
功能强大的python包(六):Requests(网络爬虫)

1.Requests简介

Requests是基于urllib,使用Apache2 Licensed许可证开发的HTTP库。其在python内置模块的基础上进行了高度封装,使得Requests能够轻松完成浏览器相关的任何操作。
Requests能够模拟浏览器的请求,比起上一代的urllib库,Requests实现爬虫更加便捷迅速。
2.网络爬虫
爬虫基本流程:


发起请求: 通过HTTP库向目标站点发起请求,等待目标站点服务器响应。
获取响应: 若服务器正常响应,会返回一个Response,该Response即为获取得页面内容,Response可以是HTML、JSON字符串、二进制数据等数据类型。
解析内容: 利用正则表达式、网页解析库对HTML进行解析;将json数据转为JSON对象进行解析;保存我们需要得二进制数据(图片、视频)。
保存数据: 可将爬取并解析后的内容保存为文本,或存至数据库等。
3.Requests总览
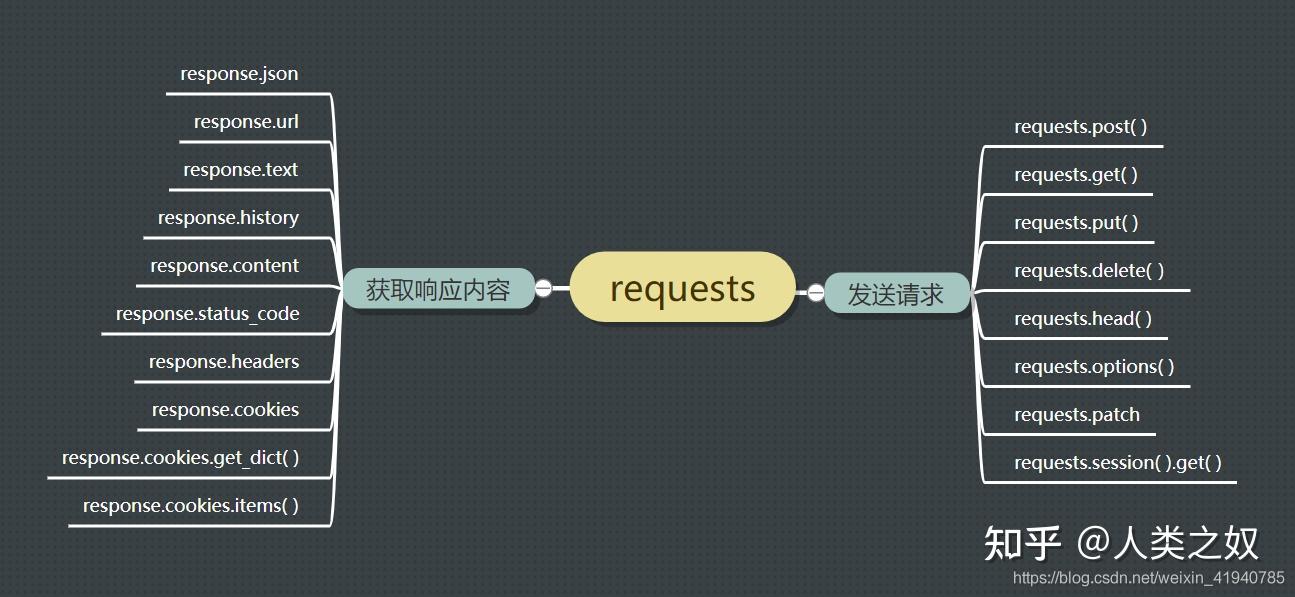
requests
| requests请求 | 功能 |
|---|---|
| requests.get( ) | 从服务器获取数据 |
| requests.post( ) | 向服务器提交数据 |
| requests.put( ) | 从客户端向服务器传送的数据取代指定的文档的内容 |
| requests.delete( ) | 请求服务器删除指定页面 |
| requests.head( ) | 请求页面头部信息 |
| requests.options( ) | 获取服务器支持的HTTP请求方法 |
| requests.patch( ) | 向HTML提交局部修改请求,对应于HTTP的PATCH |
| requests.connect( ) | 把请求连接转换到透明的TCP/IP通道 |
| requests.trace( ) | 回环测试请求,查看请求是否被修改 |
| requests.session( ).get( ) | 构造会话对象 |
| requesets请求参数 | 含义 |
|---|---|
| url | 请求的网址 |
| allow_redirects | 设置是否重新定向 |
| auth | 设置HTTP身份验证 |
| cert | 指定证书文件或密钥的字符串 |
| cookies | 要发送至指定网址的Cookie字典 |
| headers | 要发送到指定网址的HTTP标头字典 |
| proxies | URL代理的协议字典 |
| stream | 指定响应后是否进行流式传输 |
| timeout | 设置等待客户端连接的时间 |
| verify | 用于验证服务器TLS证书布尔值或字符串指示 |
"""get请求"""
import requests
url = 'https://tse4-mm.cn.bing.net/th/id/OIP-C.w3cHPxIHKpLZodnlBoIZXgHaMx?w=182&h=314&c=7&o=5&dpr=1.45&pid=1.7'
response = requests.get(url)
print(res.status_code)
"""添加请求头:header"""
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'}
response = requests.get('https://www.zhihu.com/explore',headers=headers)
print(response.status_code)
"""带请求参数"""
params = {'wd':'python'}
response = requests.get('https://www.baidu.com/',params=params)
print(response.status_code)
"""代理设置"""
proxies = {'http':'http://127.0.0.1:9743',
'https':'https://127.0.0.1:9742',}
response = requests.get('https://www.taobao.com',proxies=proxies)
print(rsponse.status_code)
"""SSL证书验证"""
response = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)
"""超时设置"""
from requests.exceptions import ReadTimeout
try:
response = requests.get("http://httpbin.org/get", timeout = 0.5)
print(response.status_code)
except ReadTimeout:
print('timeout')
"""认证设置"""
from requests.auth import HTTPBasicAuth
response = requests.get("http://120.27.34.24:9001/",auth=HTTPBasicAuth("user","123"))
print(response.status_code)
"""post请求"""
import requests
import json
host = 'http://httpbin.org/'
endpoint = 'post'
url = ''.join([host,endpoint])
"""带数据的post"""
data = {'key1':'value1','key2':'value2'}
response = requests.post(url,data=data)
print(response.status_code)
print(response.text)
"""带headers的post"""
headers = {'User-Agent':'test request headers'}
response = requests.post(url,headers=headers)
print(response.status_code)
print(response.text)
"""带json的post"""
data = {
'sites':[
{'name':'test','url':'www.test.com'},
{'name':'google','url':'www.google.com'},
{'name':'weibo','url':'www.weibo.com'}
]
}
response = requests.post(url,json=data)
print(response.status_code)
print(response.text)
"""带参数的post"""
params = {'key1':'params1','key2':'params'}
