







Tensorflow基础知识
reduce()函数
reduce()函数在库functools里,如果要使用它,要从这个库里导入。
reduce函数是把多个参数合并的操作,也就是从多个条件简化的结果
示例
from functools import reduce
result = reduce(lambda x, y: x+y, [1, 2, 3, 4, 5])
print(result)
'''
15
'''
在这个例子里,其实计算过程是这样的:
((((1+2)+3)+4)+5)
定义:
reduce(function, sequence[, initial]) -> value
function参数是一个有两个参数的函数,reduce依次从sequence中取一个元素,和上一次调用function的结果做参数再次调用function。
第一次调用function时,如果提供initial参数,会以sequence中的第一个元素和initial作为参数调用function,否则会以序列sequence中的前两个元素做参数调用function。
reduce(lambda x, y: x + y, [2, 3, 4, 5, 6], 1)
'''
21
'''
# ( (((((1+2)+3)+4)+5)+6) )
Batch normalization
归一化(normalization)
将一批不太标准的数据统一到指定的格式.
我们在数据处理时常用的是将一组范围差距较大或者单位不同的数据依据一定规则变化到指定的范围之内。
BN来源:
有之前的工作说明对图像的像素值分布变换为以0为均值,单位方差的正态分布数值时(这种操作被称为whiten),可以加速网络收敛。现在换作深度神经网络每一隐藏层的输入也可以做whiten吧?这样BN出现了。
基本思想:具体参考
让每个隐层节点的激活输入分布固定下来
BN的基本思想其实相当直观:
因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,
这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。
tf.GraphKeys.REGULARIZATION_LOSSES
参考
tensorflow regularizers
对参数正则化分为两步:
- 创建一个正则方法(函数/对象)
- 将这个正则方法(函数/对象),应用到参数上
创建一个正则方法函数:
-
tf.contrib.layers.l1_regularizer(scale, scope=None)返回一个用来执行
L1正则化的函数,函数的签名是func(weights).参数:
- scale: 正则项的系数.
- scope: 可选的
scope name
-
tf.contrib.layers.l2_regularizer(scale, scope=None)返回一个执行L2正则化的函数.
-
tf.contrib.layers.sum_regularizer(regularizer_list, scope=None)返回一个可以执行多种(个)正则化的函数.意思是,创建一个正则化方法,这个方法是多个正则化方法的混合体.
参数:
regularizer_list: regulizer的列表
应用正则化方法到参数上:
tf.contrib.layers.apply_regularization(regularizer, weights_list=None)
先看参数
-
regularizer:就是我们上一步创建的正则化方法 -
weights_list: 想要执行正则化方法的参数列表,如果为None的话,就取GraphKeys.WEIGHTS中的weights.
函数返回一个标量Tensor,同时,这个标量Tensor也会保存到GraphKeys.REGULARIZATION_LOSSES中.这个Tensor保存了计算正则项损失的方法.
tensorflow中的Tensor是保存了计算这个值的路径(方法),当我们run的时候,tensorflow后端就通过路径计算出Tensor对应的值
现在,我们只需将这个正则项损失加到我们的损失函数上就可以了.
如果是自己手动定义
weight的话,需要手动将weight保存到GraphKeys.WEIGHTS中,但是如果使用layer的话,就不用这么麻烦了,别人已经帮你考虑好了.(最好自己验证一下tf.GraphKeys.WEIGHTS中是否包含了所有的weights,防止被坑)
tf.square()、tf.pow()、tf.math.pow()函数介绍和示例
1. tf.square():对各元素求平方
import tensorflow as tf
X = tf.constant([1, 2, 3, 4], dtype=tf.float32, name=None)
Y = tf.square(X) # 平方操作
with tf.Session() as sess:
print(sess.run(Y))
'''
[ 1. 4. 9. 16.]
