







一、Kafka Stream 背景
1、Kafka Stream 简介
提供了对存储于Kafka内的树进行流式处理和分析的功能
Kafka Stream的特点:
-
Kafka Stream提供了一个非常简单而轻量的Library,它可以非常方便地嵌入任意Java应用中,也可以任意方式打包和部署
-
除了Kafka外,无任何外部依赖
-
充分利用Kafka分区机制实现水平扩展和顺序性保证
-
通过可容错的state store实现高效的状态操作(如windowed join和aggregation)
-
支持正好一次处理语义
-
提供记录级的处理能力,从而实现毫秒级的低延迟
-
支持基于事件时间的窗口操作,并且可处理晚到的数据(late arrival of records)
-
同时提供底层的处理原语Processor(类似于Storm的spout和bolt),以及高层抽象的DSL(类似于Spark的map/group/reduce)
2、流式计算
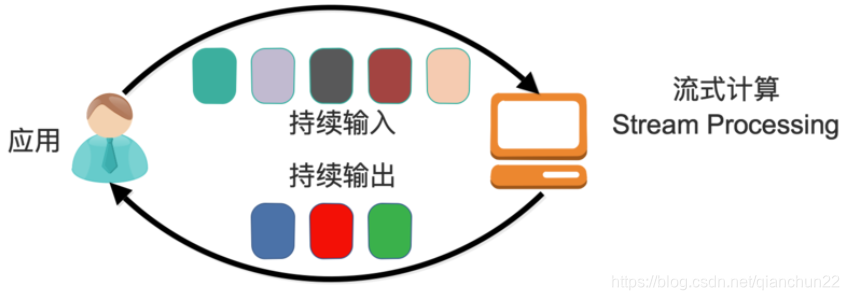
流式计算模型中,输入是持续的,意味着永远拿不到全量数据去做计算。同时,计算结果是持续输出的, 也即计算结果在时间上也是无界的。流式计算一般对实时性要求较高,同时一般是先定义目标计算,然后数据到来之后将计算逻辑应用于数据。同时为了提高计算效率,往往尽可能采用增量计算代替全量计算。
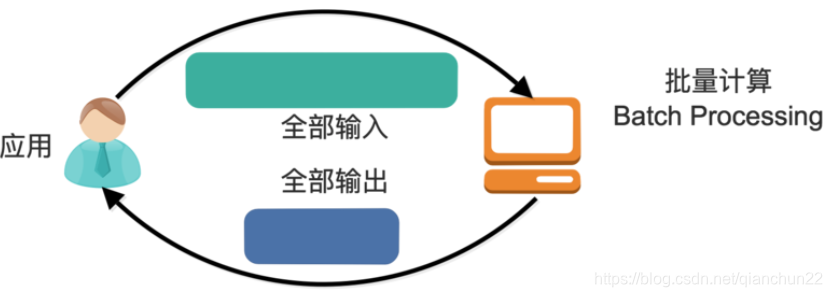
批量处理模型中,一般先有全量数据集,然后定义计算逻辑,并将计算应用于全量数据。特点是全量计算,并且计算结果一次性全量输出。
3、 为什么要有Kafka Stream
当前已经有非常多的流式处理系统,最知名且应用最多的开源流式处理系统有Spark Streaming和Apache Storm。Apache Storm发展多年,应用广泛,提供记录级别的处理能力,当前也支持SQL on Stream。而Spark Streaming基于Apache Spark,可以非常方便与图计算,SQL处理等集成,功能强大,对于熟悉其它Spark应用开发的用户而言使用门槛低。另外,目前主流的Hadoop发行版,如MapR,Cloudera和Hortonworks,都集成了Apache Storm和Apache Spark,使得部署更容易。
既然Apache Spark与Apache Storm拥用如此多的优势,那为何还需要Kafka Stream呢?笔者认为主要有如下原因:
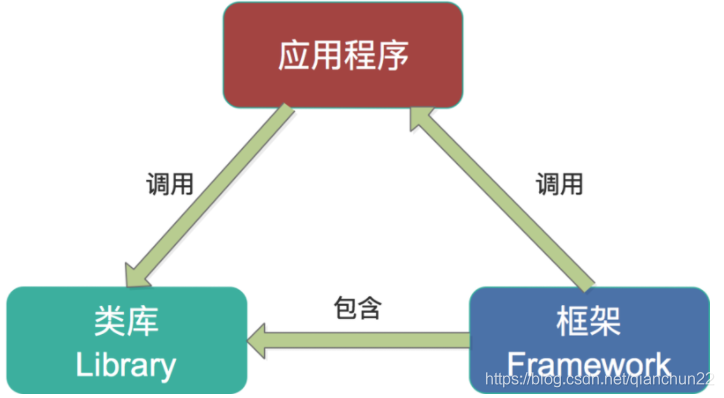
第一,Spark和Storm都是流式处理框架,而Kafka Stream提供的是一个基于Kafka的流式处理类库。框架要求开发者按照特定的方式去开发逻辑部分,供框架调用。开发者很难了解框架的具体运行方式,从而使得调试成本高,并且使用受限。而Kafka Stream作为流式处理类库,直接提供具体的类给开发者调用,整个应用的运行方式主要由开发者控制,方便使用和调试。
第二,虽然Cloudera与Hortonworks方便了Storm和Spark的部署,但是这些框架的部署仍然相对复杂。而Kafka Stream作为类库,可以非常方便的嵌入应用程序中,它对应用的打包和部署基本没有任何要求。更为重要的是,Kafka Stream充分利用了Kafka的分区机制和Consumer的Rebalance机制,使得Kafka Stream可以非常方便的水平扩展,并且各个实例可以使用不同的部署方式。具体来说,每个运行Kafka Stream的应用程序实例都包含了Kafka Consumer实例,多个同一应用的实例之间并行处理数据集。而不同实例之间的部署方式并不要求一致,比如部分实例可以运行在Web容器中,部分实例可运行在Docker或Kubernetes中。
第三,就流式处理系统而言,基本都支持Kafka作为数据源。例如Storm具有专门的kafka-spout,而Spark也提供专门的spark-streaming-kafka模块。事实上,Kafka基本上是主流的流式处理系统的标准数据源。换言之,大部分流式系统中都已部署了Kafka,此时使用Kafka Stream的成本非常低。
第四,使用Storm或Spark Streaming时,需要为框架本身的进程预留资源,如Storm的supervisor和Spark on YARN的node manager。即使对于应用实例而言,框架本身也会占用部分资源,如Spark Streaming需
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1202
1202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









