
R语言数据框的操作

小编:ice
在上一讲中,我们已经学习了R语言的变量类型与数据结构。在推文中我们说到一般最主要使用的数据结构就是数据框。今天我们专门来讲解一下数据框的基本操作,其他的几种数据结构我们将会在用到的时候顺带讲解。
在Python和R当中都有数据框。它是我们最常见的一种数据结构,其优势在于它能够容纳不同类型的变量。像这样:
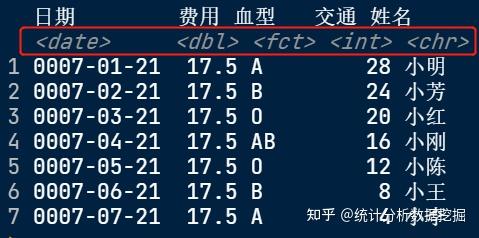

在这个数据框当中包括了日期型、浮点型、因子型、字符型和整型几种变量类型。(注意!我们常规数据输入一般都是指一行为一个案,一列为一个变量。)现在我们就将这个自编的数据集命名为df,来向大家展示数据框的各种操作。
1、数据索引
所以数据索引就是如何从数据框中取出个案或变量。有的文章或书中管这个叫做数据切片,方法有很多。归纳起来主要有两种,一种是按照序号,一种是按照名称。我们先看如何取一列变量。注意!这么取出来的东西还是一个数据框。
> df['姓名']
姓名
1 小明
2 小芳
3 小红
4 小刚
5 小陈
6 小王
7 小李
> df[5]
姓名
1 小明
2 小芳
3 小红
4 小刚
5 小陈
6 小王
7 小李现在取出一行。此时不带引号的4指的是行的序号,带引号的4,指的是行名。
请读者自己研究一下,如何将第5行第5列的‘小陈’取出来。
> df[4,]
日期 费用 血型 交通 姓名
4 0007-04-21 17.5 AB 16 小刚
> df['4',]
日期 费用 血型 交通 姓名
4 0007-04-21 17.5 AB 16 小刚此外你也可以使用$索引出对应的内容,但这样取出来的数据就已经不是数据框了。
> df$姓名
[1] "小明" "小芳" "小红" "小刚" "小陈" "小王" "小李"2、转置
转置是一个线性代数上常见的操作,可以理解为将数据框旋转90度,此时原来的行名变成了列名,原来的列名变成了现在的行名。转置的关键词为t(),括号中方被转置的数据框。


