1 limit使用简介
limit子句是一个选择语句块的最后一个子句,它选取了行的一个子集,来限定中间结果的输出行数。limit子句表示了最前面和最后面被提取的行数。
通常情况下,Limit关键字可以接受一个或者两个数字参数。需要注意的是,这个参数必须是一个整数常量。如果用户给定两个参数,则第一个参数表示第一个返回记录行的偏移量,第二个参数则表示返回记录行的最大数据。另外需要提醒的是,初始记录行的偏移量是0,而不是1。
虽然使用了Limit语句来限制返回的记录数,从而可以提高应用程序的工作效率。但是其也会给系统的性能带来一些负面影响。如可能会导致全表扫描等等。如果数据库管理员决定使用Limit子句来指定需要显示的记录数,那么最好能够最大限度的使用索引,以避免全表扫描,提高工作效率。
2 基本语法
- SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset
LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。LIMIT 接受一个或两个数字参数。参数必须是一个整数常量。如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。初始记录行的偏移量是 0(而不是 1): 为了与 PostgreSQL 兼容,MySQL 也支持句法: LIMIT # OFFSET #。
3 创建测试表及数据
3.1 创建测试表
- CREATE TABLE PLAYERS
- (PLAYERNO INTEGER NOT NULL,
- NAME CHAR(15) NOT NULL,
- INITIALS CHAR(3) NOT NULL,
- BIRTH_DATE DATE ,
- SEX CHAR(1) NOT NULL,
- JOINED SMALLINT NOT NULL,
- STREET VARCHAR(30) NOT NULL,
- HOUSENO CHAR(4) ,
- POSTCODE CHAR(6) ,
- TOWN VARCHAR(30) NOT NULL,
- PHONENO CHAR(13) ,
- LEAGUENO CHAR(4) ,
- PRIMARY KEY (PLAYERNO) );
注:测试表为球员信息。
3.2 插入测试数据
- INSERT INTO PLAYERS VALUES (2, 'Everett', 'R', '1948-09-01', 'M', 1975, 'Stoney Road','43', '3575NH', 'Stratford', '070-237893', '2411');
- INSERT INTO PLAYERS VALUES (6, 'Parmenter', 'R', '1964-06-25', 'M', 1977, 'Haseltine Lane','80', '1234KK', 'Stratford', '070-476537', '8467');
- INSERT INTO PLAYERS VALUES (7, 'Wise', 'GWS', '1963-05-11', 'M', 1981, 'Edgecombe Way','39', '9758VB', 'Stratford', '070-347689', NULL);
- INSERT INTO PLAYERS VALUES (8, 'Newcastle', 'B', '1962-07-08', 'F', 1980, 'Station Road','4', '6584WO', 'Inglewood', '070-458458', '2983');
- INSERT INTO PLAYERS VALUES (27, 'Collins', 'DD', '1964-12-28', 'F', 1983, 'Long Drive','804', '8457DK', 'Eltham', '079-234857', '2513');
- INSERT INTO PLAYERS VALUES (28, 'Collins', 'C', '1963-06-22', 'F', 1983, 'Old Main Road','10', '1294QK', 'Midhurst', '010-659599', NULL);
- INSERT INTO PLAYERS VALUES (39, 'Bishop', 'D', '1956-10-29', 'M', 1980, 'Eaton Square','78', '9629CD', 'Stratford', '070-393435', NULL);
- INSERT INTO PLAYERS VALUES (44, 'Baker', 'E', '1963-01-09', 'M', 1980, 'Lewis Street','23', '4444LJ', 'Inglewood', '070-368753', '1124');
- INSERT INTO PLAYERS VALUES (57, 'Brown', 'M', '1971-08-17', 'M', 1985, 'Edgecombe Way','16', '4377CB', 'Stratford', '070-473458', '6409');
- INSERT INTO PLAYERS VALUES (83, 'Hope', 'PK', '1956-11-11', 'M', 1982, 'Magdalene Road','16A', '1812UP', 'Stratford', '070-353548', '1608');
- INSERT INTO PLAYERS VALUES (95, 'Miller', 'P', '1963-05-14', 'M', 1972, 'High Street','33A', '5746OP', 'Douglas', '070-867564', NULL);
- INSERT INTO PLAYERS VALUES (100, 'Parmenter', 'P', '1963-02-28', 'M', 1979, 'Haseltine Lane','80', '6494SG', 'Stratford', '070-494593', '6524');
- INSERT INTO PLAYERS VALUES (104, 'Moorman', 'D', '1970-05-10', 'F', 1984, 'Stout Street','65', '9437AO', 'Eltham', '079-987571', '7060');
- INSERT INTO PLAYERS VALUES (112, 'Bailey', 'IP', '1963-10-01', 'F', 1984, 'Vixen Road','8', '6392LK', 'Plymouth', '010-548745', '1319');
4 limit简单实例
4.1 实例1
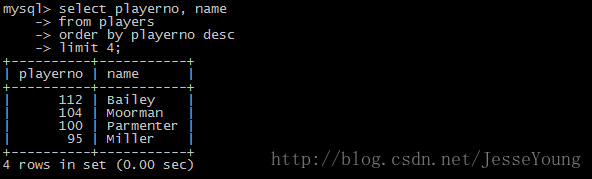
获取前四个最大球员的号码和名字。
- select playerno, name
- from players
- order by playerno desc
- limit 4;
 4.2 实例2
4.2 实例2
获取加入球队最早的2个球员的号码和名字。
- select playerno, name
- from players
- order by joined desc
- limit 2;

