
Hive sampling 语法之TABLESAMPLE用法理解
官网关于LanguageManual Sampling的教程,部分截图如下,这里主要分享对TABLESAMPLE(BUCKET 3 OUT OF 16 ON id)子句的理解
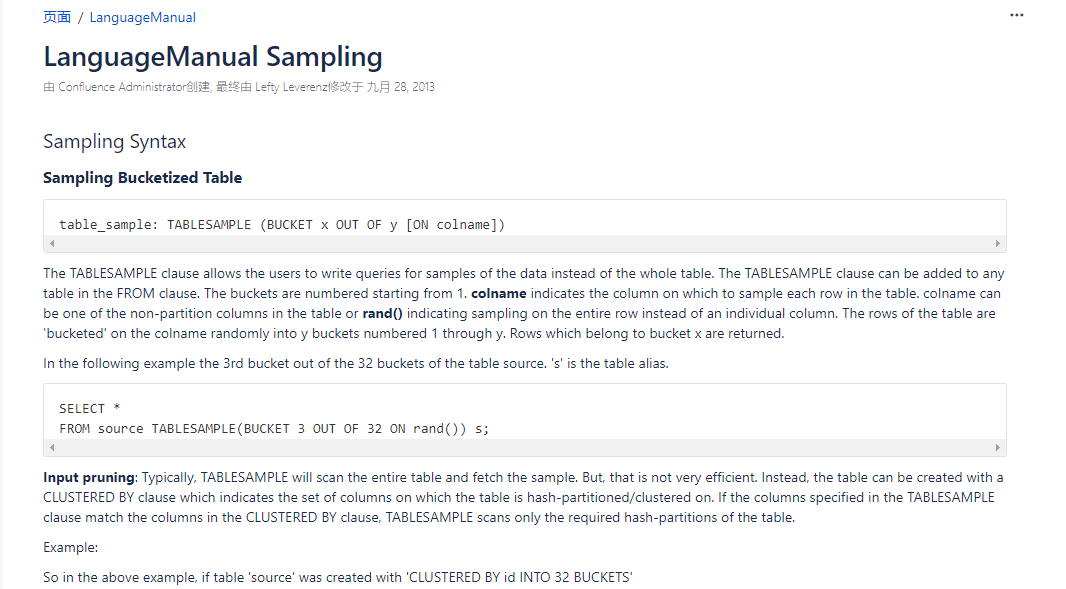
官网中假设创建表时设置了 CLUSTERED BY(id) INTO 32 BUCKETS 即分成了32个文件(虽然这里用的是bucket,为了避免混淆和方便理解下面的解释,个人倾向于用cluster或者叫簇来代替),那么下面这个子句
TABLESAMPLE(BUCKET 3 OUT OF 16 ON id)
在查询中的意思是将cluster分成16个桶,然后取出第三个桶中的数据。32个文件分进16个桶,那就是每个桶有(32/16=)2 个cluster,怎么分呢?第1个cluster分进第1个桶,第2个cluster分进第2个桶......第16个cluster分进第16个桶,第17个cluster分进第1个桶,以此类推。所以当取出第三个桶中的数据时,就会取出第3个簇(cluster)和第19簇(cluster)的数据。官网原话:
would pick out the 3rd and 19th clusters as each bucket would be composed of (32/16)=2 clusters.
那下面这个怎么理解呢?
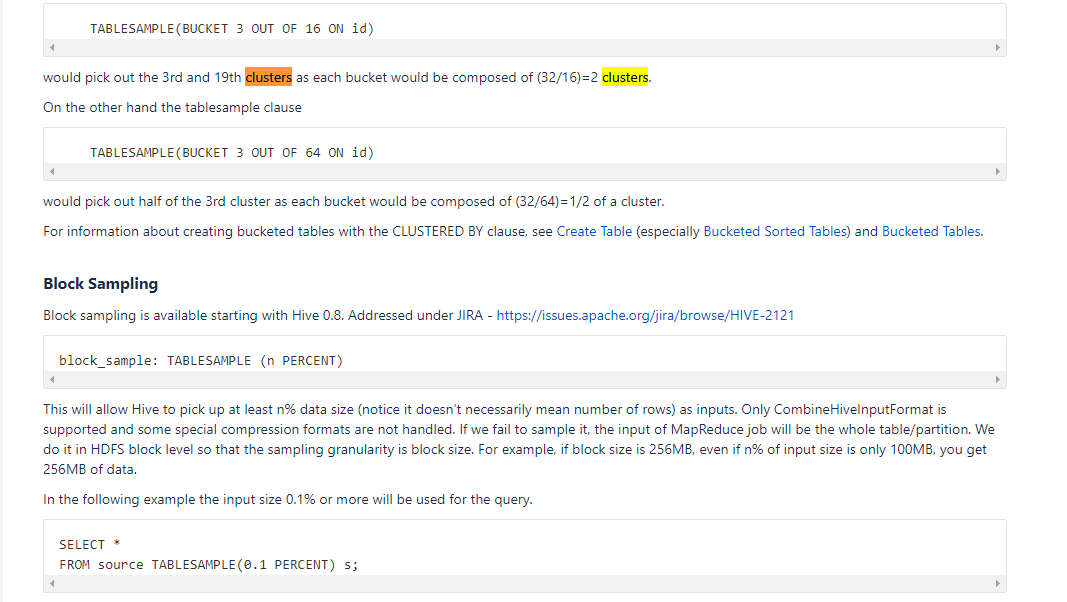
TABLESAMPLE(BUCKET 3 OUT OF 64 ON id)
32个cluster分进64个桶,然后再抽出第三个桶中的数据。32/64=1/2,每个桶由1/2个cluster组成,同样地,第1个cluster的前一半数据分进第1个桶,后一半数据分进第33个桶,第2个cluster的前一半数据分进第2个桶,后一半数据分进第34个桶,.....第32个cluster的前一半数据分进第32个桶,后一半数据分进第64个桶。所以这个子句会取出第3个桶中的数据,也就是第3个cluster中的前一半数据。官网原话:
would pick out half of the 3rd cluster as each bucket would be composed of (32/64)=1/2 of a cluster.
补充官网关于分桶表的DDL操作

