CI 与 CD 的区别是什么?
9 个回答

本文根据张鹄干老师在〖deeplus直播:猪八戒网DevOps演进及CI/CD最佳实践〗线上分享演讲内容整理而成。(文末有回放的方式,不要错过)


一、前言
本文旨在通过对从0到1构建DevOps和从DevOps到一站式研发平台两个部分的讲解,介绍猪八戒网DevOps的实践与演进。从2016年底发布的第一个版本到如今能够完全支撑猪八戒网500+研发人员的日常研发工作,DevOps团队经历了不断的试错和改进总结。本文侧重于解决方案,更多细节可以关注八戒技术团队公众号获取,希望对即将实践DevOps和正在实践DevOps的团队有所帮助。
二、从0到1构建DevOps
1、背景介绍
2015年,历经10年步步为营,稳定发展的猪八戒网厚积薄发,迎来了业务的快速增长,随之而来的就是公司人员的壮大,研发团队从几十人扩张到了几百人,而正是人才的引入和业务增长的迫切需求,使得猪八戒网开始了一场轰轰烈烈的改革运动,而这样的运动,在过去的十年里已经搞了6次,因为公司的取经文化,我们将这样的运动称之为“腾云行动”。

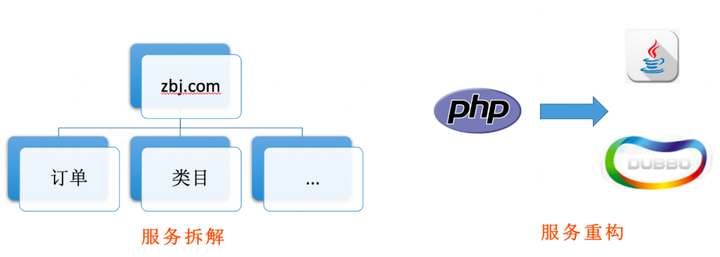
而这次的腾云行动,我们主要做了两件事情:
- 第一件事是服务拆解,把庞大的单体应用根据业务划分,模块功能划分,拆解成一个个独立的小应用进行部署;
- 第二件事是服务重构,将之前由PHP编写的程序用Java重构了80%以上,同时引入以SOA为核心框架的架构体系。

而这两件事情,将交付周期从之前的月,缩短至周,甚至为天。这无疑对我们的交付能力提出了严峻的考验。
于是,经过充分的调研和准备,以及慎重的决定,在2016年第三季度,研发团队抽调了部分运维人员和开发人员组建了devops团队,这个团队的目标只有一个,那就是满足频繁的交付,随时随地地交付。
而要实现这个目标,就必须要做到以下几点:
- 构建标准化的研发流程,使整个交付过程可靠和规范。
- 能一键生成可部署工程,一来是为了避免开发重复造轮子,缩短他们的开发周期,二来是统一技术栈,规范研发,降低维护成本。
- 打造自动化的CI/CD流水线,替代人工部署,大幅度提升交付效率。
- 建立线网故障快速回滚机制,给高速生产可能出现的差错提供应对措施,提升全站可用性。
2、标准化的研发流程
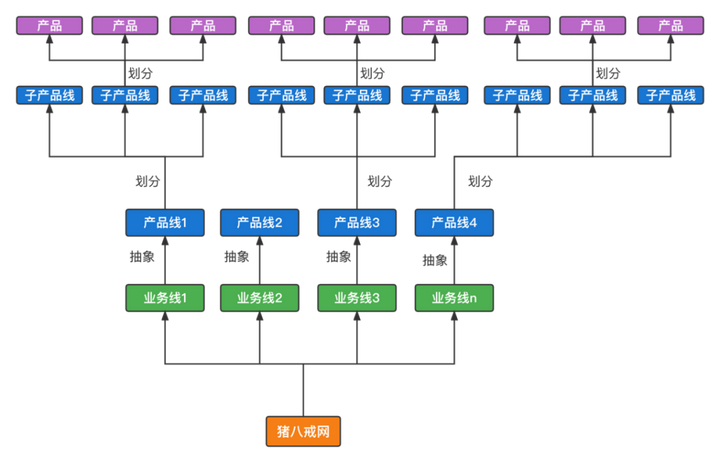
我们将猪八戒网的业务拆成了一条条业务线,现在将这些业务线抽象成一条条产品线,然后产品线下面有子产品线,子产品线下面就是具体的产品,从而形成了一棵层次分明、业务清晰的产品树。

接着我们引入了产品责任制的概念,我们可以看到,每一个产品都包含了一些基本信息,这里需要注意的是,每一个产品都必须有一个产品经理,而产品经理也是有归属部门的,于是我们就得到了一条责任链,产品-产品经理-归属部门。


