python使用pandas操作excel
pandas 库是基于numpy库 的软件库,因此安装Pandas 之前需要先安装numpy库。默认的pandas不能直接读写excel文件,需要安装读、写库即xlrd、xlwt才可以实现xls后缀的excel文件的读写,要想正常读写xlsx后缀的excel文件,还需要安装openpyxl库 。
pandas详解
转载自:https://blog.csdn.net/weixin_46277553/article/details/123922187?spm=1001.2014.3001.5502
1.什么是pandas
Pandas 这个名字来源于面板数据(Panel Data)与数据分析(data analysis)这两个名词的组合。Pandas 是一个开源的第三方 Python 库,从 Numpy 和 Matplotlib 的基础上构建而来,享有数据分析“三剑客之一”的盛名(NumPy、Matplotlib、Pandas)。Pandas 已经成为 Python 数据分析的必备高级工具,它的目标是成为强大、灵活、可以支持任何编程语言的数据分析工具。
2.为什么要学习pandas
numpy能够帮我们处理处理数值型数据,但是这还不够。
很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等
比如:我们通过爬虫获取到了存储在数据库中的数据等等。
因此,numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我们处理其他类型的数据。
(二)pandas的常用数据类型
1.Series(一维,带标签数组)
import pandas as pd a = pd.Series([1,5,4,85,87,512]) print(a,type(a))
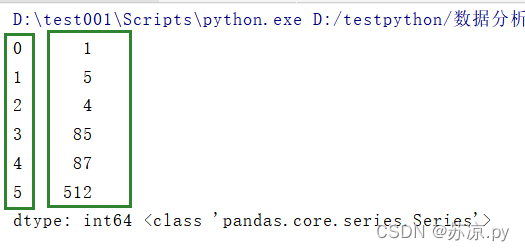
从上述结果中我们可以看到Series创建的对象带有索引。
1.1 创建索引
pd.Series([],index=list(string))
b = pd.Series([1,5,4,2,45,45,24,5],index=list('abcdefgh')) print(b)

1.2 通过字典创建Series
通过字典也可以创建Series对象,此时字典的键为索引。
import pandas as pd dic = { 'name':'苏凉.py', 'age':'22', 'qq_num':'787991021', } information = pd.Series(dic) print(information)

1.3 Series的切片和索引
Series对象本质上由两个数组构成,一个数组构成对象的键(index,索引),一个数组构成对象的值(values),键->值
1.3.1 显示某个值
import pandas as pd dic = { 'name':'苏凉.py', 'age':'22', 'qq_num':'787991021', } information = pd.Series(dic) print(information) print('-'*100) print(information[0])
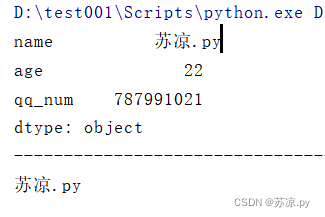
1.3.2 显示多个不连续的值
print(information[[0,2,3]])

1.3.3 显示多个连续的值
print(information[0:3])
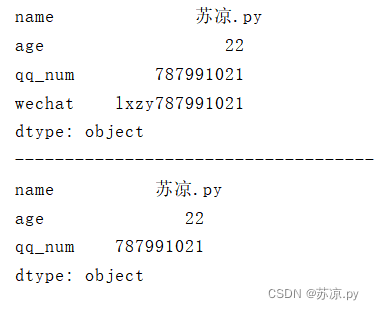
1.3.4 通过索引查找值
print(information[['name','age','wechat']])

1.4 Series的索引和值属性
对于一个陌生的Series类型,我们可以通过index和values来了解它的索引和值。
1.4.1 Series的索引(index)
print(information.index)
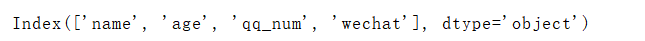
1.4.2 索引遍历
a = information.index for i in a: print(i)
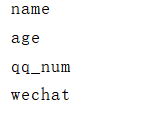
1.4.3 Series的值(values)
print(information.values)
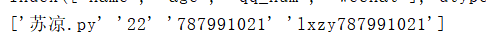
2.DataFrame(二维,Series容器)
import pandas as pd import numpy as np a = pd.DataFrame(np.arange(1,13).reshape(3,4)) print(a)
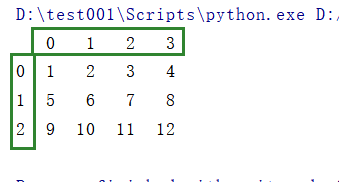
这里可以看到用DataFrame创建数组时存在行索引和列索引。
行索引:表明不同行,横向索引,叫index,0轴,axis=0.
列索引:表明不同列,纵向索引,叫columns,1轴,axis=1.
2.1 创建索引
pd.DataFrame([]),index=list(),columns=list()
a = pd.DataFrame(np.arange(1,13).reshape(3,4),index=list('123'),columns=list('ABCD'))
2.2 通过字典创建DataFrame
方法一:
import pandas as pd list = { 'name':['苏凉.py','佚名'], 'age':['22','15'], 'QQ_num':['787991021','01234567'], 'wechat':['lxzy787991021','ym789456'] } person = pd.DataFrame(list) print(person)

