SQL练习题:连续出现N次

例题1:来源于猴子数据分析,图解SQL
下面是学生的成绩表(表名score,列名:学号、成绩),使用SQL查找所有至少连续出现3次的成绩。

例如,“成绩”这一列里84是连续出现3次的成绩。
【解题思路】
1.条件1:什么是连续出现3次?
学号连续,且分数相等
假设“学号”是按顺序排列的(如果不是,可以增加一列,这一列是按序号顺序排列的),所以每一学号与上一学号相差1。例如下图的3个学号是连续学号,他们之间的关系是:


2.条件2:成绩相等
如果这3个连续学号的成绩相等,就是题目要求的“至少连续出现3次的成绩”。
3.利用“自关联“的思路
自连接(自身连接)的本质是把一张表复制出多张一模一样的表来使用。SQL语法:
select 列明
from 表名 as 别名1,表名 as 别名2;步骤1)将成绩表(score)复制3个一样的表,分别命名为a、b、c


步骤2)我们需要找到这3个表中3个连续的学号,这个条件如下
a.学号 = b.学号-1 and b.学号 = c.学号-1


步骤3)还要让这3个学号连续的人“成绩相等”,这个条件如下
a.成绩 = b.成绩 and b.成绩 = c.成绩
将步骤2和步骤3的条件合并起来就是下面SQL里的where字句:
select *
from score as a,
score as b,
score as c
where a.学号 = b.学号 - 1
and b.学号 = c.学号 - 1
and a.成绩 = b.成绩
and b.成绩 = c.成绩;步骤4)前面步骤已经将连续3人相等的成绩找出,现在用distinct去掉自连接产生的重复数。最终SQL如下:
select distinct a.成绩 as 最终答案
from score as a,
score as b,
score as c
where a.学号 = b.学号 - 1
and b.学号 = c.学号 - 1
and a.成绩 = b.成绩
and b.成绩 = c.成绩;解法2:使用偏移函数 lead(...) over(...),添加辅助列,
select *,lead(成绩,1)over(order by 学号 ) as 成绩1,lead(成绩,2)over(order by 学号 ) as 成绩2
from 成绩表;
步骤2:对子句进行条件查询
select 成绩
from 子句
where 成绩=成绩1 and 成绩1=成绩2;步骤3:合并
select 成绩
from(
select *,lead(成绩,1)over(order by 学号 ) as 成绩1,lead(成绩,2)over(order by 学号 ) as 成绩2
from `成绩表`) as a
where 成绩=a.成绩1 and a.成绩1=a.成绩2;
例题2:【拼多多面试题】
两只篮球队进行了激烈的比赛,比分交替上升。比赛结束后,你有一张两队分数的明细表:该表记录了球队、球员号码、球员姓名、得分分数以及得分时间。现在球队要对比赛中表现突出的球员做出奖励。
问题:请你写一个sql语句统计出,连续三次(及以上)为球队得分的球员名单
【解题思路】


方法1:添加辅助列 lead () over(),求连续得分3次以上的球员姓名;


select *,lead(球员姓名,1)over( order by 得分时间) as 球员姓名1,lead(球员姓名,2)over( order by 得分时间) as 球员姓名2
from 分数表

步骤2:对子句进行条件限制
select distinct 球员姓名
from 子句
where 球员姓名=球员姓名1 and 球员姓名1=球员姓名2;步骤3:合并
select 球员姓名
from(
select *,lead(球员姓名,1)over( order by 得分时间) as 球员姓名1,lead(球员姓名,2)over( order by 得分时间) as 球员姓名2
from 分数表) as a
where 球员姓名=球员姓名1 and 球员姓名1=球员姓名2;