然后,我们又引入了工程责任制概念,同理,我们每个工程也包含了一些信息,如源码地址、开发语言、运维配置信息,以及我们的工程负责人,每个工程负责人也有归属部门,这样我们也得到了一条责任链,工程-工程负责人-归属部门。


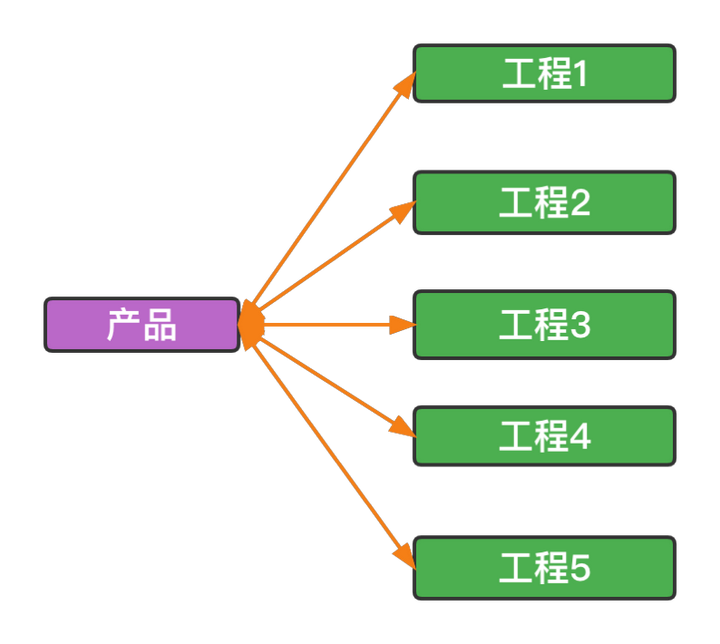
我们现在将产品与工程关联起来,并规定每一个工程必须关联一个产品,这样就保证了每一个产品都能找到实实在在的生产源码。

而做到这些还不够,我们还需要一个东西,把这些全部穿起来,于是我们使用jira构建了四种标准的需求发布流程:
- 新产品上线流程:新产品第一次上线使用该流程,涉及需求评审,产品原型评审,安全评审,技术方案评审等
- 产品大版本迭代上线流程:产品重大变更使用该流程,涉及需求评审,产品原型评审,安全评审,技术方案评审等
- 产品功能迭代上线流程:产品功能模块日常迭代使用该流程
- bug修复流程:修复bug快速上线使用该流程
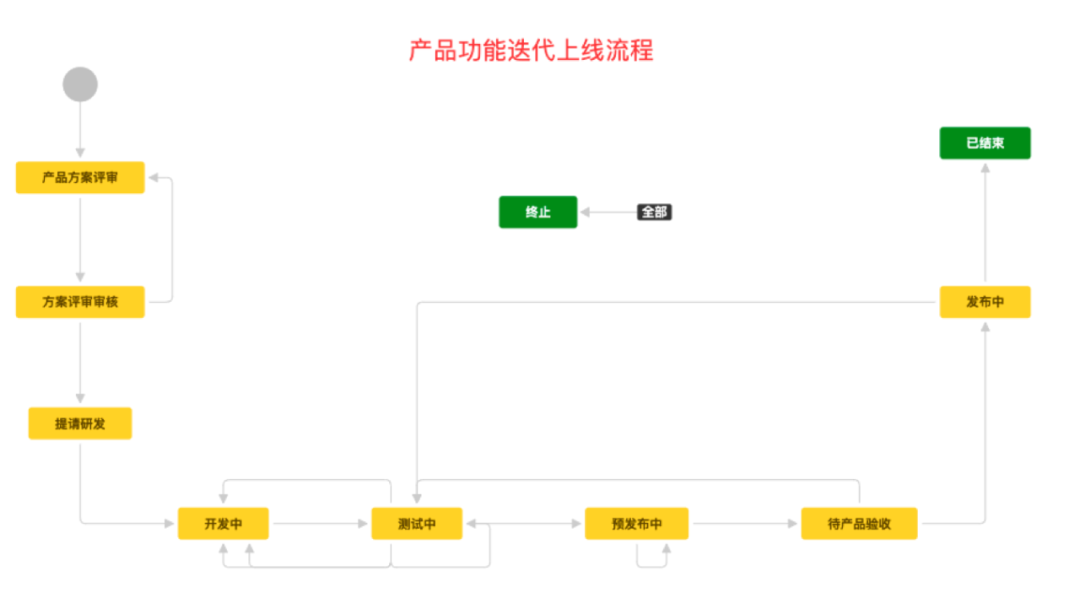