方法二:
import pandas as pd list2 = [ {'name':'苏凉.py','age':'22','QQ_num':'787991021','wechat':'lxzy787991021'}, {'name':'佚名','QQ_num':'01234567','wechat':'ym789456'} ] person = pd.DataFrame(list2) print(person)
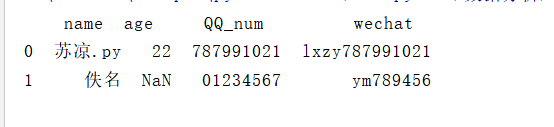
这里可以看到当我们对应的位置没有输入值时结果NaN
2.3 DataFrame的索引和切片
注:在dataframe中进行取行或者取列操作时,[]中为数字则取行,[]中为字符串则取列!!
2.3.1 取前几行
print(person[:2])

2.3.2 取某列
print(person['name'])

2.3.3 取多列
print(person[['name','wechat']])

2.4 利用DataFrame的loc和iloc方法取值
2.4.1 利用loc获取值
loc时通过标签索引来获取值
2.4.1.1 取某行
print(person.loc[1,:])
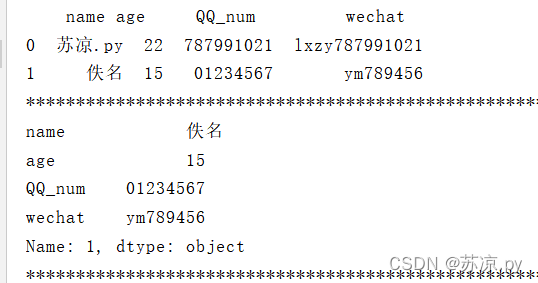
2.4.1.2 取多行
print(person.loc[[0,1]])

2.4.1.3 取某列
print(person.loc[:,'name'])
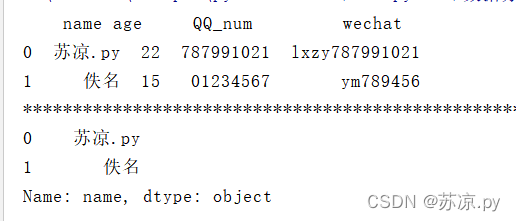
2.4.1.4 取多列
print(person.loc[:,['name','wechat']])

2.4.2 利用iloc来获取值
iloc是通过位置来获取值
下面列举四个例子即可:
2.4.2.1 获取行
print(person.iloc[0,])
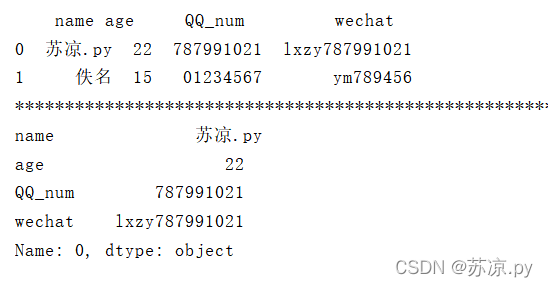
2.4.2.2 获取列
print(person.iloc[:,2])
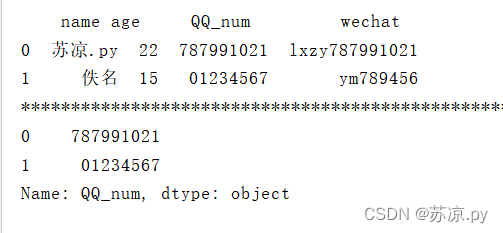
2.4.2.3 获取某行某列
print(person.iloc[0,3])

2.4.2.4 获取多行多列
print(person.iloc[[0,1],[0,2,3]])