3、变量追加&数据集合并
实际操作当中经常会发现有时候会需要增加一个数据甚至追加一个数据集,或者新得到一个变量,想放进数据框中。我准备了三个示例数据框,依次起名为a、b、c。
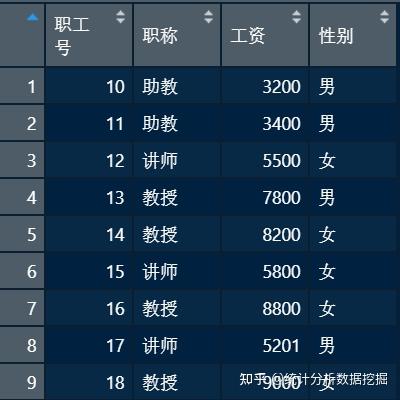
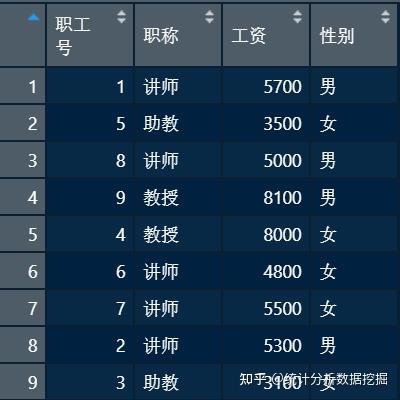
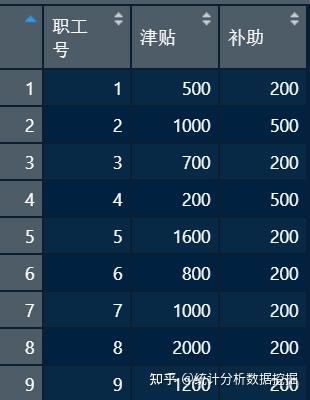
> rbind(a,b) # 追加个案,ab为两个数据框, 需要列名一致
职工号 职称 工资 性别
1 10 助教 3200 男
2 11 助教 3400 男
3 12 讲师 5500 女
4 13 教授 7800 男
5 14 教授 8200 女
6 15 讲师 5800 女
7 16 教授 8800 女
8 17 讲师 5201 男
9 18 教授 9000 女
10 1 讲师 5700 男
11 5 助教 3500 女
12 8 讲师 5000 男
13 9 教授 8100 男
14 4 教授 8000 女
15 6 讲师 4800 女
16 7 讲师 5500 女
17 2 讲师 5300 男
18 3 助教 3100 女
> cbind(b,c) # 追加变量,ab为两个数据框, 注意这个结果其实是有问题的,你发现了吗?
职工号 职称 工资 性别 职工号 津贴 补助
1 1 讲师 5700 男 1 500 200
2 5 助教 3500 女 2 1000 500
3 8 讲师 5000 男 3 700 200
4 9 教授 8100 男 4 200 500
5 4 教授 8000 女 5 1600 200
6 6 讲师 4800 女 6 800 200
7 7 讲师 5500 女 7 1000 200
8 2 讲师 5300 男 8 2000 200
9 3 助教 3100 女 9 1200 200以上操作当中,我们虽然将两个数据框b和c拼接在了一起,但在追加变量时我们需要注意看两个数据框的个案排序是否一致, 如果不一致需要将他们的顺序调整成一致。
当然我们也有其他的办法,在这里识别个案的主要依靠关键变量‘职工号’,因此我们可以考虑使用merge()函数。
> merge(b,c,by = '职工号') #以职工号为关键变量,拼接两个数据框,要求两个数据框中必须都有这个关键变量
职工号 职称 工资 性别 津贴 补助
1 1 讲师 5700 男 500 200
2 2 讲师 5300 男 1000 500
3 3 助教 3100 女 700 200
4 4 教授 8000 女 200 500
5 5 助教 3500 女 1600 200
6 6 讲师 4800 女 800 200
7 7 讲师 5500 女 1000 200
8 8 讲师 5000 男 2000 200
9 9 教授 8100 男 1200 2004、计算行数&列数
这个比较简单,没啥好说的。ncol(a) 是计算数据框a的列数,nrow(a)是计算数据框a的行数。这些看似简单的内容和后面的一些语句合起来,就能进行比较复杂的操作。比如进行循环时设定终点。所以万丈高楼平地起,我们还是要打好学习的基础,否则等到后面复杂的时候就看不懂了。
> ncol(a)
[1] 4
> nrow(a)
[1] 95、获取(更改)行名&列名
> row.names(a)
[1] "1" "2" "3" "4" "5" "6" "7" "8" "9"
> colnames(a)
[1] "职工号" "职称" "工资" "性别"
> row.names(a) <- c('A','B','C','D','E','F','G','H','I') #数据框a行名改成字母
> a
职工号 职称 工资 性别
A 10 助教 3200 男
B 11 助教 3400 男
C 12 讲师 5500 女
D 13 教授 7800 男
E 14 教授 8200 女
F 15 讲师 5800 女
G 16 教授 8800 女
H 17 讲师 5201 男
I 18 教授 9000 女
> colnames(a) <- c('春','夏','秋','冬')
> a
春 夏 秋 冬
A 10 助教 3200 男
B 11 助教 3400 男
C 12 讲师 5500 女
D 13 教授 7800 男
E 14 教授 8200 女
F 15 讲师 5800 女
G 16 教授 8800 女
H 17 讲师 5201 男
I 18 教授 9000 女
> rownames(a)=NULL # 清空行名,这时候刚刚改的字母行名会被清空变为默认的序数字序号
> a
春 夏 秋 冬
1 10 助教 3200 男
2 11 助教 3400 男
3 12 讲师 5500 女
4 13 教授 7800 男
5 14 教授 8200 女
6 15 讲师 5800 女
7 16 教授 8800 女
8 17 讲师 5201 男
9 18 教授 9000 女
> colnames(a)[4] <- '测试' # 单独为第四列改列名
> a
春 夏 秋 测试
1 10 助教 3200 男
2 11 助教 3400 男
3 12 讲师 5500 女
4 13 教授 7800 男
5 14 教授 8200 女
6 15 讲师 5800 女
7 16 教授 8800 女
8 17 讲师 5201 男
9 18 教授 9000 女6、创建一个空的数据框
初学者可能不知道创建空的数据框有什么意义。在以后我们需要将运算好的结果保存起来时,可以运算结果装到一个空的数据框当中,然后再将这个数据框输出到文本文件。
df <- data.frame(var1 = factor(), var2 = character(),var3 = numeric()) # 创建一个空的数据框df,里面包含三个变量,分别为因子型,字符型和数值型如果觉得有一些地方存在问题欢迎大家指出并在评论区留言。如果大家觉得这个教程还可以,请点赞、转发、分享。
更多内容分享请关注“统计分析与数据挖掘”公众号
“统计分析与数据挖掘”是一个分享以原创为主的数据挖掘、统计软件操作、生信分析、机器学习等内容的文章、教程和学习视频的公众号。创建的原目的是为了敦促学生学习相关知识和进行写作训练。如果您喜欢我们的推送内容,欢迎点赞、转发、收藏,您的支持将是我们深入学习的动力!