现在有了产品树、产品责任制、工程责任制,以及需求发布流程,我们最后就建立了需求-产品-工程的标准研发生产线。


3、一键生成可部署工程
要做到这点,我们需要实现四个功能:
1)创建源码仓库:根据用户填写git祖名和工程名自动创建git仓库。
2)提供各种技术栈的工程模版:根据用户填写的开发语言提供对应的工程模版,并在创建git仓库后,完成初始化,提交到git仓库。
3)生成部署配置信息:根据用户填写的基本信息和系统预设配置动态生成流水线配置信息。
4)生成配置中心信息:生成各环境配置中心信息。
4、CI/CD流水线


流水线做的其实总结起来就四件事:拉取源码,编译构建,将制品上传制品库,将制品部署到服务器。


而为了使这个过程可靠、可控以及规范,我们加入了校验任务,校验一些准入准出。
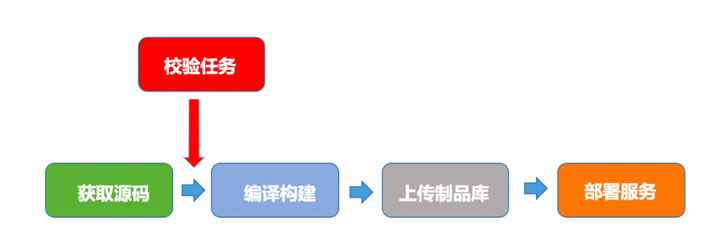

其次,再加入了测试任务,如自动化测试等。
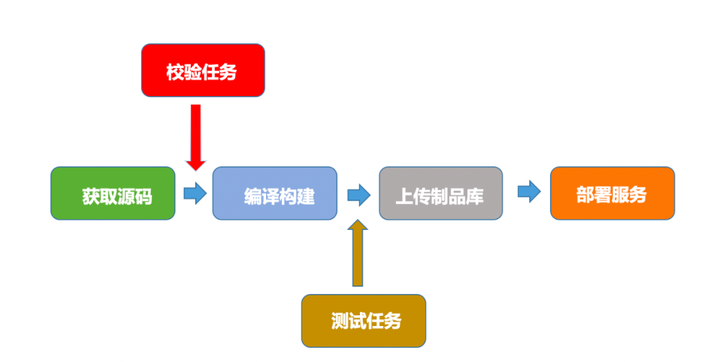

然后就形成了这么一条流水线:


最后应用到各个环境后,便成为了以下的流水线:
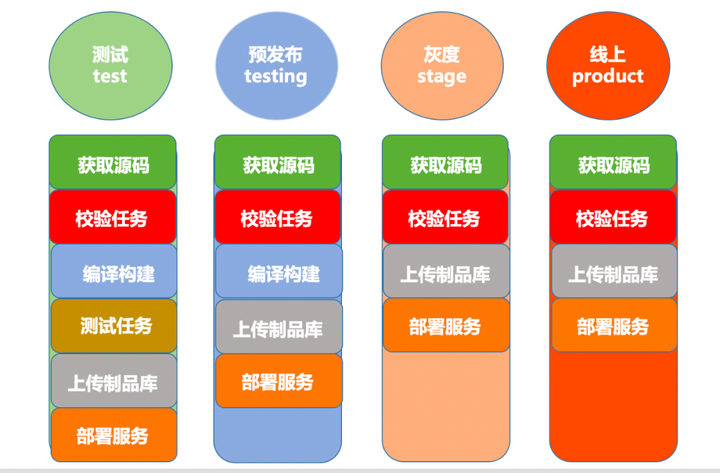

流水线具有如下功能:
1)支持虚拟机容器两种发布方式
虚拟机发布,在完成编译构建之后,把生成的制品上传到文件服务器,这个文件服务器就相当于是虚拟机发布工程的制品库,文件服务器上保存了这个工程发布的历史制品版本,在上传到文件服务器后,接着会从文件服务器将制品同步到代码源,最后,虚拟机服务器上的守护进程会检测代码的代码是否发生变更,如果变更,便主动拉取代码,然后重启服务。
而容器发布,则会在编译构建完成之后,根据用户提供的dockerfile文件构建镜像,然后将镜像上传到公司内部的hub仓库,接着组装元数据,调用容器云接口,部署到k8s集群。这里的容器云是猪八戒网自己基于k8s做的二次封装,主要的功能,就是将元数据拿来处理生成deploy文件,然后调用k8s执行部署操作。
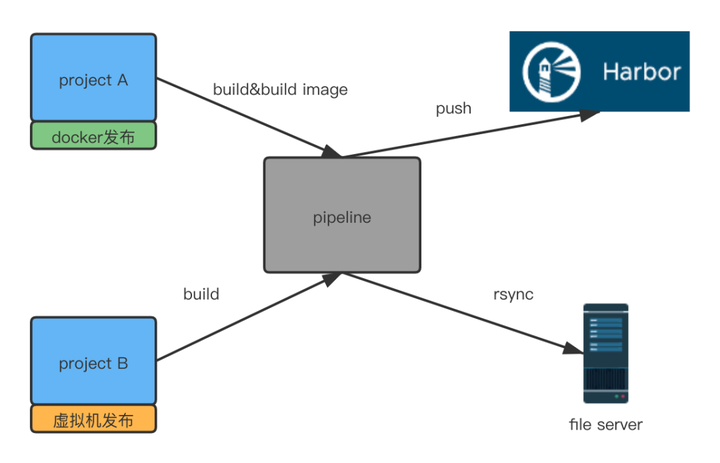