**************************************************************************************************************************
简单操作excel:
(一)创建文件
import pandas as pd df = pd.DataFrame() df.to_excel('D:/Temp01/test.xlsx') print('创建成功!!')
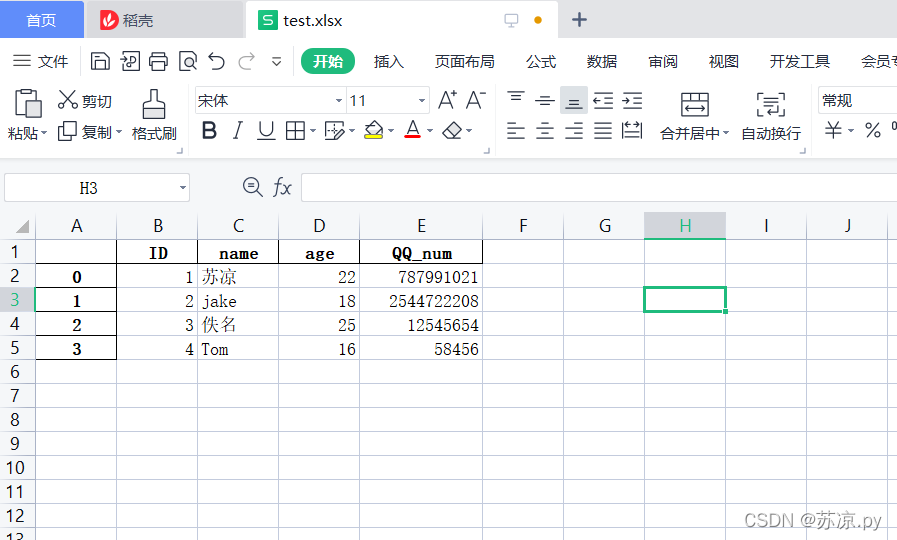
1.在创建的表格内插入数据
只需将我们定义的数据传入Dataframe内即可:
import pandas as pd numb_list = { 'ID':[1,2,3,4], 'name':['苏凉','jake','佚名','Tom'], 'age':[22,18,25,16], 'QQ_num':[787991021,2544722208,12545654,58456] } df = pd.DataFrame(numb_list) df.to_excel('D:/Temp01/test.xlsx') print('创建成功!!')
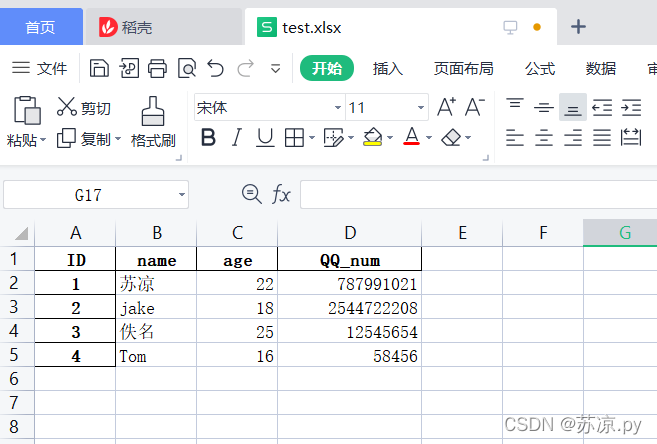
2.修改索引
利用set_index设置索引
df = df.set_index('ID')
(二)读取文件
pd.read_excel()常用参数说明:
首先,认识一下pd.read_excel(),函数的官方文档是这么说的:将Excel文件读取到pandas DataFrame中,系统默认支持‘xls’和‘xlsx’后缀的文件名,函数都可以处理,看一下这个函数的所有参数:

io参数
这个参数可以接受的有:字符串str,excel文件,或者路径对象,一般是路径+文件的名字,这是最重要的参数,必须传入:
pd.read_excel(r’F:\data\aa.xlsx’)
sheet_name
这个参数是指定excel表格的第几个sheet表,不指定默认是第一个sheet,对应的值是0,如果需要打开第二个sheet,可以将sheet_name=1,如果你的sheet自定义了名字,则把数字换成你名字即可;
header
这个参数是为了解决是否将前面的表头读入数据表中,如果header = 2,则说明指定位置是2的行作为列名,如果没有设置则说明是所有的数据作为数据,然后另外一行(系统默认输入0-n)作为列名字。
index_col
这个参数是默认是None,和header一样,可以填入数字,意思是设置第几列为行索引。
dtype
这个参数输入可以表示类型的名称字符或者字典,如果dtype=‘str’,则说明整个表格的书数据都转换成字符串的数据类型,如果输入的是字典,则dtype={‘列1’:‘str’,‘列2’:‘int’}则说明每个字段都可以指定不同的数据类型,上面的定义的意思就是第一列是字符串,第二列是整型。
1.导入excel表格
people = pd.read_excel('./People.xlsx') #导入excel表格
2.查看表格形状
print(people.shape) #查看有多少行多少列
3.查看列名
x = people.columns for i in x: print(i)

