
文本分类之TextCNN与DPCNN

前言
本文为自然语言处理(NLP)中常用模型讲解系列文章之TextCNN与DPCNN,此系列第一篇文章为理解文本分类利器——fastText。
本文将以卷积神经网络(CNN)作为切入点,首先简单地介绍一下CNN的特点,然后介绍CNN在NLP领域的应用即TextCNN模型和DPCNN模型,最后基于Pytorch进行对TextCNN和DPCNN模型的复现实践。
CNN
- CNN的特点
稀疏权重(sparse weights)
参数共享(parameter sharing)
等变性(equivariant)
在神经网络中,全连接层的输入和输出之间的连接关系可以通过一个“参数矩阵”来表示。如图1所示,在这个全连接网络中,输入层和第一个隐层、第一个隐层和第二个隐层、第二个隐层和输出层之间的每一个“输入神经元”和每一个“输出神经元”之间都存在连接关系,形成“稠密”的网络结构。


在卷积神经网络即CNN中,卷积核尺寸远小于输入尺寸。
以图1为例,在全连接网络中,输入层维度为6,第一个隐层维度为4,因此参数矩阵的大小应为 6*4 。而在CNN中,你可以有1个或者几个 1*3 大小的参数矩阵(卷积核),然后以卷积核等长的窗口在输入向量中进行滑动并进行点积操作,返回1个或几个 1*4 大小的特征向量,再对这些特征向量进行 sum 或 avg 等操作,即可获得1个 1*4 大小的特征向量。相比于全连接神经网络中参数矩阵的大小,CNN中参数矩阵的大小“相当稀疏”!
稀疏权重也是具有物理含义的:通常,图像、文本等数据都具有局部特征,通过稀疏权重的方式先学习输入的局部特征,再将局部特征组合起来形成更加复杂抽象的特征。
由上面这个例子可以看出来,相比于全连接神经网络,CNN中参数矩阵“相当稀疏”,且CNN并不为每一个“输入神经元”和每一个“输出神经元”分配一个参数,而是试图学习一个参数集合(卷积核),即进行了参数共享。
那怎么理解CNN的等变性呢。如图2所示,我的理解是由于卷积核具有参数共享的特性+搭配池化操作 \to 平移等变性。(欢迎大佬们指正)


2. Pytorch中的卷积层
Pytorch中提供了三种常见的卷积网络层:Conv1d、Conv2d和Conv3d. 一般情况下,Conv1d用于文本,Conv2d用于图像(RGB,灰度图等),Conv3d用于视频。有关Conv*d卷积网络层的用法可以参考Pytorch常用Layer深度理解。
TextCNN
1. 模型结构
TextCNN被Yoon Kim等人在《Convolutional Neural Networks for Sentence Classification》一文中提出,其模型结构如图3所示。


TextCNN的第一层为嵌入层。
获得单词嵌入向量的方式目前可以分为:预训练和“新训练”。预训练的词嵌入可以利用其它语料库的单词分布得到更多的先验知识,而通过当前网络训练的词嵌入可以更好地捕获与当前任务相关的单词分布特征。
嵌入层的输入是 n \times d_{input} 的矩阵,其中 n 表示句子长度, d_{input} 表示单词初始向量的维度。嵌入层的输出是 n \times d_e 的矩阵, d_e 表示单词嵌入向量的维度。为了方便批处理,通常对长度不等的句子进行padding操作。
图3中的嵌入层采用了双通道(static与non-static)的形式,一个表示预训练的词嵌入,在训练过程中不再发生变化,另一个表示“参与网络训练”的词嵌入,其作为参数在训练过程中发生改变。
TextCNN的第二层为卷积层。
与CV领域不同的是,NLP中的卷积核只在一个方向上进行滑动。
可以试着这么理解这个区别。在图像中,每个像素都是一个特征,而图像具有长和宽。因此,应用于CV中的卷积核,为了捕获长和宽两个维度的局部特征,卷积核通常在长宽两个方向上按步长进行滑动(进行卷积操作)。而在句子中,一个单词是一个特征,也就是说,句子只具有长度一个维度。因此,应用于NLP中的卷积核,宽度与单词的嵌入维度相同,且卷积核只会在句子长度这一个方向上进行滑动(进行卷积操作)。
图3中,共有四个卷积核,两个大小为2的卷积核和两个大小为3的卷积核。
卷积层的输入是 n \times d_e 的句子矩阵,输出是 (n-k+1) \times 1 的向量,其中k k 表示卷积核的大小(长度)。