容器发布&虚拟机发布构建打包示意图
2)多分支开发,主干上线
在测试阶段,可以用各种分支进行开发测试,测试通过后,就必须合并到主干,然后用主干进行发布上线。
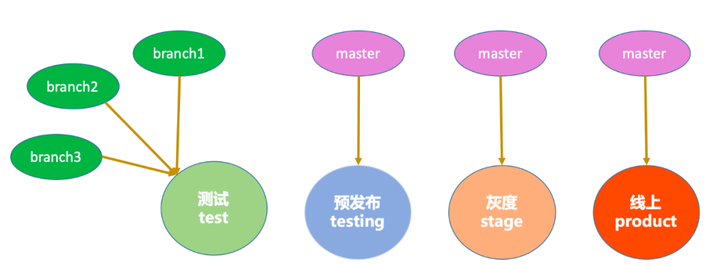

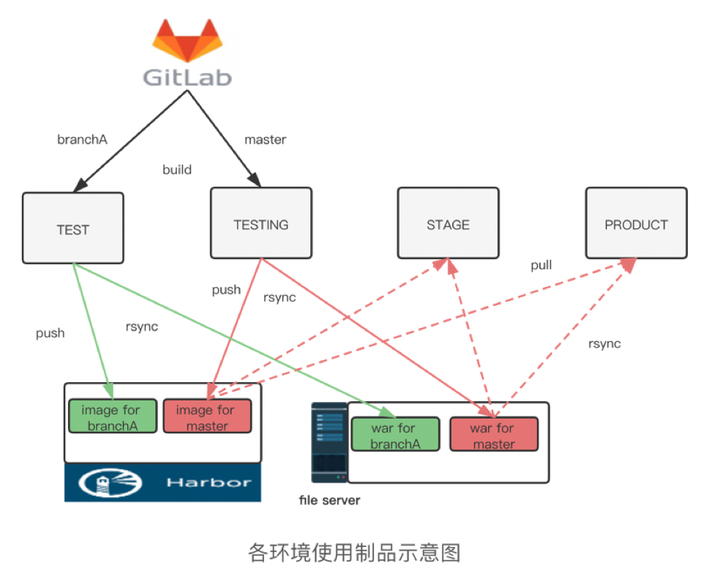
3)一次构建处处使用
考虑到设置的分支策略,于是我们规定,测试环境的制品只能用于测试环境使用,这样一来就需要在预发布再进行一次构建操作,而此次的制品因为是经过测试而合并到主干的代码生成的,所以认为是稳定可靠的,于是在后续的环境中,将不需要再次构建,而直接使用预发布生成的制品。

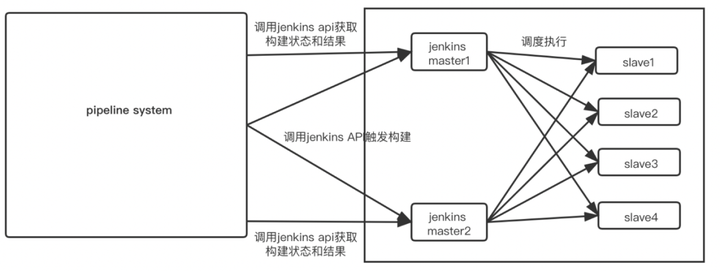
4)使用Jenkins作为后台构建作业机器
采用多master,多slave的Jenkins集群方案,其中master只做调度,slave执行确定任务,我们预先在jenkins master上创建了流水线对应的job,图中的左边是我们自研的流水线服务,用Java编写的,通过调用jenkins API触发构建,jenkins master调度slave节点执行job,然后左边的流水线服务定时调Jenkins API获取构建状态和结果,实时更新推送记录的状态和日志。