3.1 当第一行为空或有其他数据

遇到上述两种情况在读取列名时,pandas默认第一行为列名,当第一行为空时则需要设置header=某行
import pandas as pd people = pd.read_excel('./People.xlsx',header = 1) print(people.columns)
3.2 自定义列名
当打开的文件没有列名时,我们需要设置列名。

import pandas as pd people = pd.read_excel('./People.xlsx',header=None) # 自定义列名 people.columns=['ID','Type','Title','FirstName','MiddleName','LastName'] people.set_index('ID',inplace=True) print(people.columns) # 保存 people.to_excel('./test.xlsx') print('save success')
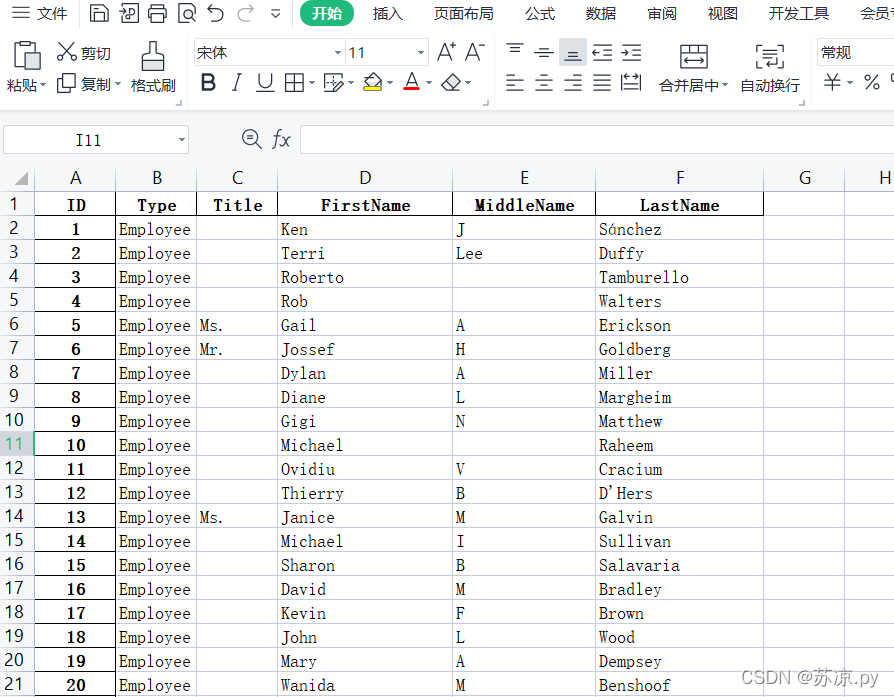
3.3 指定索引
在上面我们创建了一个test文件。当我们再次打开时,pandas会给我们重新创建一个索引,如下图:
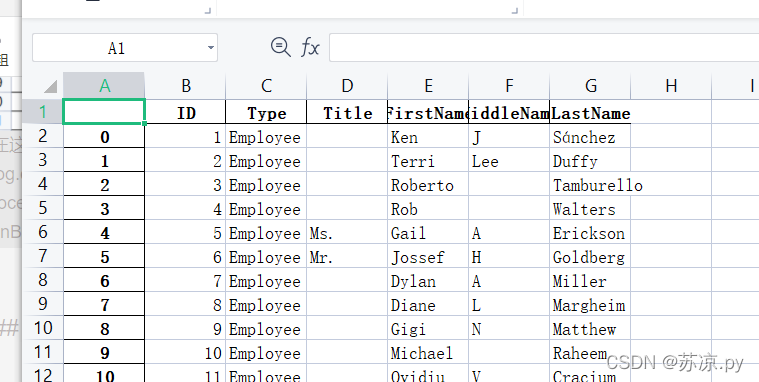
这时我们需要指定索引
import pandas as pd people = pd.read_excel('./test.xlsx',index_col="ID") people.to_excel('./test1.xlsx') print('save success')
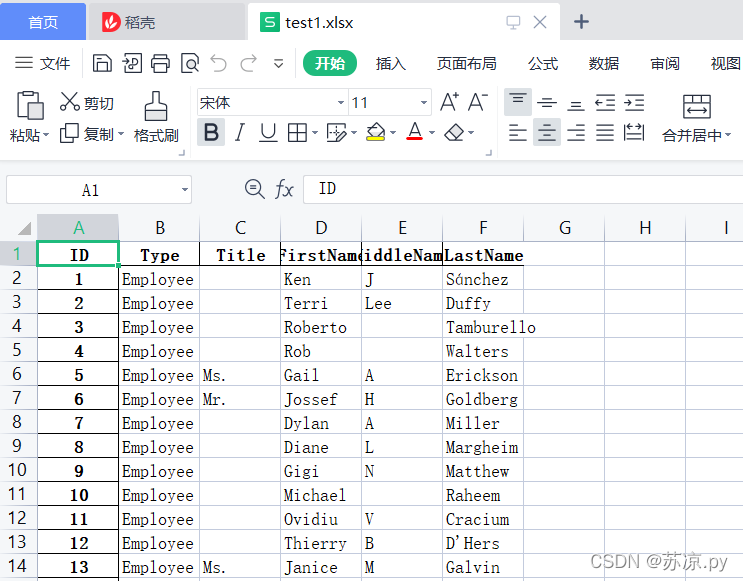
4.用Series创建行,列,单元格
import pandas as pd d1 = pd.Series([10,20,30],index=[1,2,3],name='a') d2 = pd.Series([40,50,60],index=[1,2,3],name='b') d3 = pd.Series([100,200,300],index=[2,3,4],name='c') df = pd.DataFrame({d1.name:d1,d2.name:d2,d3.name:d3}) df2 = pd.DataFrame([d1,d2,d3]) print(df) print('*'*100) print(df2)
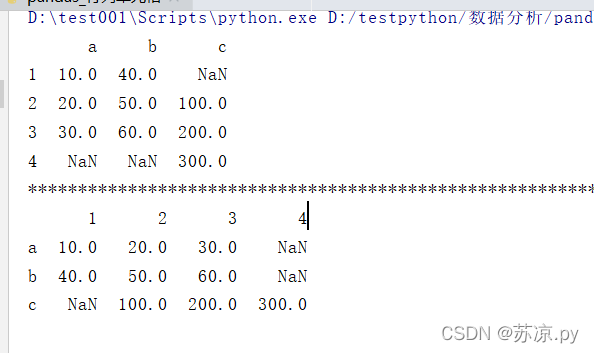
从上述结果可以看出通过Series创建的值传到Dataframe时需要用字典的形式,否则索引会自动转换为列。
(三)Pandas如何追加写入Excel
想要实现Excel的追加的主要思路为:将原有的数据先读出来,然后与需要存入的数据一并添加即可。
先创建一个excel文件:
import pandas as pd data = {'city': ['北京', '上海', '广州', '深圳'], '2018': [33105, 36011, 22859, 24221]} data = pd.DataFrame(data) data.to_excel('excel追加.xlsx', index=False)
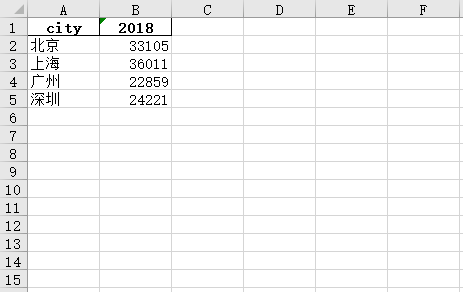
方法一:append()
import pandas as pd # 先将Excel中原有的数据读取出来 original_data = pd.read_excel('excel追加.xlsx') data2 = {'city': ['北京', '上海', '广州', '深圳'], '2018': ['a', 'b', 'c', 'd']} data2 = pd.DataFrame(data2) # 将新数据与旧数据合并起来 save_data = original_data.append(data2) save_data.to_excel('excel追加.xlsx', index=False)
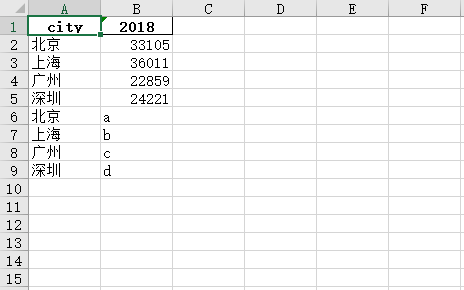
方法二:concat()
import pandas as pd # 先将Excel中原有的数据读取出来 original_data = pd.read_excel('excel追加.xlsx') data2 = {'city': ['北京', '上海', '广州', '深圳'], '2018': ['a', 'b', 'c', 'd']} data2 = pd.DataFrame(data2) # 将新数据与旧数据合并起来 save_data = pd.concat([original_data, data2], axis=0) save_data.to_excel('excel追加.xlsx', index=False)
使用ExcelWriter()类将数据导出至多个excel页签
在pandas中我们通常使用to_excel()方法将dataframe导出至Excel文件上,如果需要将多个不同的dataframe导出到同一个Excel文件的不同Sheet页,可以使用pandas.ExcelWriter()类来实现。
语法:
ExcelWriter(path, engine=None, date_format=None, datetime_format=None,mode=‘w’)
path:xls或xlsx文件的路径;
engine:可选参数,默认值为"xlwt",对于xls文件该参数值为"xlwt"有效,对于xlsx文件该参数值为"openpyxl"有效;
date_format:格式字符串,用于写入Excel文件的日期(例如“ YYYY-MM-DD”);
datetime_format:写入Excel文件的日期时间对象的格式字符串。 (例如“ YYYY-MM-DD HH:MM:SS”)
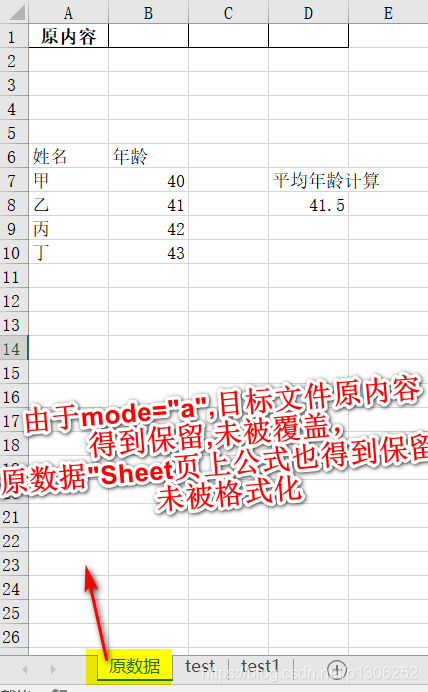
