
SQL:group高级用法

前言
分组函数(group)是数据分析师日常工作中常用到的函数之一了。分组是OLAP的基础,今天要介绍一些关于group by的(自以为)高级用法,可以有效的提高工作效率。
本文涉及到的函数或者思路:
- group__id; group with cube; rollup ; grouping sets
- sum(sum()) over (partition by A ) group by A,B
全文sql环境为Hive sql
一个数据集

现在有一个学生表t,三个字段分别是学生id(student_id), 学校(school),性别(gender), 常规来说,使用group函数可以轻松计算依据学校或者性别分组。
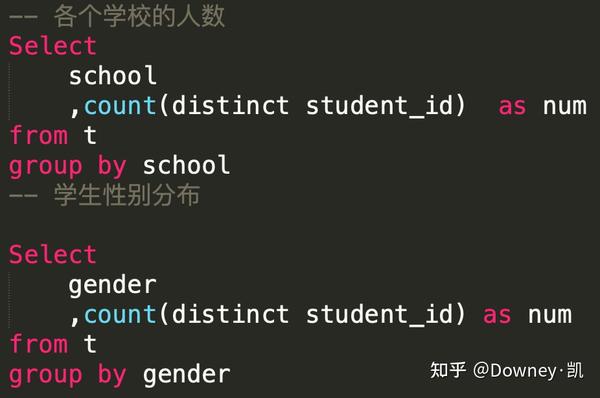