现在,我们将需求发布流程和流水线结合起来,就能得到下图所示的标准生产过程。
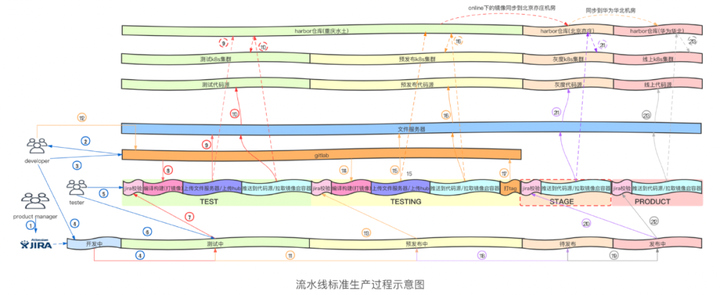

5、线网故障快速回滚机制
上面我们讲了流水线,现在来讲一下,如果上线出现了问题,如何进行回滚。不知道大家有没有注意到上图的一个细节,那就是在预发布的时候,有一个任务——打tag,而这个操作就是我们实现回滚的关键。
这个打tag主要做了两件事情:
- 在git上生成tag,代表此次的代码是稳定的,可以上线的;
- 保存了一条记录,代码版本和制品版本以及本次tag的记录。
现在我们看看这种情况:




比如现在我们发布了一次线上,发布的tag版本是v1.3.35,对应的代码版本是a,镜像是A,这次发布是成功的,没问题的。
然后我们又发布了一个版本到线上,v1.3.36,对应的版本是a,镜像是A,当发布到线上后,发现服务异常,于是需要进行回滚操作,选择上一次成功的版本v1.3.35,因为保存了这个版本对应的代码信息和镜像信息,所以当选择这个版本时就能找到这个正确的制品,然后触发一次流水线,就进行了回滚。整个过程可以控制到几十秒内,让线网故障导致的损失降到最低。
最后,我们看一下整个devops的生态链:


至此,我们的devops第一阶段完成。
1)带来的意义与价值:
- 研发过程标准化,责任制管理研发生产资料,交付过程更可靠;
- 提供多种工程模板,无需从零搭建工程,降低开发成本的同时,统一技术栈,规范代码研发;
- CI/CD自动化,支持高频构建(支持500+研发人员日常构建),降低运维成本(运维同学从40人减少到10人);
- 线网故障快速回滚,提升全站可用率。
2)不足之处:
- 流水线执行过程不够灵活,导致负载过高,耗费更多资源;
- 工程全生命周期管理缺失关键路径,大量工程处于散养状态;
- 基础服务和工具众多,需要多个平台间切换,增加开发人员负担;
- 没有高效自助执行的研发类工作流,大量实际工作需要人工处理;
- 缺乏成本管控手段,服务器成本居高不下。
三、从DevOps到一站式研发平台
我们针对以上不足做了以下改造:
1、重构流水线
1)把流水线的任务拆解成一个个独立的原子任务,并将原子人按功能划分为校验类和执行类。
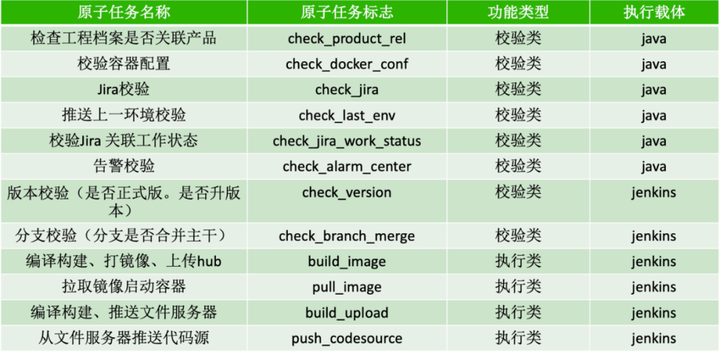

2)根据工程的开发语言,发布方式,以及推送环境,预设了一套流水线任务列表。


可以看到,这里面有两种箭头,分别代码同步任务和异步任务:
- 同步任务串行执行,若失败会阻断流程;
- 异步任务并行执行,若失败,不会阻断流程。
3)自研了Jenkins rabbitMQ插件,实现流水线服务与Jenkins之间通过消息队列通信。
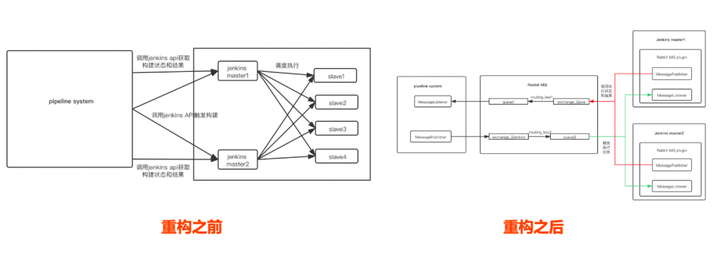