3.考查窗口函数lag、lead的用法
这两个函数一般用于计算差值,例如:
- 计算花费时间。例如:某数据是每个用户浏览网页的时间记录,将记录的时间错位之后,进行两列相减就可以得到每个用户浏览每个网页实际花费的时间。时间(连续N次,连续登陆N天,时隔多久)
- 计算与上次相比薪水涨幅。
连续出现N次的万能模板


select distinct 列1
from(
select 列1,
lead(列1,1) over(order by 序号) as 列2,
lead(列1,2) over(order by 序号) as 列3,
...
lead(列1,n-1) over(order by 列) as 列n,
from 表名
) as a
where (a.列1 = a.列2 and ... and a.列1 = a.列n);例题3:查找每月连续登陆2次的用户名单
解法1,思路:对用户id做用户偏移;若用户id=偏移后用户id,则表明连续登陆2次
select distinct date_format(日期,'%y%m'), a.用户id
from
(select *,lead(用户id,1) over(order by 日期) as 登录名
from 用户登陆记录表) as a
where 用户id=登录名

解法2,做辅助线思路,做出辅助列,并找出之间的规律
怎么能知道连续登陆用户呢?首先对用户连续登陆进行标记,也就是日期相同的打赏同一个标记(如下图)。


然后,用登陆日期的“天”和“每个月登陆顺序”的差值来做标记(如下图)。这样就可以知道,当登陆日期连续时,差值就是相同的,代表这些天用户是连续登陆。


根据上图的标记,怎么查询出每个用户每个月连续登陆的天数呢?可以用分组汇总,也就是分组(group by 月,用户id),统计(对分组后每个组计数就是连续登陆的天数 count)
2. 子查询
- 获取登陆日期的天,需要用到day()函数;
- 获取登录日期的月,需要用到month()函数;
- 获取每个月登陆顺序,这类问题属于“每个+排序”,用到窗口函数row_number();
- 筛选出2021年的数据。
把上面内容写成SQL就是:记为子查询t1
select 用户id,日期,month(日期) as 月,day(日期) as 天,
row_number()over(partition by month(日期),用户id order by 日期) as 每个月登陆顺序
from 用户登陆记录表
where 日期 between '2021-01-01' and '2021-12-31'

第二步:对辅助列找规律,天-每个月登陆顺序,连续登陆时的差值一致


select 月,日期,用户id,
(日 - 每个月登陆顺序) as 标记
from t1;

查询结果(把这个SQL记为子查询t2)
3. 汇总分析
1)分组汇总:查询每个月,每个用户,每一次连续登陆的天数。
也就是分组(group by 月,用户id,标记),统计(对分组后每个组计数就是连续登陆的天数 count)
select 月,用户id,标记,
count(*) as 连续登陆天数
from t2
group by 月,用户id,标记;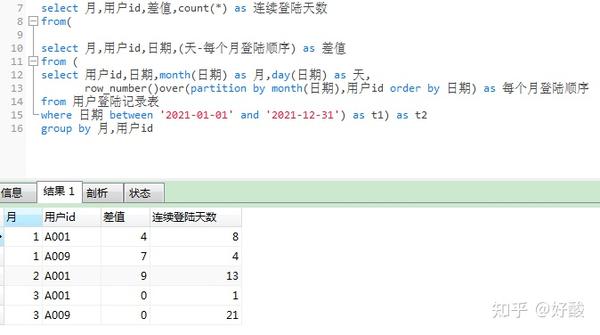

查询结果(把这个SQL记为子查询t3)
2)在上一步的基础上,用where子句筛选出连续2天都有登陆的用户:
select distinct 月,用户id
from t3
where 连续登陆天数>=2;

合并
select 月,用户id
from (
select 月,用户id,差值,count(*) as 连续登陆天数
from(
select 月,用户id,日期,(天-每个月登陆顺序) as 差值
from (
select 用户id,日期,month(日期) as 月,day(日期) as 天,
row_number()over(partition by month(日期),用户id order by 日期) as 每个月登陆顺序
from 用户登陆记录表
where 日期 between '2021-01-01' and '2021-12-31') as t1) as t2
group by 月,用户id) as t3
where 连续登陆天数>=2例题4:查询3月份以来,连续阅读5天及以上的用户名单
思路:使用偏移函数构造辅助列;
步骤一:构建辅助列
select *,lead(阅读日期,1)over (partition by 用户id order by 阅读日期 ) as 后面第1个日期,
lead(阅读日期,2)over (partition by 用户id order by 阅读日期 ) as 后面第2个日期,
lead(阅读日期,3)over (partition by 用户id order by 阅读日期 ) as 后面第3个日期,
lead(阅读日期,4)over (partition by 用户id order by 阅读日期 ) as 后面第4个日期
from 阅读记录表
where 日期>='2021-03-01'