TextCNN的第三层是池化层。
与卷积层类似,NLP中的池化层也只在一个方向上进行Pooling操作。
图3中,池化层的输入是 (n-k+1) \times 1 的向量,输出是一个 Scalar (标量)。
一个卷积操作+池化操作会获得一个 Scalar ,将具有相同卷积核(但是是不同的卷积核,即参数不同)大小( k )的卷积操作结果再进行池化的 Scalar 拼在一起,即构成这个卷积核大小下的特征向量(feature vector)。
将不同卷积核大小的feature vector拼接在一起(final feature vector),作为输出层的输入。
TextCNN的第四层是输出层。
输出层是全连接层,使用Dropout防止发生过拟合。
输出层的输入是final feature vector,输出是类别的概率分布。
以上内容就是对TextCNN模型结构的详细解读了,接下来使用Pytorch搭建一个简易版的TextCNN来更加直观地理解其网络结构。
2. Pytorch实践
以下代码仅供参考
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.modules.activation import ReLU
class Config(object):
max_seq_len = 16
embed_size = 128
kernel_num = 64
kernel_size = [2,3,4]
output_size = 10
dropout_p = 0.5
class textCNN(nn.Module):
def __init__(self, vocab_size: int, config: Config, embedding_pretrained=None):
super(textCNN, self).__init__()
#Embedding layer
if not embedding_pretrained:
self.embedding = nn.Embedding(vocab_size, config.embed_size)
else:#使用预训练词向量
self.embedding = nn.Embedding.from_pretrained(embedding_pretrained, freeze=False)
self.embedding.weight.requires_grad = True
#Conv layer + pooling layer
#conv_block_*: *表示卷积核的大小
self.conv_block_2 = nn.Sequential(
nn.Conv1d(config.embed_size, config.kernel_num, config.kernel_size[0]),
nn.ReLU(),#激活函数
nn.MaxPool1d(config.max_seq_len - config.kernel_size[0] + 1)#输入n*l,卷积核为k,卷积操作之后,输出为(n-k+1)*1.
)
self.conv_block_3 = nn.Sequential(
nn.Conv1d(config.embed_size, config.kernel_num, config.kernel_size[1]),
nn.ReLU(),#激活函数
nn.MaxPool1d(config.max_seq_len - config.kernel_size[1] + 1)#输入n*l,卷积核为k,卷积操作之后,输出为(n-k+1)*1.
)
self.conv_block_4 = nn.Sequential(
nn.Conv1d(config.embed_size, config.kernel_num, config.kernel_size[2]),
nn.ReLU(),#激活函数
nn.MaxPool1d(config.max_seq_len - config.kernel_size[2] + 1)#输入n*l,卷积核为k,卷积操作之后,输出为(n-k+1)*1.
)
self.dropout = nn.Dropout(p=config.dropout_p)
#Output layer: FC layer
#卷积核大小有2,3,4;分别有64个.