重构之前,前面讲到是通过调用Jenkins API的方式实现的,而重构之后,流水线服务组装好构建信息后将消息发布到队列里,jenkins 插件消费消息,然后调度slave执行任务,同时将状态和结果生成消息也发布到队列中,流水线服务消费消息更新日志和状态,这种方式极大地提升了成功率。
4)Jenkins slave节点容器化
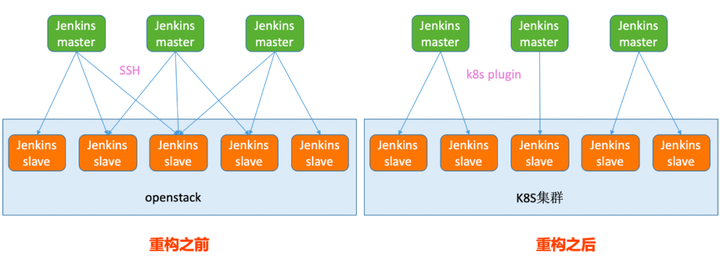

重构之前,所有的slave节点都是虚拟机,这样就导致节点数量固定,要么造成资源浪费,要么无法满足高并发,而且维护成本较高,一旦涉及改动,需要人工更改每一个节点。
重构之后,我们利用k8s 插件,链接我们的k8s集群,创建slave节点。利用k8s特性,可动态调整节点数,既满足高并发,又不造成资源浪费,并且维护简单,一旦涉及改动,只需要重新构建slave镜像应用即可。
重构之后的流水线有如下特点:
- 流水线执行任务更加灵活,可按照实际情况动态调整执行任务,实现“因地制宜”;
- 提升了流水线执行任务的成功率,实现高可用;
- 通过k8s特性实现Jenkins slave节点动态扩缩容,满足高并发的同时,节约服务器资源。
2、工程全生命周期管理
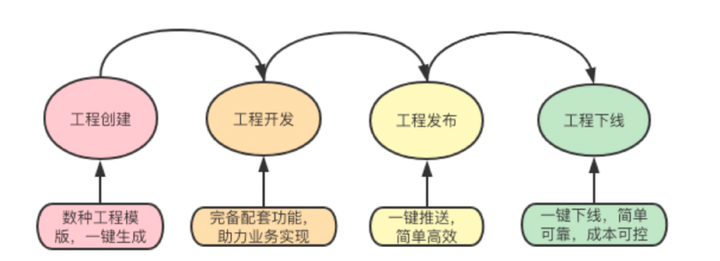
1)工程创建阶段
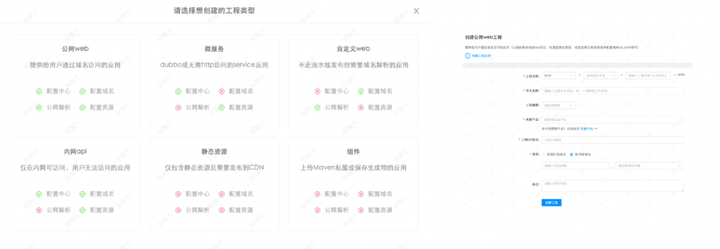

定义六大工程类型,完全覆盖所有研发需求,且配置简单,一键创建。
2)工程研发阶段
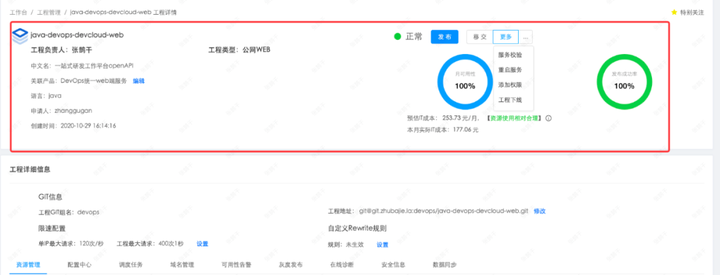

根据工程类型生成配套组件,研发阶段全面赋能。
配套组件有工程权限管理、工程服务管理、工程资源管理、配置中心管理、调度任务管理、域名管理、安全管理等。
3)工程上线阶段
统一需求发布流程,cicd流水线标准生产,保证每一步的可靠性。
4)工程运行阶段
实时监控服务,多种维度的异常告警机制。
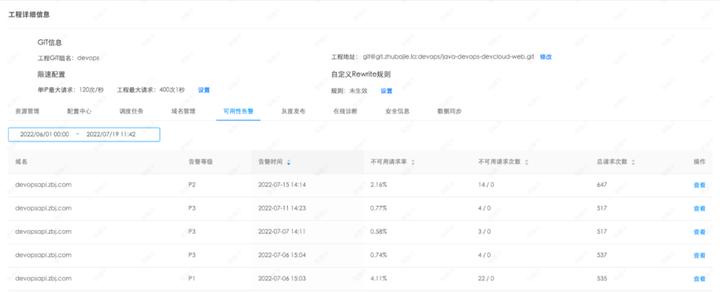

