







安装了 Anaconda,下一步决定是否安装 TensorFlow CPU 版本或 GPU 版本。几乎所有计算机都支持 TensorFlow CPU 版本,而 GPU 版本则要求计算机有一个 CUDA compute capability 3.0 及以上的 NVDIA GPU 显卡(对于台式机而言最低配置为 NVDIA GTX 650)。
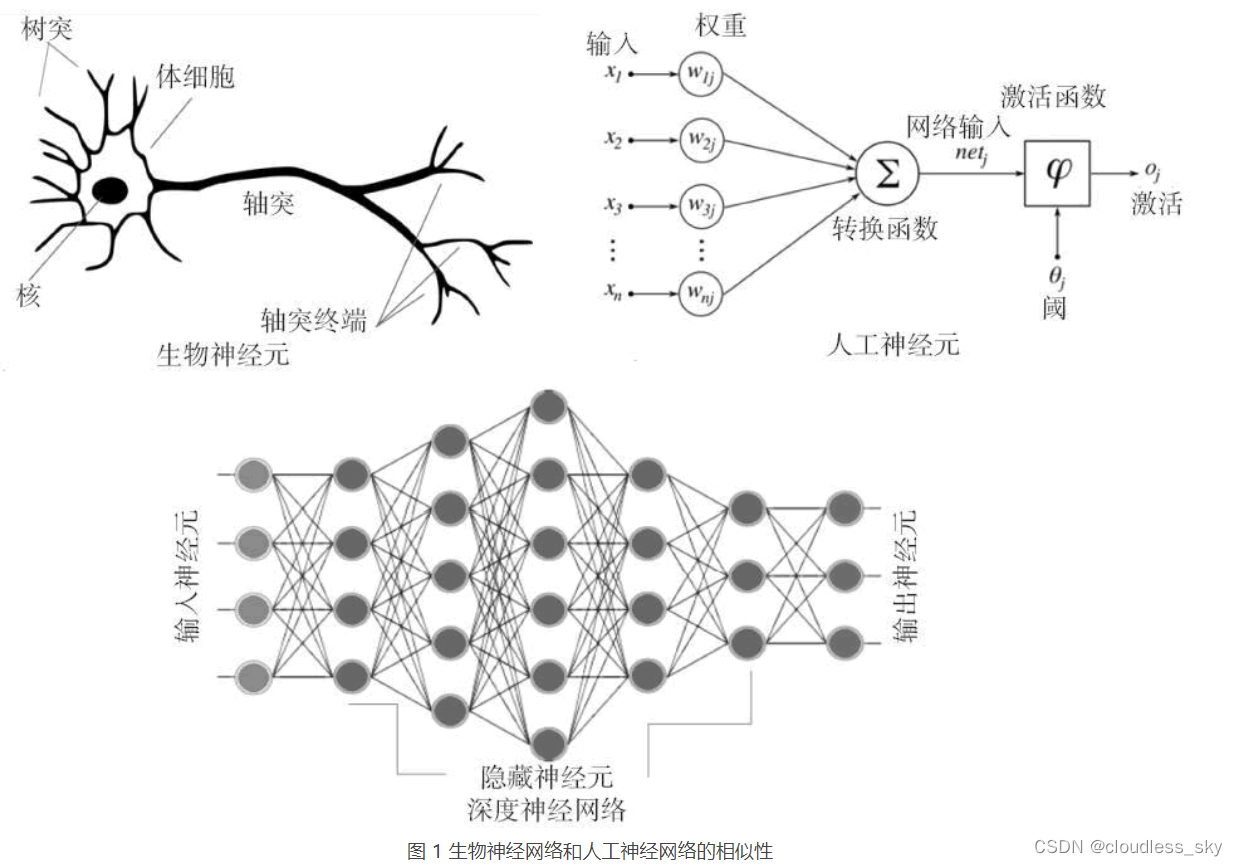
CPU 与 GPU 的对比:中央处理器(CPU)由对顺序串行处理优化的内核(4~8个)组成。图形处理器(GPU)具有大规模并行架构,由数千个更小且更有效的核芯(大致以千计)组成,能够同时处理多个任务。
对于 TensorFlow GPU 版本,需要先安装 CUDA toolkit 7.0 及以上版本、NVDIA【R】驱动程序和 cuDNN v3 或以上版本。Windows 系统还另外需要一些 DLL 文件,读者可以下载所需的 DLL 文件或安装 Visual Studio C++。
1、在win10或linux中安装tensorflow(cpu版本)
首先打来命令窗口,创建一个虚拟环境:(前提是已安装Anaconda3)
conda create -n tensorflow python=3.6
激活环境:
conda activate tensorflow
安装tensorflow:
conda install tensorflow
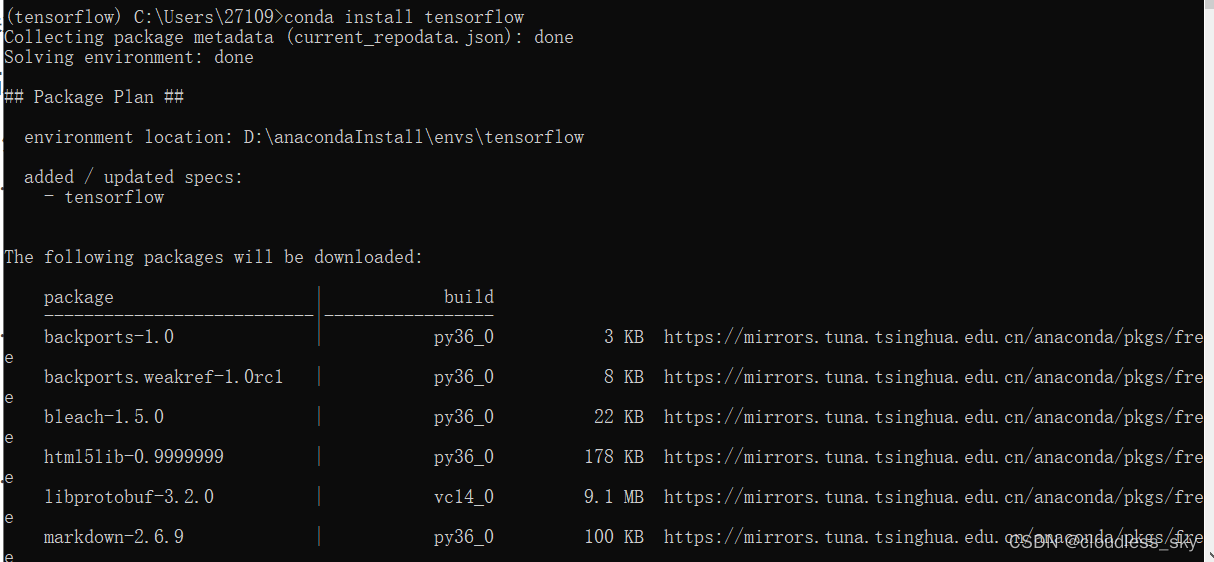
打开python编辑器:
python
尝试一段代码:(我在服务器linux系统的自创环境VAE_AGG中写的)