#每个卷积核+池化操作-->一个Scalar;将所有经过卷积+池化操作获得Scalar拼接,形成final feature vector
self.fc = nn.Linear(config.kernel_num * len(config.kernel_size), config.output_size)
# #多类别分类任务
# self.output = nn.Softmax()
def forward(self, x):
#x.shape: (batch_size, max_seq_len)
e = self.embedding(x)#e.shape: (batch_size, max_seq_len, embed_size)
e = e.permute(0, 2, 1)#e.shape: (batch_size, embed_size, max_seq_len)
conv_block_2 = self.conv_block_2(e)#conv_block_2.shape: (batch_size, kernel_num, 1)
conv_block_3 = self.conv_block_3(e)#conv_block_2.shape: (batch_size, kernel_num, 1)
conv_block_4 = self.conv_block_4(e)#conv_block_2.shape: (batch_size, kernel_num, 1)
#torch.squeeze(tensor)#删除tensor中所有为1的维度
#tensor.squeeze(dim=i)#若tensor的第i维度为1,则将其删除
#conv_block_i.squeeze(2).shape: (batch_size, kernel_num)
#feature_vector.shape: (batch_size, kernel_num * 3)
feature_vector = torch.cat((conv_block_2.squeeze(2), conv_block_3.squeeze(2), conv_block_4.squeeze(2)), 1)
feature_vector_after_dropout = self.dropout(feature_vector)
output = self.fc(feature_vector_after_dropout)#output.shape: (batch_size, output_size)
output_prabability = F.softmax(output, dim=1)
return output_prabability, {
"e": e,
"conv_block_2": conv_block_2,
"conv_block_3": conv_block_3,
"conv_block_4": conv_block_4,
"feature_vector": feature_vector,
"output": output
}上述模型几乎是遵循《Convolutional Neural Networks for Sentence Classification》论文的描述构建的,唯一的不同在于:论文中词向量采用了static和non-static两种方式,而上述模型仅采用non-static方式。由于textCNN模型的构建中明确声明了self.embedding.weight.requires_grad = True,所以不管词向量是基于“预训练”模式还是“新训练”模式,其在训练过程中都会发生改变。
基于模型结构,仿造合适大小的数据送至textCNN模型,我们就可以观察模型的详细结构描述和模型每一层的输入输出大小。
#查看模型结构
config = Config()
vocab_size = 100
input = torch.LongTensor([[i+1 for i in range(16)], [(i+1)*2 for i in range(16)]])#batch_size: 2, max_seq_len: 16
textcnn = textCNN(vocab_size=vocab_size, config=config)
print(textcnn)
output_p, tmp = textcnn(input)
print(tmp["e"].size())
print(tmp["conv_block_2"].size())
print(tmp["conv_block_3"].size())
print(tmp["conv_block_4"].size())
print(tmp["feature_vector"].size())
print(tmp["output"].size())
print(output_p)
# textCNN(
# (embedding): Embedding(100, 128)
# (conv_block_2): Sequential(
# (0): Conv1d(128, 64, kernel_size=(2,), stride=(1,))
# (1): ReLU()
# (2): MaxPool1d(kernel_size=15, stride=15, padding=0, dilation=1, ceil_mode=False)
# )
# (conv_block_3): Sequential(
# (0): Conv1d(128, 64, kernel_size=(3,), stride=(1,))
# (1): ReLU()
# (2): MaxPool1d(kernel_size=14, stride=14, padding=0, dilation=1, ceil_mode=False)
# )
# (conv_block_4): Sequential(
# (0): Conv1d(128, 