现在如何我们想同时求学校人数分布和学生性别分布应该怎么求呢? 最简单的办法,就是使用union函数,把所需要的行拼接在一起。这个代码有多么复杂呢。
union代码:
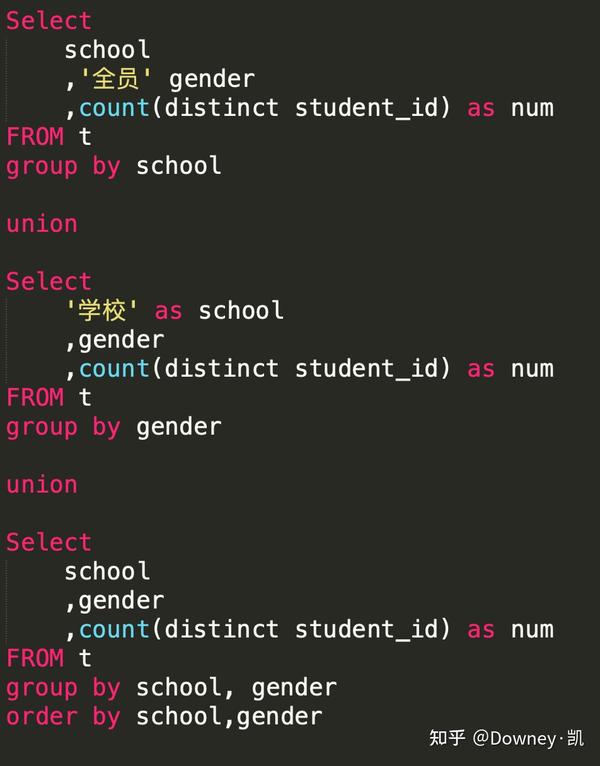
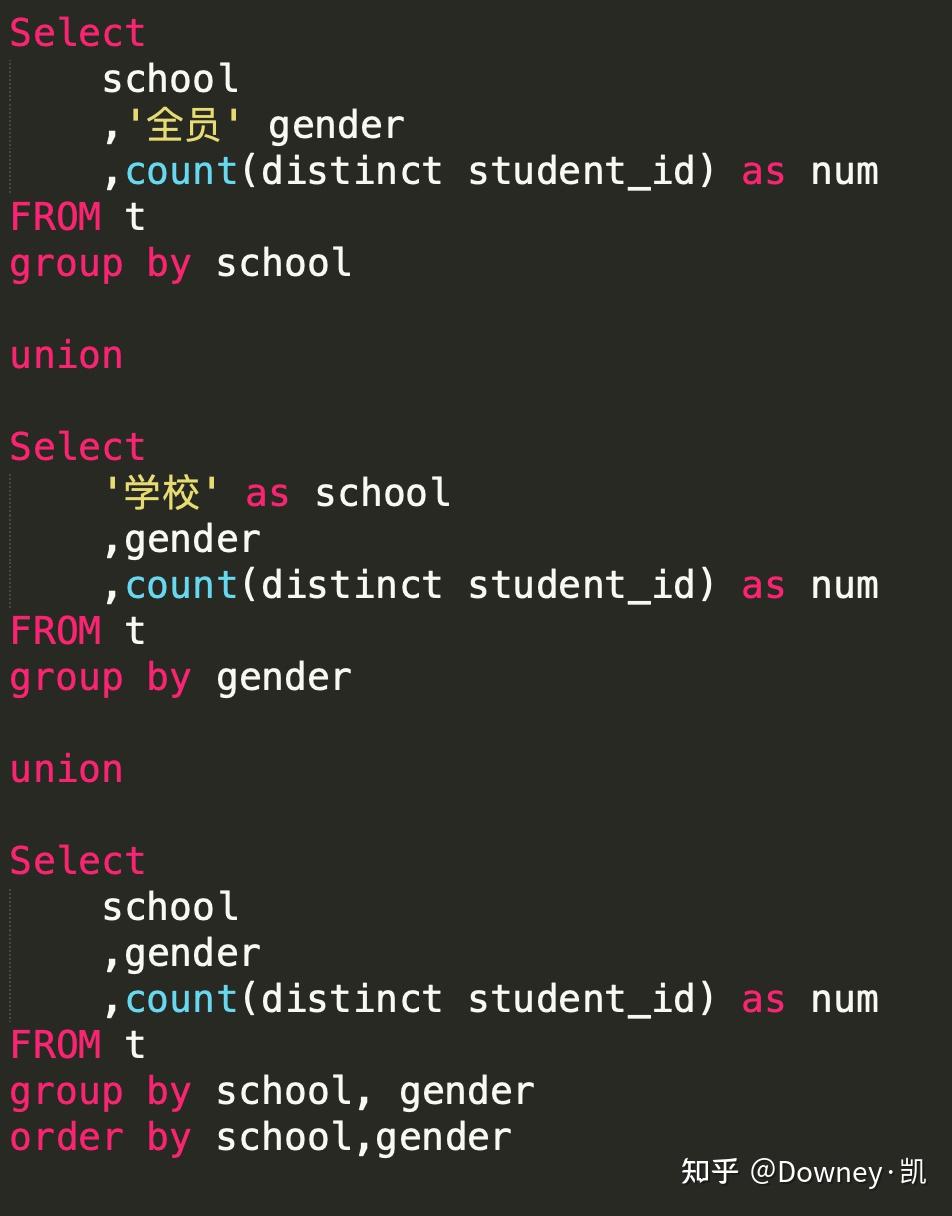
幸好group 给我们准备搭配的用法(看看精简了多少!)。使用group by A,B with Cube, 就可以各个分层的结果了。有两个要注意的问题,第一,在分组的时候,不涉及到的分层,会显示为Null,所以最好使用nvl函数进行默认值设置,第二,这里的计算逻辑,其实就是sql帮我们使用union 计算了,所有使用这类函数的时候,要注意计算量的问题。
with cube代码:


with cube 数据结果:

Cube,Rollup, Grouping sets 的区别
- CUBE:根据GROUP BY的维度的所有组合进行聚合。
- ROLLUP:是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合。
- GROUPING SETS:根据指定的维度组合进行聚合。
with rollup 数据结果:

with rollup 的结果与with cube 的区别是,在第二层“gender”分组的时候,没有对第一层总体“学校”数据进行进一步的分组(与with rollup 缺少最后两行)。
而grouping sets 本质是自定义,我们通过定义的方式,使用grouping sets 实现和with cube一样的功能
grouping sets 代码:(实现with cube功能)


除了上述提到的方法,还有一种奇技淫巧的方法,仅供参考:


这种方法的逻辑是,先使用group函数对数据进行聚合,然后在使用窗口函数进行分组求和。数据结果如下:

为什么搞的这么复杂?
可能还有朋友没有想明白,搞得这么复杂的原因是什么。直接分开求不好吗?这样做的目的,是为了计算分组占比的问题(是的,Excel透视表分分钟的事情,我只是单纯的用sql来解决而已)。我们使用group的时候,无法得到总体结果,必须使用with cube得到上一层的数据。对以上的代码稍作调整。
计算占比:

