GCN模型的扩展和应用中,哪些模型依赖于拉普拉斯矩阵?

需要用到的拉普拉斯矩阵的GCN的模型扩展如下:
Edge-embedding边嵌入扩展方向:神经关系推断 NRI。
关系数据扩展方向:RGCN,CompGCN。
推荐系统方向,KGCN,基于知识图谱的推荐系统(KG+GCN)。
自注意力方向,Monet,EGCN。
图像方向,基于动态骨骼的动作识别方法ST-GCN(时空图卷积网络模型)。
GCN属于GNN的一类,是采用卷积操作的图神经网络。这种方法属于一类采用图卷积的神经网络,可以应用于图嵌入的方法中。
三者的关系可以用下图来表示:
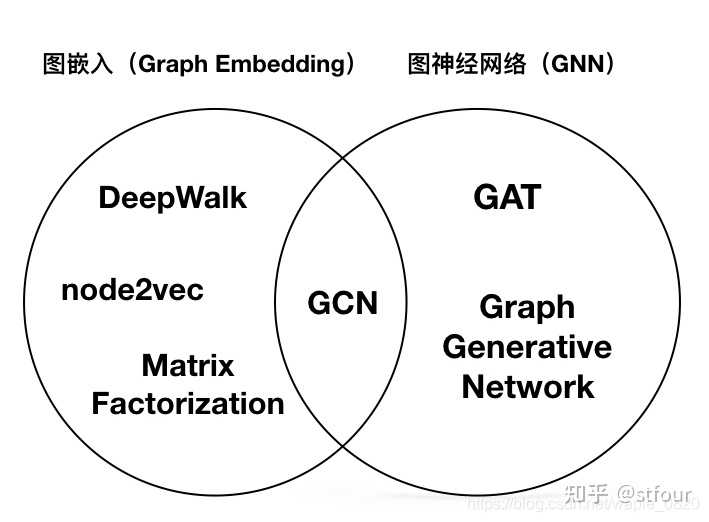

这里重点介绍作为GCN基础的图嵌入中所用到的拉普拉斯矩阵。
Graph 存在于各种各样的现实场景中,如社交网络social network,引文网络 citation network,知识图谱 knowledge graph 等。大多数现有的图分析方法都遭受很高的计算代价和空间成本,而 graph embedding 提供了一种有效的方法来解决图分析问题。具体而言 graph embedding 将图映射到保留了图信息的低维空间。
论文 《A Comprehensive Survey of Graph Embedding:Problems, Techniques and Applications》 研究了现有的 graph embedding 方法,对这些 graph embedding 方法技术做了全面的综述。其中,矩阵分解主要用于两种场景:嵌入由非关系数据构成的图的顶点 embedding,这是拉普拉斯特征图的典型应用场景;嵌入同质图。
图拉普拉斯特征图分解的思想是:图拉普拉斯特征图分解保留的图属性为成对顶点相似性,因此如果两个相距较远的顶点(通过 embedding 距离衡量)的相似度较大,则给予较大的惩罚。假设embedding的维度为一维,即将每个顶点映射为一个整数。基于上述洞察insight,则最优化embedding为:


其中:
- y_i 为顶点 v_i 的一维
embedding, \vec{\bold{y}} 为所有顶点一维embedding组成的embedding向量。 - W_{i,j } 为顶点v_i,v_j之间的成对相似性, \bold{W} 为图中顶点之间的相似度矩阵。通常选择 \bold W 为图的邻接矩阵(无权图)或者带权重的邻接矩阵(带权图)。
- \bold L = \bold D - \bold W 为图拉普拉斯矩阵,其中 \bold D = ding(D_i) 为对角矩阵, D_i = \sum_{j \ne i} {W_{i,j}} 为其对角线元素。
在图分析任务中也用到拉普拉斯矩阵。图分析大致分为以下四类:顶点分类、链接预测、聚类、可视化。
- 顶点分类目标是基于网络结构以及部分标记顶点来预测剩余顶点的标签。
- 链接预测目标是预测缺失的链接、或未来可能发生的链接。
- 聚类目标是寻找相似顶点的集合,并将它们聚在一起。
- 可视化目标是洞察网络结构。
- 基于分解的方法以矩阵形式表示顶点之间的连接,然后将该矩阵分解从而获得顶点
embedding。用于表示连接的矩阵可以为顶点邻接矩阵、图拉普拉斯矩阵、顶点转移概率矩阵、Katz相似度矩阵。
矩阵分解的方法因矩阵属性而异。如果获得的矩阵是半正定的(例如,图拉普拉斯矩阵),则可以使用特征值分解eigenvalue decomposition。对于非结构化矩阵unstructured matrices,可以使用梯度下降法在线性时间内获得embedding。
Laplacian Eigenmaps :拉普拉斯特征图Laplacian Eigenmaps 旨在当 W_{i,j } 较高时两个顶点的 embedding 距离较近。具体而言,其目标函数为:
\mathcal{L} (\bold Y) = \frac1{2} \sum_{i,j} W_{i,j} \| \vec{\bold y_i} - \vec{\bold y_j} \|_2 ^2 = tr(\bold Y^T \bold L \bold Y)
可以看到当 \bold Y = 0 即全零矩阵时,目标函数最小。因此为了消除这种平凡解,而增加约束条件 \bold Y^T \bold D \bold Y = \bold I ,以及 \sum_i \bold{\vec y_i} = \bold{\vec 0} 。即:
min \space \mathcal{L} (\bold Y) = \frac1{2} \sum_{i,j} W_{i,j} \| \vec{\bold y_i} - \vec{\bold y_j} \|_2 ^2 = min \space tr(\bold Y^T \bold L \bold Y) s.t. \bold Y^T \bold D \bold Y = \bold I, \sum_i \bold{\vec y_i} = \bold{\vec 0}
上述最优化问题的解为归一化的图拉普拉斯矩阵 \bold L_{norm} = \bold D^{-1/2} \bold L D^{-1/2} 的d个最小的特征值对应的特征向量 。
graphwave采用另一种非常不同的方法来捕获结构角色,它依赖于谱图小波 spectral graph wavelet 以及 heat kernel 技术。
简而言之,令 \bold L = \bold D - \bold A 为图拉普拉斯矩阵, \bold D 为图的 degree 矩阵, \bold A 为图的邻接矩阵。令 \bold U 为 \bold L 的特征向量eigenvector组成的矩阵 eigenvector matrix,对应的特征值eigenvalues 为 {\lambda_1, ..., \lambda_{|\nu|}} 。
定义 heat kernel 为 g(\lambda) = e^{-s \lambda} ,s为预定义的 scale 超参数。
对于每个顶点 v_i ,graphwave 使用 \bold U 和 g(\lambda) 计算一个向量 \psi_{v_i} 来代表顶点 v_i 的结构角色: \psi_{v_i} = \bold U \bold G \bold U^\top \bold{ \vec v_i}
其中, \bold G = diag(g(\lambda_1),...,g(\lambda_{|\nu|})) 为 g(\lambda) 所组成的对角矩阵。
\bold{ \vec v_i} 为独热indicator向量,表示 v_i 对应于拉普拉斯矩阵 \bold L 中的那一行
graphwave 表明这些 \psi_{v_i} 隐式地和拓扑统计量相关,如 v_i 的 degree 。选择一个合适的 scale \bold s ,graphwave 能够有效地捕获有关图中顶点角色的结构信息。
参考文献:
Graph Embedding & GNN 综述和其它 http://huaxiaozhuan.com/深度学习/chapters/11_GNN3.html