5)工程下线阶段
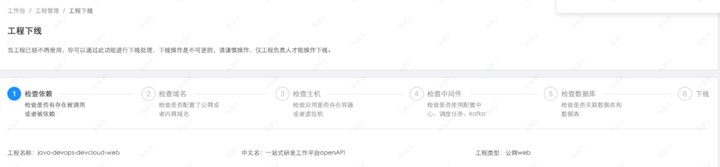

智能检测中心检测无用工程,360度检查工程依赖项,一键下线,操作简单。
由此我们实现了工程的全生命周期管理:

3、整合基础服务和工具
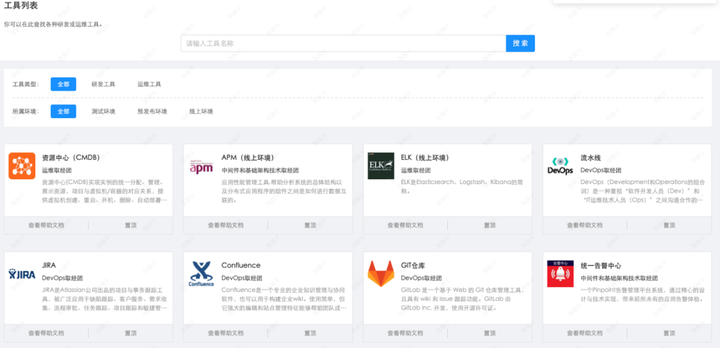

1)提供一站式查询和使用
2)提供各类工具使用文档
4、高效研发工作流
1)三步自定义工作流模版
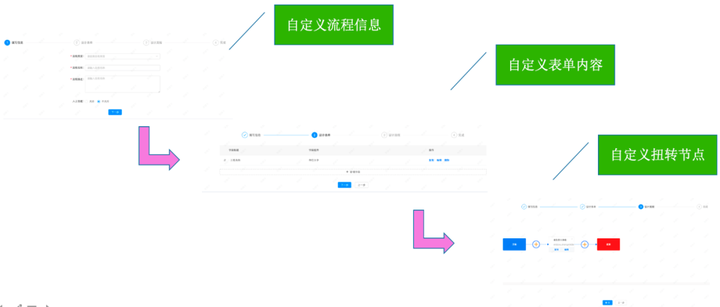

- 首先是自定义流程信息,填写工作流的一些简单信息;
- 然后是自定义表单内容,我们提供了大量丰富的表单组件,如文本框、单选框、复选框等;
- 最后是自定义扭转节点,可以设置每个节点的经办人,如果是系统执行,则会根据工作流类型执行对应的后台任务。
有了工作流模版,我们就可以创建工作流了。
2)三步创建工作流


- 首先是选择工作流模版;
- 然后是填写表单,就是对应工作流设置的表单;
- 最后提交,即可完成工作流的创建。
3)实时记录工作流状态和执行过程
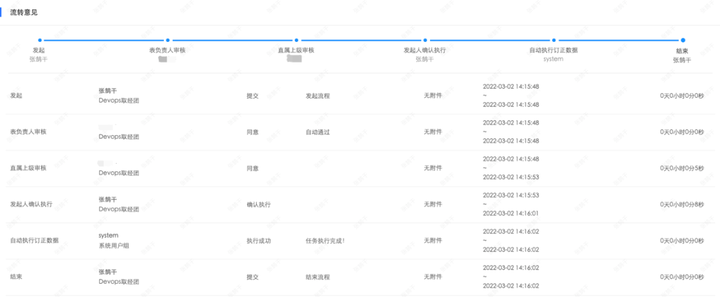