64, kernel_size=(4,), stride=(1,))
# (1): ReLU()
# (2): MaxPool1d(kernel_size=13, stride=13, padding=0, dilation=1, ceil_mode=False)
# )
# (dropout): Dropout(p=0.5, inplace=False)
# (fc): Linear(in_features=192, out_features=10, bias=True)
# )
# torch.Size([2, 128, 16])
# 卷积操作之后输出大小为 (2, 64, max_seq_len - k + 1)# 池化操作之后输出大小为 (2, 64, 1)
# torch.Size([2, 64, 1])
# torch.Size([2, 64, 1])
# torch.Size([2, 64, 1])
# torch.Size([2, 192])
# torch.Size([2, 10])
# tensor([[0.1259, 0.0255, 0.2410, 0.0230, 0.1196, 0.0401, 0.0580, 0.0461, 0.1468,
# 0.1739],
# [0.0644, 0.0564, 0.1970, 0.0447, 0.0918, 0.0630, 0.0518, 0.0409, 0.1474,
# 0.2426]], grad_fn=<SoftmaxBackward>)DPCNN
由于卷积核尺寸通常不会很大,因此TextCNN在捕获长距离特征时效果不理想,其在中短文本场景中具有较好的效果。有文章也指出,TextCNN与传统的n-gram词袋模型具有相似的原理,其之所以可以获得较好的效果很大程度上是因为引入了词向量即Embeeding技术,解决了词袋模型的特征稀疏性问题。
1. 模型结构
为了解决TextCNN在捕获长距离特征时不理想的情况,学术界工业界做了很多尝试,直到2017年腾讯基于TextCNN和ResNet提出了《Deep Pyramid Convolutional Neural Networks for Text Categorization》即DPCNN模型。DPCNN是第一个广泛有效的深层文本分类卷积神经网络,其模型结构如图4所示,模型结构具有以下几大特点。
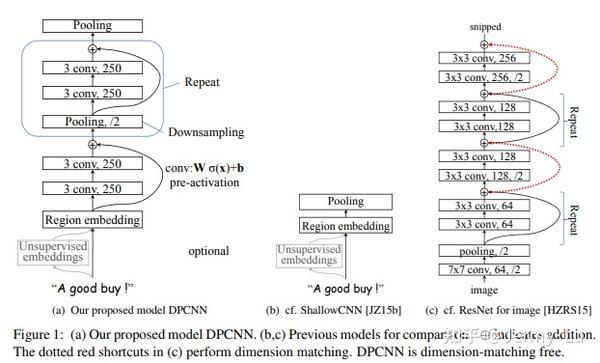

Region embedding:
TextCNN中对于大小为 n \times d_e 的输入矩阵进行卷积操作时,设置卷积核的长度为 k ,则卷积核的大小为 k \times d_e ,然后在输入矩阵上滑动卷积核进行卷积操作。
DPCNN认为TextCNN中的卷积操作更容易导致过拟合,其在大小为 n \times d_e 的输入矩阵上的卷积操作如下所述。假设要以长度为3的卷积核进行卷积操作,则其首先在输入矩阵上以长度为3进行滑动,对每个窗口中的3个词的嵌入向量执行 avg 得到一个 1 \times d_e 的向量(有点类似先在窗口中执行 avg 池化操作),然后再设置大小也为 1 \times d_e 的卷积核进行卷积操作。
等长卷积:
假设输入序列长度为 n ,卷积核大小为 k ,步长为 s ,输入序列两端补0数量为 p ,那么经过卷积操作之后的序列长度为 \frac{n-m+2p}{s} + 1 .
窄卷积: 步长 s =1, p =0,卷积后序列长度为 n-k+1 。
宽卷积: 步长 s =1, p = k-1 ,卷积后输出长度为 n+k-1 。
等长卷积: 步长 s =1, p = \frac{k-1}{2} ,卷积后输出长度为 n 。
等长卷积的物理意义:由于输入输出序列长度均为 n ,所以此时长度为 k 的卷积核执行的卷积操作可以理解为将输入序列的每个位置(例如第 i 个位置)的词及其左右 \frac{k-1}{2} 个词的上下文信息压缩到输出序列的第 i 个位置。
\frac{1}{2} 池化层
DPCNN中提出的池化层大小为3,步长为2,经过池化层之后,输入的长度减半。
讨论:如果只是为了实现将输入的长度减半,将池化层的大小设置为2,步长为2看起来不是更加直观吗?我的理解是:由于 \frac{1}{2} 池化层后又跟了卷积层,池化层大小大一些的话,之后卷积层可以捕获更加长的信息,即一定程度上可以捕获长距离特征。
由于 \frac{1}{2} 池化层的存在,文本序列的长度会随着残差block数量的增加呈指数级减少,即有 nums_{block} = log_2 len_{seq} ,这导致文本序列长度随着网络加深呈现金字塔(Pyramid)形状,如图5所示,这也是论文中Pyramid的由来。


残差连接
为了减缓梯度弥散问题,DPCNN也借鉴了ResNet中的skip-connection或residual-connection。
2. Pytorch实践
在构建DPCNN模型之前,我们首先需要明确DPCNN模型中每一个layer或每一个block的输入输出的大小,明确每个layer或block的输入输出大小可以帮助我们理解DPCNN进行的操作,并方便构建模型结构。
如图4所示+Deep Pyramid Convolutional Neural Networks for Text Categorization论文介绍,DPCNN模型输入大小为[batch_size, max_seq_len];经过嵌入层之后,输出大小为[batch_size, max_seq_len, embed_size];region_embedding卷积层的输入大小为[batch_size, embed_size, max_seq_len],输出大小为[batch_size, 250, max_seq_len-3+1];接下来是等长卷积层,其输入输出大小不变,均为[batch_size, 250, max_seq_len-3+1];接下是最重要的 \frac{1}{2} 池化层+等长卷积层,其构成了一个残差块,它的输出大小是[batch_size, 250, 1];模型最后是一个输出层即全连接层,它的输出大小是[batch_size, output_size]。
