







Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
scrapy的整体框架如下所示:
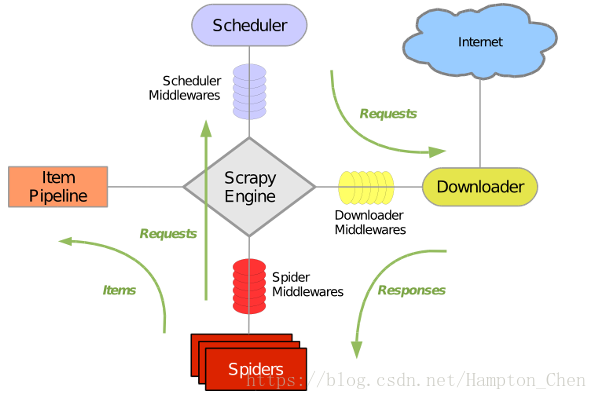
Scrapy主要包含了以下几个组件:
- 引擎(Scrapy):用来处理整个系统的数据流,触发事务(框架核心)。
- 调度器(Scheduler):用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader):用于下载网页内容,并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders):爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares):位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares):介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middewares):介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
安装Scrapy命令:
pip install scrapy第一个爬虫
1、进入到打算存储代码的目录中,运行下列命令,创建一个新的Scrapy项目。
scrapy startproject scrapydemo命令会生成如下目录文件:
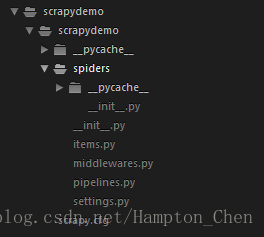
这些文件分别是:
- scrapy.cfg: 项目的配置文件
- scrapydemo/ :该项目的python模块,之后将在这里加入代码
- items.py:项目中的items文件
- middlewares.py:项目中的middlewares文件
- pipelines.py:项目中的pipelines文件
- setting.py:项目的设置文件
- spiders/:放置spider代码的目录
接下来我们要爬取我另一篇博客的内容
https://blog.csdn.net/hampton_chen/article/details/52229327
通过以下命令进入该项目所在的目录,并在spiders目录下生成一个spider文件csdn.py:
cd scrapydemo
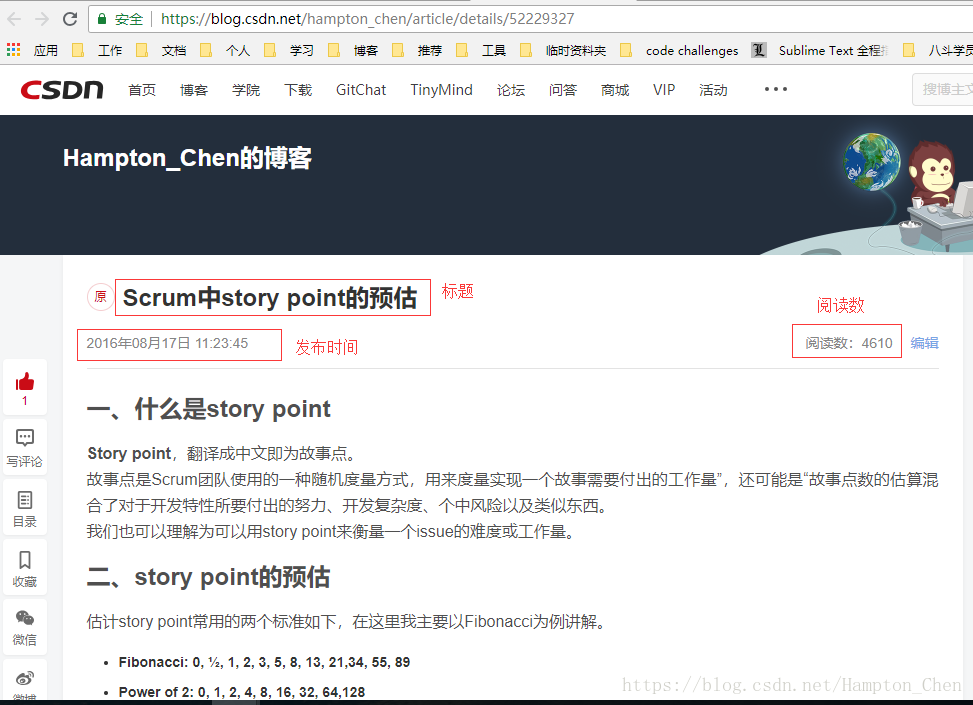
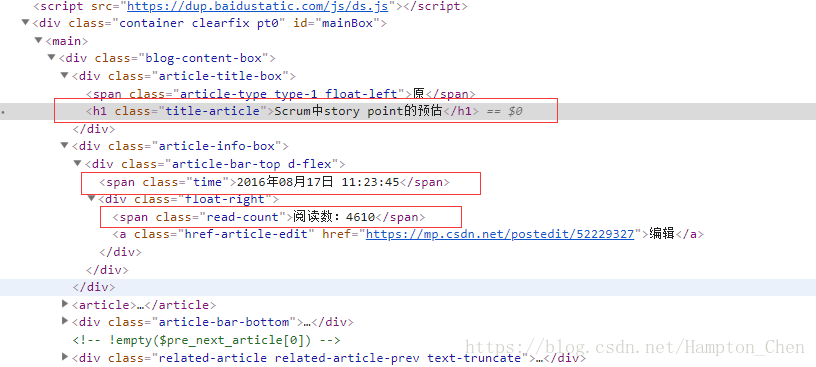
scrapy genspider csdn https://blog.csdn.net/hampton_chen/article/details/52229327打开该博客文章如下,我们这次主要抓取文件的标题、发布时间和阅读数
2、编写items.py文件:
在items.py文件中定义我们要抓取的数据:
import scrapy
class ScrapydemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
time = scrapy.Field()
read_count = scrapy.Field()3、实现Pipelines
Pipeline用来对spider返回的item列表进行数据的保存等操作,可以写入文件或保存到数据库,这里我只是将数据打印出来。
代码如下:
class ScrapydemoPipeline(object):
def process_item(self, item, spider):
print('======================')
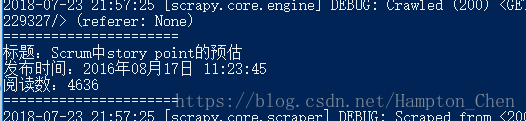
