECTION_NAME.find().limit(num1).skip(num2) # 限制查询
# 排序查询
db.COLLECTION_NAME.find().sort({KEY:1}) # 1升序,-1降序
条件查询:
| 操作 | 格式 | 范例 |
|---|---|---|
| 等于 | {<key>:<value>} |
db.col.find({"by":"xxx"}).pretty() |
| 小于 | {<key>:{$lt:<value>}} |
db.col.find({"likes":{$lt:50}}).pretty() |
| 小于或等于 | {<key>:{$lte:<value>}} |
db.col.find({"likes":{$lte:50}}).pretty() |
| 大于 | {<key>:{$gt:<value>}} |
db.col.find({"likes":{$gt:50}}).pretty() |
| 大于或等于 | {<key>:{$gte:<value>}} |
db.col.find({"likes":{$gte:50}}).pretty() |
| 不等于 | {<key>:{$ne:<value>}} |
db.col.find({"likes":{$ne:50}}).pretty() |
# AND查询
db.col.find({key1:value1, key2:value2})
# OR查询
db.col.find({$or: [{key1: value1}, {key2:value2}]})
索引
# 创建索引
db.collection.createIndex(keys, options)
可选参数:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
聚合
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
可选参数:
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
| $push | 将值加入一个数组中,不会判断是否有重复的值。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet | 将值加入一个数组中,会判断是否有重复的值,若相同的值在数组中已经存在了,则不加入。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |