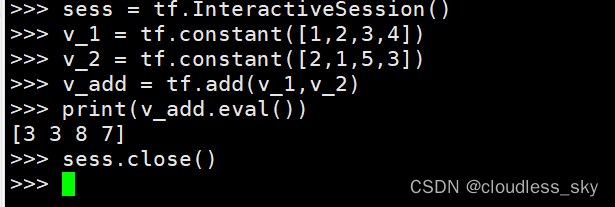
如果你正在使用 Jupyter Notebook 或者 Python shell 进行编程,使用 tf.InteractiveSession 将比 tf.Session 更方便。InteractiveSession 使自己成为默认会话,因此你可以使用 eval() 直接调用运行张量对象而不用显式调用会话。下面给出一个例子:
2、TensorFlow 支持 CPU 和 GPU。它也支持分布式计算。可以在一个或多个计算机系统的多个设备上使用 TensorFlow。
TensorFlow 将支持的 CPU 设备命名为“/device:CPU:0”(或“/cpu:0”),第 i 个 GPU 设备命名为“/device:GPU:I”(或“/gpu:I”)。
如前所述,GPU 比 CPU 要快得多,因为它们有许多小的内核。然而,在所有类型的计算中都使用 GPU 也并不一定都有速度上的优势。有时,比起使用 GPU 并行计算在速度上的优势收益,使用 GPU 的其他代价相对更为昂贵。
为了解决这个问题,TensorFlow 可以选择将计算放在一个特定的设备上。默认情况下,如果 CPU 和 GPU 都存在,TensorFlow 会优先考虑 GPU。
TensorFlow 将设备表示为字符串。
要验证 TensorFlow 是否确实在使用指定的设备(CPU 或 GPU),可以创建会话,并将 log_device_placement 标志设置为 True;如果你不确定设备,并希望 TensorFlow 选择现有和受支持的设备,则可以将 allow_soft_placement 标志设置为 True。
手动选择 CPU 进行操作:

手动选择 GPU 进行操作:

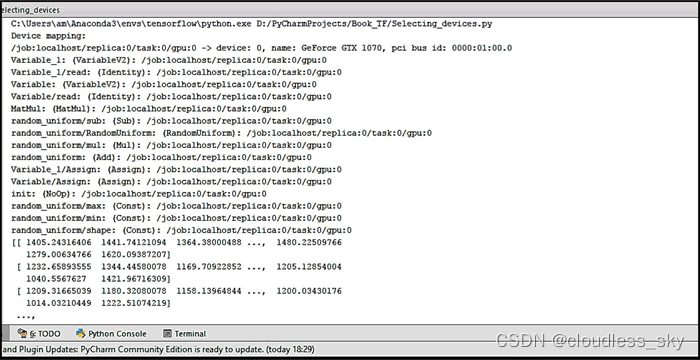
手动选择多个GPU:

3、深度学习之TensorFlow
TensorFlow 成为最受欢迎的深度学习库,原因如下:
TensorFlow 是一个强大的库,用于执行大规模的数值计算,如矩阵乘法或自动微分。这两个计算是实现和训练 DNN 所必需的。
TensorFlow 在后端使用 C/C++,这使得计算速度更快。
TensorFlow 有一个高级机器学习 API(tf.contrib.learn),可以更容易地配置、训练和评估大量的机器学习模型。
可以在 TensorFlow 上使用高级深度学习库 Keras。Keras 非常便于用户使用,并且可以轻松快速地进行原型设计。它支持各种 DNN,如RNN、CNN,甚至是两者的组合。
任何深度学习网络都由四个重要部分组成:数据集、定义模型(网络结构)、训练/学习和预测/评估。可以在 TensorFlow 中实现所有这些。
3.1 读取数据
在 TensorFlow 中可以通过三种方式读取数据:
通过feed_dict传递数据;
从文件中读取数据;
使用预加载的数据;
3.1.1 通过feed_dict传递数据
先来理解一下占位符:
Placeholder的中文意思就是占位符,用于在会话运行时动态提供输入数据 。Placeholder相当于 定义了一个位置 , 在这个位置上的数据在程序运行时再指定。
在以后的编程中我们可能会遇到这样的情况:在训练神经网络时需要 每次提供一个批量的训练样本 , 如果每次迭代选取的数据要通过常量表示,那么TensorFlow 的计算图会非常大 。因为 每增加一个常量,TensorFlow 都会在计算图中增加一个结点 ,所以说拥有几百万次迭代的神经网络会拥有极其庞大的计算图,而 占位符却可以解决这一点,它只会拥有占位符这一个结点 ,Placeholder机制的出现就是为了解决这个问题,我们在编程的时候 只需要把数据通过placeholder传入tensorflow计算图即可 ,我们通过下面的代码演示来这个方法:
import tensorflow as tf
a = tf.placeholder(tf.float32, shape=(2), name="a")
b = tf.placeholder(tf.float32, shape=(2), name="b")
output = tf.add(a, b)
with tf.Session() as sess:
print(sess.run(output, feed_dict={a: [7.0, 1.0], b: [2.0, 3.0]}))
# output:
# [9. 4.]
我们可以看到上面就是两个数组相加的结果。此外我们 在定义placeholder时 , 这个位置上的数据类型(dtype参数)是需要指定的 , 而且数据类型是不可以改变的 ,比如有(tf.float16,tf.float32)。 Placeholder中shape参数就是数据维度信息 ; 对于不确定的维度,可以填入None。
在上面定义的a和b是变量,这里把他们定义为一个placeholder,因此我们在运行Session.run()函数时,我们注意到一个feed_dict函数,这个 函数的用法是用来提供a和b的取值 。 feed_dict是一个字典,在字典中需要给出每个用到的占位符的取值,如果参与运算的placeholder没有被指定取值,那么程序就会报错。
Placeholder的目的是为了解决如何在有校的输入节点上实现高效地接受大量数据的问题。在上面的例子中如果把b从长度为2改为大小为n2的矩阵,矩阵的每一行为一个样例数据,这样向量相加之后的结果为n2的矩阵,也就是n个向量相加的结果了,矩阵的每一行就代表了一个向量相加的结果,下面我们展示一下n=3的例子:
import tensorflow as tf
a = tf.placeholder(tf.float32, shape=(2), name="a")
b = tf.placeholder(tf.float32, shape=(3, 2), name="b")
c = a + b
print(c)
with tf.Session() as sess:
print(sess.run(c, feed_dict={a: [7.0, 1.0], b: [[5.0, 2.0], [6.0, 5.0], [2.0, 3.0]]}))
# 输出结果:
# Tensor("add:0", shape=(3, 2), dtype=float32)
# [[12. 3.]
# [13. 6.]
# [ 9. 4.]]
从上面的样例中我们可以看到a+b的输出就是一个3x2的矩阵,最后得到的c的大小就是每一个向量相加的之后的值。
变量、常量和占位符之间的区别:
常量 : 在运行过程中值不会改变的单元 ,在TensorFlow中 无须进行初始化操作 ,
创建语句 : constant_ name =tf.constant(value)
变量:在运行过程中值会改变的单元 ,在TensorFlow中 须进行初始化操作 ;
创建语句 : name_variable =tf.Variable(value, name)
占位符 :TensorFlow中的Variable变量类型, 在定义时需要初始化 ,但有些变量定义时并不知道其数值,只有当真正开始运行程序时,才由外部输入,比如训练数据,这时候需要用到占位符。 占位变量是一种TensorFlow用来解决读取大量训练数据问题的机制,它允许你现在不用给它赋值,随着训练的开始,再把训练数据传送给训练网络学习。
其参数为数据的Type和Shape占位符Placeholder的函数接口如下:tf.placeholder(dtype, shape=None, name=None)
区别:常量不能改变,变量可以改变,且变量比常量增加了一个init初始化变量,并调用会话的run命令对参数进行初始化,使用了Variable变量类型,不进行初始化数值会出现运行错误。另外,常量存储在计算图的定义中,每次加载图时都会加载相关变量。即它们是占用内存的。另一方面,变量又是分开存储的。它们可以存储在参数服务器上。占位符不包含任何数据,因此不需要初始化。
通过feed_dict传递数据时,运行每个步骤时都会使用 run() 或 eval() 函数调用中的 feed_dict 参数来提供数据。这是在占位符的帮助下完成的,这个方法允许传递 Numpy 数组数据。可以使用 TensorFlow 的以下代码:

这里,x 和 y 是占位符;使用它们,在 feed_dict 的帮助下传递包含 X 值的数组和包含 Y 值的数组。
3.1.2 从文件中读取数据
当数据集非常大时,使用此方法可以确保不是所有数据都立即占用内存(例如 60 GB的 YouTube-8m 数据集)。从文件读取的过程可以通过以下步骤完成:

https://tensorflow.google.cn/tutorials/load_data/csv?hl=zh-cn
3.1.3 使用预加载的数据
当数据集很小时可以使用,可以在内存中完全加载。因此,可以将数据存储在常量或变量中。在使用变量时,需要将可训练标志设置为 False,以便训练时数据不会改变。

一般来说,数据被分为三部分:训练数据、验证数据和测试数据。
3.2 定义模型
建立描述网络结构的计算图。它涉及指定信息从一组神经元到另一组神经元的超参数、变量和占位符序列以及损失/错误函数。
3.3 训练/学习
在 DNN 中的学习通常基于梯度下降算法(后续章节将详细讨论),其目的是要找到训练变量(权重/偏置),将损失/错误函数最小化。这是通过初始化变量并使用 run() 来实现的:

3.4 评估模型
一旦网络被训练,通过 predict() 函数使用验证数据和测试数据来评估网络。这可以评价模型是否适合相应数据集,可以避免过拟合或欠拟合的问题。一旦模型取得让人满意的精度,就可以部署在生产环境中了。
4、TensorFlow 能够实现大部分神经网络的功能。但是,这还是不够的。对于预处理任务、序列化甚至绘图任务,还需要更多的 Python 包。














 659
659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