mode:可选参数,{‘w’, ‘a’}, 默认为 ‘w’,即擦除目标文件原内容,将dataframe覆盖式导出至目标Excel文件。当为’a’时,将dataframe追加导入至目标Excel文件,目标文件中原内容保留。此处需注意,如果为’a’,且导出的为xlsx文件,需将该参数修改为"openpyxl"。
import pandas as pd import numpy as np test=pd.DataFrame(np.arange(0,100).reshape([25,4])) test1=pd.DataFrame(np.arange(100,200).reshape([25,4])) writer = pd.ExcelWriter(r"C:\Users\user_name\Desktop\test.xlsx",engine="openpyxl",mode="a")#追加式导出,不覆目标文件盖原有内容 test.to_excel(writer,"test",index=False)#将test导出至名为test的Sheet页上 test1.to_excel(writer,"test1",index=False)#将test1导出至名为test1的Sheet页上 writer.save()
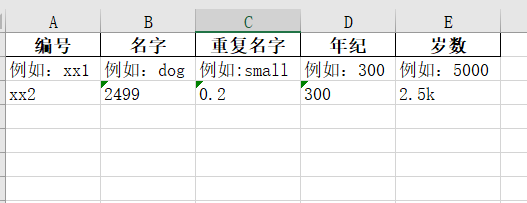
小试牛刀
import pandas as pd import os def save_excel(path,datamy): data = {'编号': ['例如:xx1'], '名字': ["例如:dog"], '重复名字': ["例如:small"], '年纪': ["例如:300"], '岁数': ["例如:5000"]} if os.path.exists(path)==False: data1 = pd.DataFrame(data) data1.to_excel(path, index=False) print("新建表格成功!") # sheet_name默认为0,即读取第一个sheet的数据 original_data = pd.read_excel(path, sheet_name=0,engine='openpyxl') # print(original_data.columns)#打印列名 if len(data)!=len(datamy): print("数据格式不太对") else: for i in range(len(data)): data.update({list(data.keys())[i]:[datamy[i]]}) data = pd.DataFrame(data) save_data = original_data.append(data) save_data.to_excel(path, index=False) print("Done!") if __name__=="__main__": # 每次都需要修改的路径 path = "测试.xlsx" datamy=["xx2","2499","0.2","300","2.5k"] save_excel(path,datamy)