python 学习笔记:DASK基础操作
学习笔记:DASK基础操作
1.导包
import dask.dataframe as dd
# main
import numpy as np
# 辅助
2.读取csv文件
ddf = dd.read_csv(dec_CSV_DIR, blocksize=25e6, names=['num', 'crc32num'], dtype=
{'num': numpy.unsignedinteger,
'crc32num': numpy.int64})
blocksize:每次读取的大小
names:列表名字
dtype:读入类型(尽量少用object,占用内存大,查找效率低)
经测试,在对500个数据在10w个数据中查找的情境下,一串数字以object类型和int64类型读取时消耗的内存相同,但是进行匹配时int64更快(差距10s左右)
3.进行运算
使用**.compute()**方法,由于DASK是惰性的,即你的代码不会立即执行,直到使用.compute(),此时会自动评估你的计算,并选择最佳计算方式,以此实现大量数据的快速操作
4.查找数据
举例: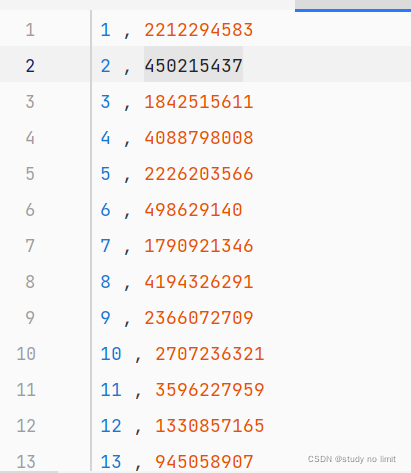
假设我们要在上述数据中查找到第二列的值为450215437所对应的第一列的值
由于我在读取的时候就已经设置列名了,所以下面的代码直接使用列名
第一次尝试
(ddf['crc32num'] == num).compute()
这个会对数据中crc32num的每一个数据与num进行匹配(这里num就是450215437)
返回结果是:

通过type()发现返回结果是<class 'pandas.core.series.Series'>
第二次尝试
如果我只想要获得匹配的数据,不要其他数据要怎么办?
这样:
ddf[ddf['crc32num'] == num].compute()
返回数据为:
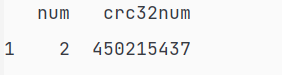
通过type()发现返回的数据为<class 'pandas.core.frame.DataFrame'>
得到DataFrame结构的数据就说明已经差不多了,但是如果我想更进一步,得到图中的num值怎么办?
注:len()可对DataFrame使用,返回的是行数(上图返回1)
第三次尝试
_list = ddf[ddf['crc32num'] == num].compute()
_list['num'].values
会返回数组形式的匹配结果(下图中的temp就是上面的_list)
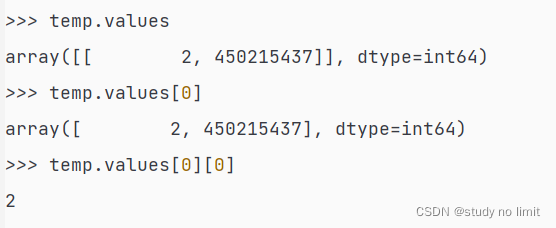
也可以通过直接指定列表名的方式来获得数据

本文来自博客园,作者:Hello418,转载请注明原文链接:https://www.cnblogs.com/janitor/p/16390828.html