注:112号球员和104号球员都是1984年加入足球俱乐部的,因为最终输出为两个球员,57号球员是1985年加入的,肯定会输出,对于年份重复的112和104号球员MySQL会随机选取一个。
4.3 实例3
获取加入球队最早的2个球员的号码和名字,如果有年份重复的,只显示球员号最小的球员。
- select playerno, name
- from players
- order by joined desc, playerno asc
- limit 2;
 注:如果不指定重复年份加入俱乐部队员的选取规则的话,mysql会按照默认规则选取,指定的话如playerno asc,则按球员号从小到大选取。
注:如果不指定重复年份加入俱乐部队员的选取规则的话,mysql会按照默认规则选取,指定的话如playerno asc,则按球员号从小到大选取。
5 limit与子查询
limit也可用在出现在子查询中的语句块块儿中。
- select * from
- (select playerno, name
- from players
- order by joined desc, playerno asc
- limit 2) as T
- order by playerno desc;

6 limit偏移量
通常limit子句用来选择列表头部或尾部,添加一个偏移量则可跳过几行。添加偏移量有两种方式,分别是LIMIT [offset,] rows 或LIMIT rows OFFSET offset,推荐使用第二种,它更明确地表示了要显示的行数和偏移的行数。
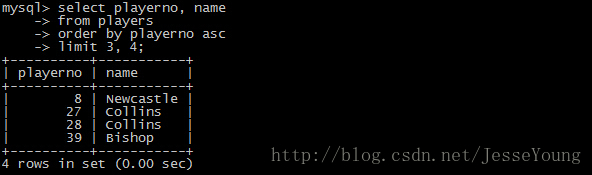
- select playerno, name
- from players
- order by playerno asc
- limit 3, 4;
或者
- select playerno, name
- from players
- order by playerno asc
- limit 4 offset 3;
7 limit 可选选项sql_calc_found_rows
我们可以通过limit指定我们需要输出的行,加上选项sql_calc_found_rows的话,可以在后台统计出来总的行数,如我们只需要显示4行,并统计下总的行数,可通过select found_rows()获得。
- mysql> select sql_calc_found_rows playerno, name
- -> from players
- -> order by playerno desc
- -> limit 4;
- +
- | playerno | name |
- +
- | 112 | Bailey |
- | 104 | Moorman |
- | 100 | Parmenter |
- | 95 | Miller |
- +
- mysql> select found_rows();
- +
- | found_rows() |
- +
- | 14 |
- +
8 limit优化
8.1 limit 0子句
根据Limit关键字的定义,如果参数为0的话,则其返回的是空记录。在实际工作中,灵活使用这个0参数,能够给我们带来很大的收获。
如现在数据库工程师想要确认一下某个查询语句的有效性,如果直接运行这个查询语句,需要等待其返回的记录。如果涉及的纪录数量比较多,或者运算逻辑比较复杂,那么需要等到比较长的时间。此时就可以在Select查询语句中,使用Limit 0子句。只要查询语句没有语法上的错误,这就可以让数据库快速的返回一个空集合。从而帮助数据库设计人员迅速的判断查询语句的有效性。另外这个空集和中还会返回某个表的各个字段的字段名称。即通过这个Limit 0子句还可以查询某个表的表结构。
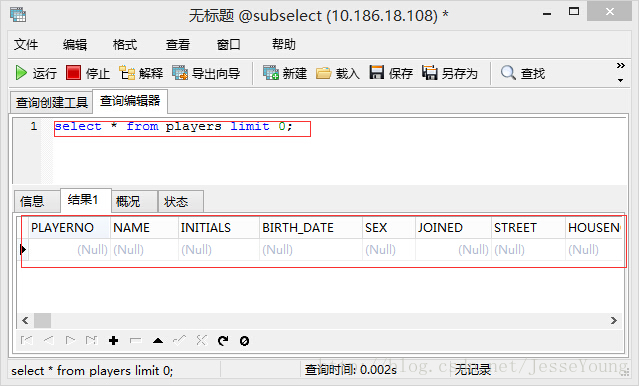
可见灵活应用limit 0子句,确实能够给我们带来不小的收益。不过需要注意的是,在某些特定的场合下,这个子句可能不会奏效。如通常情况下,在Monitor工作环境中不支持这个Limit 0子句。此时结果只会显示Empty Set,而不是我们所需要的结果。