以下代码仅供参考
import torch
import torch.nn as nn
import torch.nn.functional as F
class Config(object):
max_seq_len = 16
embed_size = 128
kernel_num = 250
output_size = 10
dropout_p = 0.5
class ResnetBlock(nn.Module):
def __init__(self, config: Config):
super(ResnetBlock, self).__init__()
#https://pytorch.org/docs/stable/generated/torch.nn.MaxPool1d.html#torch.nn.MaxPool1d
self.half_max_pooling = nn.Sequential(
nn.ConstantPad1d(padding=(0, 1), value=0),#用0填充
nn.MaxPool1d(kernel_size=3, stride=2)#1/2池化
)
#两个等长卷积层:步长=1,卷积核大小=k,两端补0数量p为(k-1)/2时,卷积后序列长度不变
#卷积核大小k=3,因此p=1
self.equal_width_conv = nn.Sequential(
nn.BatchNorm1d(num_features=config.kernel_num),
nn.ReLU(),
#padding-->卷积
nn.Conv1d(config.kernel_num, config.kernel_num, kernel_size=3, stride=1, padding=1),
nn.BatchNorm1d(num_features=config.kernel_num),
nn.ReLU(),
nn.Conv1d(config.kernel_num, config.kernel_num, kernel_size=3, stride=1, padding=1)
)
def forward(self, x):
half_pooling_x = self.half_max_pooling(x)
conv_x = self.equal_width_conv(half_pooling_x)
final_x = half_pooling_x + conv_x
return final_x
class DPCNN(nn.Module):
def __init__(self, vocab_size: int, config: Config, embedding_pretrained=None):
super(DPCNN, self).__init__()
#定义各种网络层
#Embedding
if not embedding_pretrained:
self.embedding = nn.Embedding(vocab_size, config.embed_size)
else:
self.embedding = nn.Embedding.from_pretrained(embeddings=embedding_pretrained, freeze=False)
self.embedding.weight.requires_grad = True
#region embedding
self.region_embedding = nn.Sequential(
nn.Conv1d(config.embed_size, config.kernel_num, kernel_size=3, stride=1),
#BatchNormalization
nn.ReLU(),
nn.Dropout(p=config.dropout_p)
)
#两个等长卷积层:步长=1,卷积核大小=k,两端补0数量p为(k-1)/2时,卷积后序列长度不变
#卷积核大小k=3,因此p=1
self.equal_width_conv = nn.Sequential(
nn.BatchNorm1d(num_features=config.kernel_num),
nn.ReLU(),
#padding-->卷积
nn.Conv1d(config.kernel_num, config.kernel_num, kernel_size=3, stride=1, padding=1),
nn.BatchNorm1d(num_features=config.kernel_num),
nn.ReLU(),
nn.Conv1d(config.kernel_num, config.kernel_num, kernel_size=3, stride=1, padding=1)
)
#ResNet_Block
self.resnet_block = ResnetBlock(config)
self.fc = nn.Linear(config.kernel_num, config.output_size)
def forward(self, x):
#x.shape: (batch_size, max_seq_len)
x = self.embedding(x)#x.shape: (batch_size, max_seq_len, embed_size)
x = x.permute(0, 2, 1)#x.shape: (batch_size, embed_size, max_seq_len)
x = self.region_embedding(x)#x.shape: (batch_size, 250, max_seq_len-3+1)