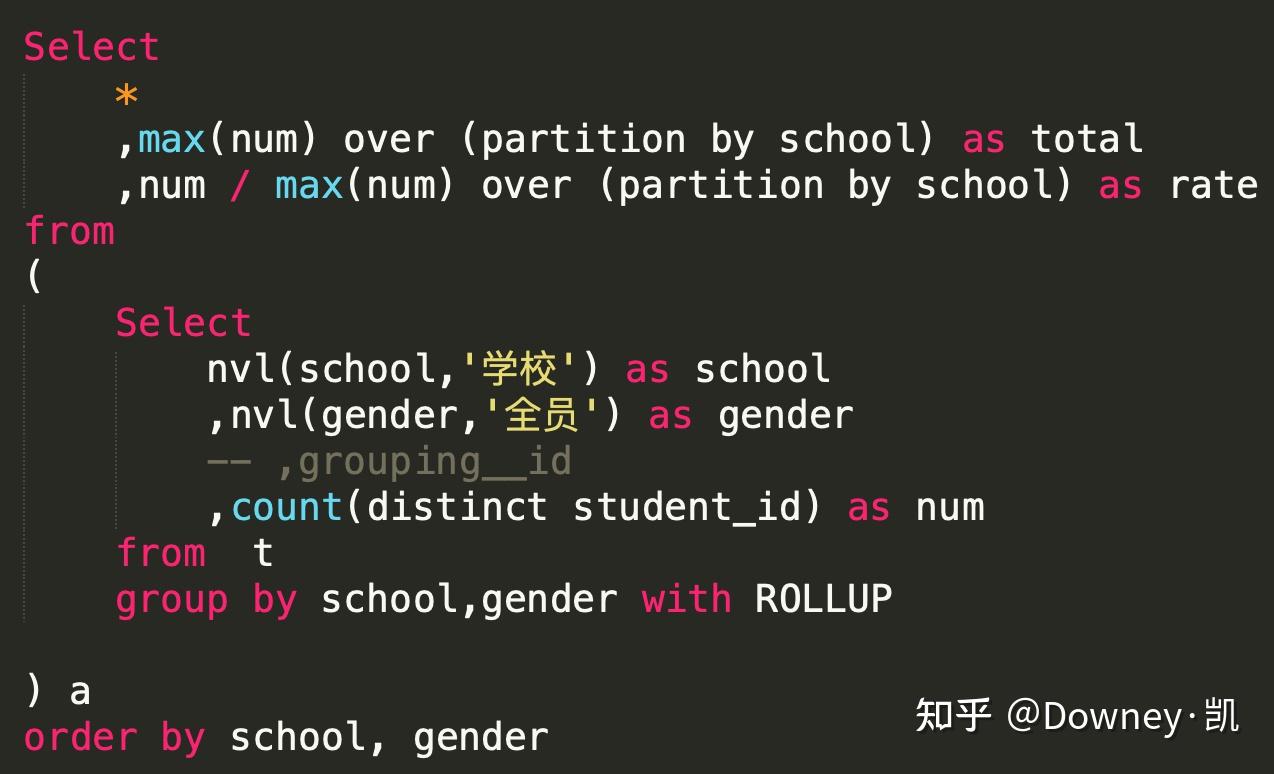
这个写法稍微有点复杂,解释一下:临时表a 计算出 group with rollup的结果后,会得到如下的结果,school每一层下,最大的是全员,即是分母。那之后的过程,可以使用sum(if)进行行专列,也可以采用我写的方法,用max()窗口函数找到最大值,求占比。



这样看起来,第二种写法牛逼哄哄的。
代码结果:

还有一个办法就是分两次group by ,然后使用left join 函数,这里就不演示了。
换一个例子

现在有学校学生社团的名单,要求求社团渗透的情况,上述的两种方法可以在这个case中使用吗?
答案是: 只有使用group with rollup的方法是可以的,而 第二种 sum(count(distinct student_id)) 窗口函数的方法是错误的。 这是为什么呢?
解: 因为 使用窗口函数的时候,会进行第一次聚合,在这次聚合的时候,每一个社团都会计算总人数,而计算学校总人数的时候,把“自然”的把社团人数加和,而我们知道,有一些“素质教育”的学生会参加多个社团,这样的计算方法,无疑就会加大分母,从而产生偏差。
后记
本文的目的是为了展示group with cube的使用方法,以及一些不常用到的窗口函数的功能,但是实际上,本文的很多计算都是可以在Excel中的数据透视表中完成的。大家在工作的过程中,要灵活使用Excel,Excel,yyds!