response = requests.post(url,params=params)
print(response.status_code)
print(response.text)
"""文件上传"""
files = {'file':open('fisrtgetfile.txt','rb')}
response = requests.post(url,files=files)
print(response.status_code)
print(response.text)
"""put请求"""
import requests
import json
url = 'http://127.0.0.1:8080'
header = {'Content-Type':'application/json'}
param = {'myObjectField':'hello'}
payload = json.dumps(param)
response = requests.put(url,data=payload,headers=headers)
"""head请求"""
import requests
response = requests.head('https://pixabay.com/zh/')
print(response.status_code)
"""delete请求"""
import requests
url = 'https://api.github.com/user/emails'
email = '2475757652@qq.com'
response = requests.delete(url,json=email,auth=('username','password'))
print(response.status_code)
"""options请求"""
import requests
import json
url = 'https://www.baidu.com/s'
response = requests.options(url)
print(response.status_code)
response
| response属性 | 功能 |
|---|---|
| response.text | 获取文本内容 |
| response.content | 获取二进制数据 |
| response.status_code | 获取状态码 |
| response.headers | 获取响应头 |
| response.cookies | 获取cookies信息 |
| response.cookies.get_dict | 以字典形式获取cookies信息 |
| response.cookies.items | 以列表形式获取cookies信息 |
| response.url | 获取请求的URL |
| response.historty | 获取跳转前的URL |
| response.json | 获取json数据 |
import requests
url = 'https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB/5162711'
response = requests.get(url)
print(response.status_code)
print(response.text)
print(response.json)
print(response.content)
print(response.headers)
print(response.cookies)
print(response.cookies.items)
print(response.url)
print(response.history)
print(response.cookies.get_dict)
"""爬虫下载图片"""
import requests
import matplotlib.pyplot as plt
url = 'https://cn.bing.com/images/search?view=detailV2&ccid=qr8JYj0b&id=6CEE679B0BCE19C94FB9C7595986720942C92261&thid=OIP.qr8JYj0bcms3xayruiZmnAHaJQ&mediaurl=https%3a%2f%2ftse1-mm.cn.bing.net%2fth%2fid%2fR-C.aabf09623d1b726b37c5acabba26669c%3frik%3dYSLJQglyhllZxw%26riu%3dhttp%253a%252f%252fp1.ifengimg.com%252f2019_02%252f95A41E54C3C8EB3B3B148A30CE716314B0AED504_w1024_h1280.jpg%26ehk%3d2EhKcVkSnCvT6uBfgisn%252fdwtghMXFWjGa5WgqEbBSPc%253d%26risl%3d%26pid%3dImgRaw&exph=1280&expw=1024&q=%e7%9f%b3%e5%8e%9f%e9%87%8c%e7%be%8e&simid=607996751665040666&FORM=IRPRST&ck=399D74E04F8507D6711ADC8F53A714D7&selectedIndex=0&ajaxhist=0&ajaxserp=0'
response = requests.get(url)
img = response.content
with open('shiyuanlimei.jpg','wb') as f:
f.write(img)
| HTTP状态码分类 | 分类含义 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,请求被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发送错误 |
从以上内容可知,Requests库在向目标网址发送各种请求方面是非常简单易操作的;但Requests库只是完成了网络爬虫中发起请求、获取响应这两个步骤;之后的内容解析、数据保存需要用到另一个库:BeautifulSoup。
学习资料
书本、课程是导师,而博客是助教;我们应该一直跟着导师来学,助教只是在我们遇到困难时帮我们解惑。
我一直觉着通过看大量的博客来学习一门知识、一项技能,还不如跟着一本优秀的书、一门优秀的课程从头到尾学习,这样的学习方法能够让你更系统地掌握该知识、技能。
而不是看了大量博客后,到头来仍然一知半解。
非常推荐大家跟着【尚硅谷】出品的爬虫课程学习,优秀的课程往往为我们筛除了大量的冗余无用的信息,让我们少走很多的弯路。
该课程从爬虫的最基本原理出发,只要你有一点python编程基础,都能够很容易上手;大部分的课程往往只教到很浅层的程度,往往学完后根本没能力从事该方向的工作。【尚硅谷】爬虫课程属于爬虫方向的一站式教学课程,是学完后让你能够真正从事该工作的一门课程。
当然,如果大家只是为了能够自己运用爬虫爬取些数据,可以只看该课程的基础部分,里面有大量的爬虫实战示例,算是手把手教学了。