text = "标题:" + item['title'] +"\n发布时间:" + item['time'] + "\n" + item['read_count']
print(text)
print('======================')
return item4、修改settings配置
BOT_NAME = 'scrapydemo'
SPIDER_MODULES = ['scrapydemo.spiders']
NEWSPIDER_MODULE = 'scrapydemo.spiders'上面三行是系统自动配置的,不需要修改,我们主要添加下列代码:
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
ITEM_PIPELINES = {
'scrapydemo.pipelines.ScrapydemoPipeline': 300,
}5、实现spider
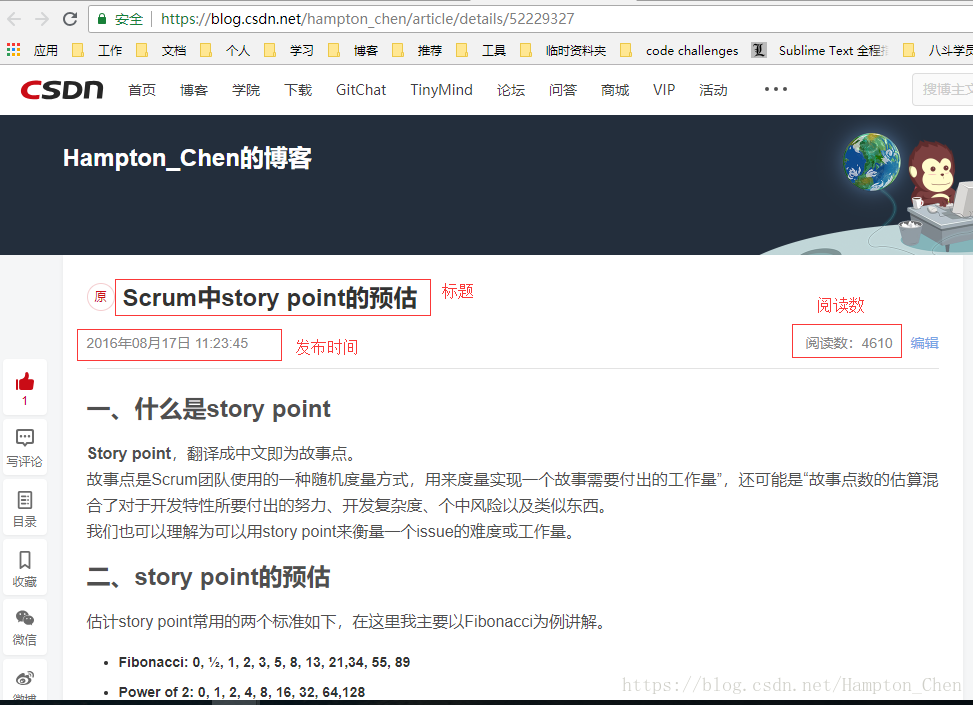
在实现spider之前,我们需要通过浏览器打开我们要抓取的目标网站,通过F12打开页面调试窗口,找到我们要抓取的数据对应的element,如下图:
Spider是一个继承自scrapy.contrib.spiders.CrawlSpider的Python类,有三个必需的定义的成员
name: 名字,这个spider的标识,在爬虫项目中是唯一的
start_urls:一个url列表,spider从这些网页开始抓取
parse():一个方法,当start_urls里面的网页抓取下来之后需要调用这个方法解析网页内容,同时需要返回下一个需要抓取的网页,或者返回items列表
所以在spiders目录下新建一个spider,csdn.py:
# -*- coding: utf-8 -*-
import scrapy
from scrapydemo.items import ScrapydemoItem
class CsdnSpider(scrapy.Spider):
name = "csdn"
allowed_domains = ["blog.csdn.net"]
start_urls = ['https://blog.csdn.net/hampton_chen/article/details/52229327/']
def parse(self, response):
item = ScrapydemoItem()
item['title'] = response.xpath('//h1[@class="title-article"]/text()').extract()[0]
item['time'] = response.xpath('//span[@class="time"]/text()').extract()[0]
item['read_count'] = response.xpath('//span[@class="read-count"]/text()').extract()[0]
yield item至此代码已经写完,接下来就是如何启动爬虫。
启动爬虫
运行程序有两种方法:
1、直接命令行启动
进入到项目的根目录下,执行下列命令:
scrapy crawl csdn2、新建一个.py文件,写入启动命令,例如run.py:
# -*- coding: utf-8 -*-
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'csdn'])注意:crawl后面跟的是spider的name,不是项目名
执行命令得到结果如下图所示:














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