当创建完一条工作流后,这条工作流所有的执行状态以及过程都会被清晰地记录下来,如图从发起到各个节点的扭转,以及执行结果、执行时间。
4)数十种系统自动执行节点任务
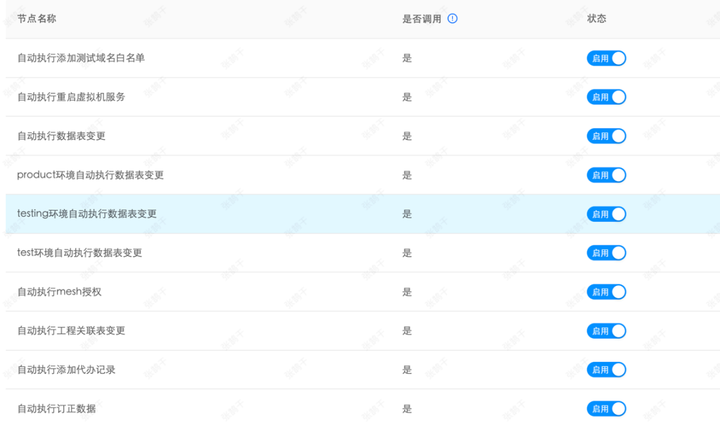

如果经办人是系统,那么就会根据当前工作流类型执行对应的系统任务,我们预置了几十种系统执行任务,基本覆盖了所有的研发需求,如数据库相关操作、运维相关操作。
5)实时通知经办人和进行催办
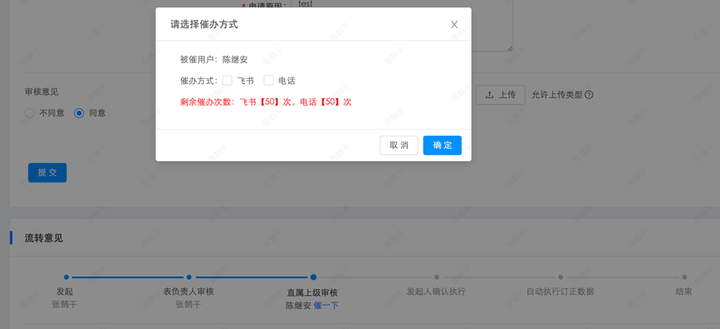


在扭转到某个节点的时候,我们通过系统通知和用户催办,尽可能地缩短工作流的办理时间。
至此我们得到高效扭转的研发工作流。

5、研发成本管理系统
1)产品纬度统计各部门服务器成本费用。
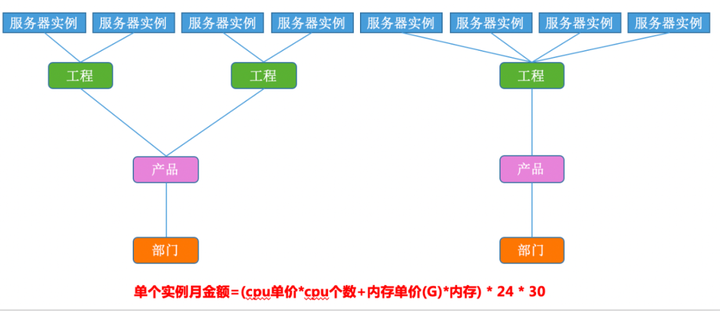

前面我们提到,每一个工程都会关联到一个产品,而每个产品都有归属部门,由此我们便能更具产品纬度统计部门的服务器成本费用,当然,不仅是服务器成本费,也可以是其他费用,如代运维费,开发人员成本等,都可以照此计算。
2)监控每个部门的服务器成本是否超过预算,若超过预算则不允许发布上线。


至此,我们的devops第二阶段完成,总结一下成果和价值:
- 流水线2.0丰富灵活的原子任务支持各种业务场景,在支持高并发、高可用的同时,不造成资源浪费;
- 对工程进行全生命周期管理,保证研发资料100%掌控;
- 一站式管理基础服务和工具,减少开发人员负担;
- 强大高效的工作流系统,极大提升研发效率;
- 成本管理系统,在记录每一个产品的研发费用的同时,严格管控研发成本。
四、结语
DevOps实践之路还在继续,因为不同公司有不同的业务场景,而同一公司的业务也会随着时代的发展不断变化,只有适合自己的才是最好的,只有能拥抱变化的才是最好的,但万变不离其宗的,我觉得应该有以下几点:
1)DevOps应该是以提高研发效率为目标的实践,脱离了这个目标,做得再好也只是炫技。
2)DevOps应该是紧贴业务的,因为业务的不同,要求的技术架构也会有所不同,随之而来,要求的交付方式也会有所不同。
3)DevOps应该是以人为本的,我们应该尽可能地将一切繁琐的过程交给程序去执行,而人只需要“坐享其成”或者做少量的决策即可。
本期直播回看地址:
关于我们
dbaplus社群是围绕Database、BigData、AIOps的企业级专业社群。资深大咖、技术干货,每天精品原创文章推送,每周线上技术分享,每月线下技术沙龙,每季度Gdevops&DAMS行业大会。
关注公众号【dbaplus社群】,获取更多原创技术文章和精选工具下载


