






背景
在微信小程序开发时,有时候请求的某些网页会出现乱码(尤其是爬取数据时),当我们在外部查看源码时,我们可以发现网页的编码格式不是utf-8
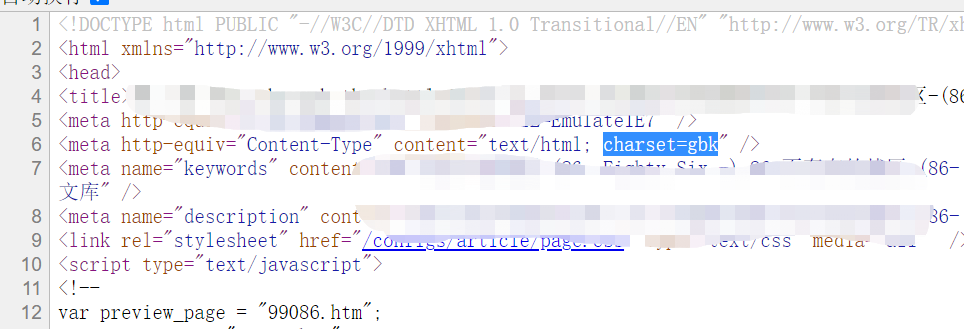
直接说解决方案
在请求求地址地址时,尝试加上charset=utf-8参数,例如https://www.xx.com/2231/84140.htm?charset=utf-8,如果ok则问题解决。
字符集
字符集(Charset):是一个系统支持的所有抽象字符的集合。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系。计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。
常见字符集
- iso-8859-1: 西欧的编码,英文编码
- gb2312: 中文编码
- utf-8 : 世界通用语言编码
- big5: 繁体中文编码
- euc-kr : 韩文编码
字符集有着十分有趣的历史(在我看来),可以自行搜索。
GBK与utf-8转换乱码问题的探究
本质:读取二进制的编码和最初将字符串转化成二进制的编码方式不一致。
GBK
采用单双字节变长编码,英文使用单字节编码,完全兼容ASCII字符编码,中文部分采用双字节编码。双字节其编码范围从8140至FEFE(剔除xx7F)。
单字节:00000000 - 01111111
双字节:10000001 01000000 - 11111110 11111110 (剔除******** 01111111)
单字节、双字节的区分通过高字节高位区分,单字节高位为0,双字节的高字节高位为1。
UTF-8
可变长字符编码,是unicode码的具体实现,UTF-8用1到6个字节编码Unicode字符。
当解码不符合当前的编码规则,会被解码成特殊字符,但此特殊字符再进行编码,是回不到最初的二进制的。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