'''
2. tf.pow(x, y, name=None) : 幂值计算操作,即 x^y
import tensorflow as tf
x = tf.constant(2, dtype=tf.float32)
y = tf.constant(3, dtype=tf.float32)
z = tf.pow(x, y) # 标量^标量操作
X1 = tf.constant(3, dtype=tf.float32)
Y1 = tf.constant([1, 2, 3], dtype=tf.float32)
Z1 = tf.pow(X1, Y1) # 标量^向量操作(矩阵同理)
X2 = tf.constant([[1, 2, 3], [4, 5, 6]], dtype=tf.float32)
Y2 = tf.constant([[2,2,2],[3,3,3]], dtype=tf.float32)
Z2 = tf.pow(X2, Y2) # 矩阵^矩阵操作(向量同理),对应位置的值进行幂值计算
with tf.Session() as sess:
print(sess.run(z))
print('='*30)
print(sess.run(Z1))
print('='*30)
print(sess.run(Z2))
'''
8.0
==============================
[ 3. 9. 27.]
==============================
[[ 1. 4. 9.]
[ 64. 125. 216.]]
'''
tf.math.pow(x, y, name=None): 同 tf.pow(x, y, name=None)
tf.gather
该接口的作用:就是抽取出params的第axis维度上在indices里面所有的index
tf.gather(params, indices, validate_indices=None, axis=None, batch_dims=0, name=None )
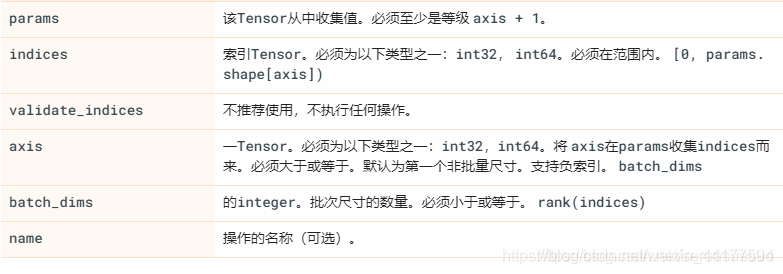
举例:
input =[ [[[1, 1, 1], [2, 2, 2]],
[[3, 3, 3], [4, 4, 4]],
[[5, 5, 5], [6, 6, 6]]],
[[[7, 7, 7], [8, 8, 8]],
[[9, 9, 9], [10, 10, 10]],
[[11, 11, 11], [12, 12, 12]]],
[[[13, 13, 13], [14, 14, 14]],
[[15, 15, 15], [16, 16, 16]],
[[17, 17, 17], [18, 18, 18]]]
]
print(tf.shape(input))
with tf.Session() as sess:
output=tf.gather(input, [0,2],axis=0)#其实默认axis=0
print(sess.run(output))
线性代数模块
- 伴随矩阵(
tf.linalg.adjoint) - 行列式的值(
tf.linalg.det) - 转化为对角阵(
tf.linalg.diag) - 求解特征值和特征向量(
tf.linalg.eigh) - 行列式求逆(
tf.linalg.inv) - 矩阵乘法(
tf.linalg.matmul) - 矩阵转置(
tf.linalg.matrix_transpose) - QR分解(
tf.linalg.qr) - SVD奇异值分解(
tf.linalg.svd) - LU分解(
tf.linalg.lu) - 行列式的迹(
tf.linalg.trace)
数学模块
- 求绝对值(
tf.math.abs) - 对给定的
tensor列表中所有tensor的元素做element-wise的累加和(tf.accumulate_n) - 三角函数(
tf.math.sin,tf.math.cos,tf.math.tan) - 反三角函数(
tf.math.acos,tf.math.asin,tf.math.atan) - 双曲函数(
tf.math.sinh,tf.math.cosh,tf.math.tanh) - 反双曲余弦函数(
tf.math.asinh,tf.math.acosh) - Bessel样条拟合(
tf.math.bassel_i0,tf.bassel_i0e,tf.math.bessel_i1,tf.math.bassel_i1e) - 取整(
tf.math.ceil, tf.math.floor) - 沿某个维度进行的运算(
tf.math.reduce_any,tf.math.reduce_std,tf.math.reduce.mean, …)














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