8.2 limit与distinct
Distinct关键字主要用来过滤重复的记录。而Limit关键字则主要用来指定记录所返回的行数。如果这两个关键字共同使用时,如Limit的参数为50,则数据库返回50条不重复的记录数。然后后续的查询就会停止。如果查询的记录中有重复记录,则数据库查询的实际数量往往要比Limit关键字所指定的数量要多。
- mysql> select joined from players;
- +
- | joined |
- +
- | 1975 |
- | 1977 |
- | 1981 |
- | 1980 |
- | 1983 |
- | 1983 |
- | 1980 |
- | 1980 |
- | 1985 |
- | 1982 |
- | 1972 |
- | 1979 |
- | 1984 |
- | 1984 |
- +
注:全部查询行数为14
- mysql> select joined from players limit 6;
- +
- | joined |
- +
- | 1975 |
- | 1977 |
- | 1981 |
- | 1980 |
- | 1983 |
- | 1983 |
- +
注:查询行数为6
- mysql> select distinct joined from players limit 6;
- +
- | joined |
- +
- | 1975 |
- | 1977 |
- | 1981 |
- | 1980 |
- | 1983 |
- | 1985 |
- +
注:查询行数为9
8.3 limit分页查询优化
MySQL的limit给分页带来了极大的方便,但数据量一大的时候,limit的性能就急剧下降。
8.3.1 offset比较小的时候,直接使用limit。
- select name
- from players
- order by playerno
- limit 5, 6;

8.3.2 offset比较大的时候,使用子查询优化。
- select name
- from players
- where playerno >=
- (select playerno
- from players
- order by playerno
- limit 5, 1)
- limit 6;
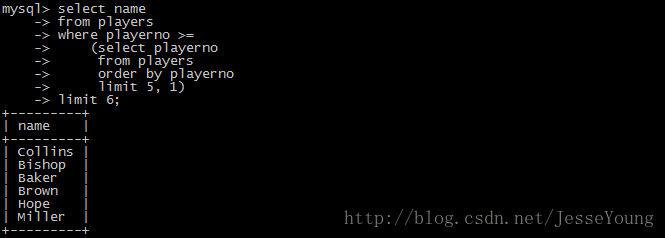
注:首先获取到offset的id然后直接使用limit size来获取数据。
8.4 limit与索引
如果数据库管理员决定使用Limit子句来指定需要显示的记录数,那么最好能够最大限度的使用索引,以避免全表扫描,提高工作效率。即当数据库选择做完整的表扫描时,可以在某些情况下使用索引。
如现在数据库管理员决定将Limit子句与Order BY子句一起使用。数据库一旦找到了排序结果的第一个RowCount行,则系统将会结束排序,而并不会对整个表进行排序。如果单独使用Order By子句的话,则会对整个表进行排序。虽然如此,但是排序必定要浪费一定的时间。此时数据库管理员如果决定使用索引,则可以在很大程度上提高这个查询的效率。
8.5 limit与group by
Group By关键字主要用来对数据进行分类汇总。不过在分类汇总之前,往往需要对数据先进性排序。而Limit语句用来指定显示的结果数量时,往往也需要涉及到纪录的分类汇总与排序的问题。如现在一个学校成绩管理系统中,需要对学生的总分进行排序。即先对学生各科成绩进行汇总,然后显示其排名为前50的纪录。此时就需要同时用到Group By子句和Limit子句。其实从这个案例中我们也可以看出,这两个子句相互依赖的特性。正是因为这种特性(经常相互结合使用),为此结合Group By子句可以提高Limit的查询效率。
这主要是因为两者如果一起使用的话,Limit关键字将不会再重复计算任何不必要的Group By的值。换句话说,在某些情况下,Group By子句能够通过顺序来读取键或者在键上做排序来解决分类汇总时的排序问题,然后再计算摘要直到关键字的值的改变为止。如此的话,两个子句所需要做的一些共同性的工作,只要做一次即可。这就可以从另外一次角度用来提高应用系统的性能。相比先做一个视图对数据进行分类汇总的运算,再使用一个查询语句来抽取特定数量的记录,效率就要高一点。因为后者是将两个子句分开来使用,就无法享受到结合使用所体现的优势。






















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