x = self.equal_width_conv(x)#x.shape: (batch_size, 250, max_seq_len-3+1)
while x.size()[2] > 2:#当序列长度大于2时,一直迭代
x = self.resnet_block(x)
#x.shape: (batch_size, 250, 1)
x = x.squeeze()#x.shape: (batch_size, 250)
output = self.fc(x)#output.shape: (batch_size, 10)
output_p = F.softmax(output, dim=1)
return output_p上述模型几乎是遵循《Deep Pyramid Convolutional Neural Networks for Text Categorization》中的描述构建的,唯一一点不同在于:论文中将equal_width_conv的结果送入ResnetBlock时,将其与region_embedding的结果进行了"+”操作,为了简单起见,上述模型直接将equal_width_conv的结果送入ResnetBlock。
基于模型结构,仿造合适大小的数据送至DPCNN模型,我们就可以观察模型的详细结构描述和模型的输出。
vocab_size = 100
config = Config()
input = torch.LongTensor([
[i*1 for i in range(16)],
[i*2 for i in range(16)],
[i*3 for i in range(16)],
[i*4 for i in range(16)]
])#input.shape: (4, 16)#4: batch_size, 16:max_seq_len
dpcnn = DPCNN(vocab_size=vocab_size, config=config)
print(dpcnn)
output_p = dpcnn(input)
print(output_p)
print(torch.sum(output_p, dim=1))
# DPCNN(
# (embedding): Embedding(100, 128)
# (region_embedding): Sequential(
# (0): Conv1d(128, 250, kernel_size=(3,), stride=(1,))
# (1): ReLU()
# (2): Dropout(p=0.5, inplace=False)
# )
# (equal_width_conv): Sequential(
# (0): BatchNorm1d(250, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (1): ReLU()
# (2): Conv1d(250, 250, kernel_size=(3,), stride=(1,), padding=(1,))
# (3): BatchNorm1d(250, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (4): ReLU()
# (5): Conv1d(250, 250, kernel_size=(3,), stride=(1,), padding=(1,))
# )
# (resnet_block): ResnetBlock(
# (half_max_pooling): Sequential(
# (0): ConstantPad1d(padding=(0, 1), value=0)
# (1): MaxPool1d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
# )
# (equal_width_conv): Sequential(
# (0): BatchNorm1d(250, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (1): ReLU()
# (2): Conv1d(250, 250, kernel_size=(3,), stride=(1,), padding=(1,))
# (3): BatchNorm1d(250, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (4): ReLU()
# (5): Conv1d(250, 250, kernel_size=(3,), stride=(1,), padding=(1,))
# )
# )
# (fc): Linear(in_features=250, out_features=10, bias=True)
# )
# tensor([[0.2400, 0.0244, 0.0463, 0.0506, 0.0735, 0.0229, 0.3828, 0.0772, 0.0644,
# 0.0179],
# [0.1415, 0.0241, 0.0688, 0.0542, 0.0445, 0.0348, 0.2988, 0.2474, 0.0507,
# 0.0352],
# [0.1419, 0.0260, 0.0408, 0.0249, 0.0345, 0.0118, 0.4426, 0.2127, 0.0397,
# 0.0250],
# [0.1741, 0.0342, 0.0624, 0.0830, 0.0500, 0.0599, 0.1688, 0.2705, 0.0685,
# 0.0286]], grad_fn=<SoftmaxBackward>)
# tensor([1.0000, 1.0000, 1.0000, 1.0000], grad_fn=<SumBackward1>)以上就是本篇文章的全部内容了,感谢阅读!