步骤2:发现其中规律,如果是连续阅读,则日期上有如下规律:
使用date_sub函数,后面第1个日期-1=日期;后面第2个日期-2=日期...
select distinct id
from 子查询
where date_sub(后面第1个日期,interval 1 day)=阅读日期
and date_sub(后面第2个日期,interval 2 day)=阅读日期
and date_sub(后面第3个日期,interval 3 day)=阅读日期
and date_sub(后面第4个日期,interval 4 day)=阅读日期;步骤3:合并子查询
select distinct 用户id
from
(select *,lead(阅读日期,1)over (partition by 用户id order by 阅读日期 ) as 后面第1个日期,
lead(阅读日期,2)over (partition by 用户id order by 阅读日期 ) as 后面第2个日期,
lead(阅读日期,3)over (partition by 用户id order by 阅读日期 ) as 后面第3个日期,
lead(阅读日期,4)over (partition by 用户id order by 阅读日期 ) as 后面第4个日期
from 阅读记录表
where 阅读日期>='2021-03-01') as a
where date_sub(后面第1个日期,interval 1 day)=阅读日期
and date_sub(后面第2个日期,interval 2 day)=阅读日期
and date_sub(后面第3个日期,interval 3 day)=阅读日期
and date_sub(后面第4个日期,interval 4 day)=阅读日期;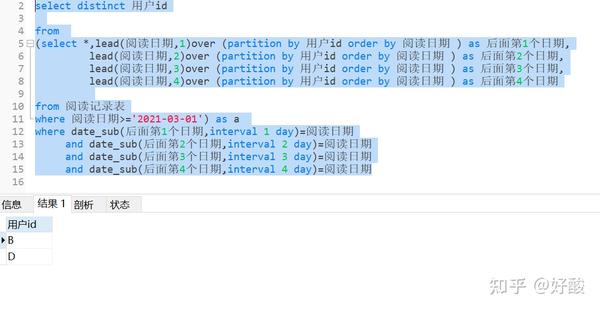

解法2:做2列辅助,并对2列辅助进行运算,发现其中关系
步骤1:做2列辅助,记为子查询a
select *,day(阅读日期) as 天,row_number()over (partition by 用户id order by 阅读日期) as rnk
from 阅读记录表
where 阅读日期>='2021-03-01'步骤2 :对辅助列进行运算,当连续阅读时,运算后的标志值一致
select 用户id,阅读日期,(天-cast(rnk as signed)) as 差值
from 子查询a

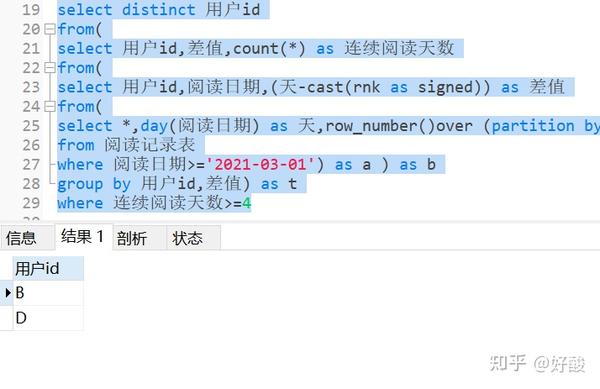
步骤3:对出现的次数进行计算,并求出次数>=4的用户id
select distinct 用户id
from(
select 用户id,差值,count(*) as 连续阅读天数
from(
select 用户id,阅读日期,(天-cast(rnk as signed)) as 差值
from(
select *,day(阅读日期) as 天,row_number()over (partition by 用户id order by 阅读日期) as rnk
from 阅读记录表
where 阅读日期>='2021-03-01') as a ) as b
group by 用户id,差值
where 连续阅读天数>=4