
ShuffleNet v2 轻量级网络解读

ShuffleNet V2:Pracitcal Guidelines For Efficient CNN Architecture Design
2018年论文作者团队 旷视科技 清华大学
本文要解决的问题
在对于小型网络的性能评价标准中常用的是计算复杂度FLOPs,在这其中还有一个非常关键的评价标准是Speed运行速度,这通常收到计算机内存存储和运行平台等因素的影响。本文提出了一个新的网络ShuffleNet v2,对卷积网络在轻量级优化的参数量和运行速度等方面进行研究分析。
内容介绍
深度卷积网络不断发展,出现了很多优秀的网络结构从早期的AlexNet到后来VGG,GooLeNet,ResNet,DenseNet,ResNeXt,SENet等等,这些网络都大幅度促进了计算机视觉任务的发展,在ImageNet数据集分类分类任务上的Accuracy不断提高。
除了提升视觉任务的准确率,网络模型的计算复杂度也是一个非常重要的因素,尤其当目标平台硬件环境受限的情况下,例如在自动驾驶中需要极低的延迟。这就促使了一些轻量级网络的研究出现,他们在模型运行速度和准确度之间保持了一个较好的平衡,像是Xception, MobileNet, MobileNet V2, ShuffleNet 还有 CondenseNet等等。在这其中,分组卷积Group Conv 和 深度卷积 depth-wise conv 对于这些网络至关重要。
衡量网络复杂度主要评价指标是 float-point opertions, FLOPS浮点运算。在本文看来,这不能直接作为网络的评价标准,取而代之的应该是 Speed速度和Latency网络延迟等。
下表所示的是ShuffleNet V2与主流轻量级网络在ImageNet数据集上性能对比。
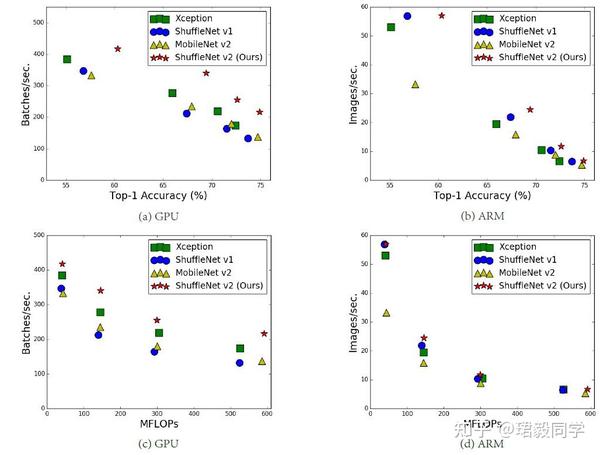

运算浮点数和运行速度的差异
运算浮点数和运行速度的差异主要包括两个主要方面。
首先是 memory access cost (MAC) 存储访问成本,这个因素对于组卷积运行时间有着很大的运行成本。
再者是degree of parallelism 并行程度。在相同计算量下,并行程度高的网络要比地的网络速度快很多。
在计算量相等的情况,由于实现平台的不一样,最后所呈现的网络运行时间也就不一样。
早期的一些工作,是使用张量分解在加速矩阵乘法过程。后来的工作证实虽然计算量降低了75%,但是GPU上的运行时间却变慢了。作者认为是CUDNN加速库主要是对3x3conv 进行优化的原因。
本文思路
基于以上的分析,作者作者认为在构建高效网络的时候,有两点因素需要着着重考虑:首先是网络性能最直接的评估标准,例如网络运行速度。二是,这样的性能评估标准也需要取决于对应的部署平台。
高效网络的构建
本实验平台分别部署在:
GPU:NVIDIA GeForce GTX 1080Ti
ARM: Qualcomm Snapdragon 810 高通骁龙810处理器
下表是关于 ShuffleNet V1 和 MobileNet V2 网络组件运行速度统计
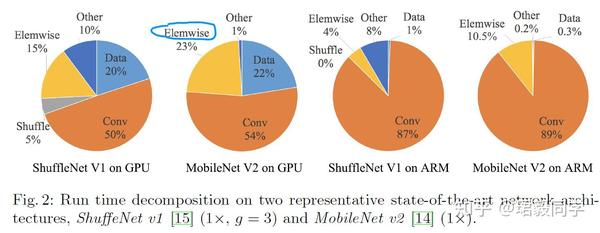
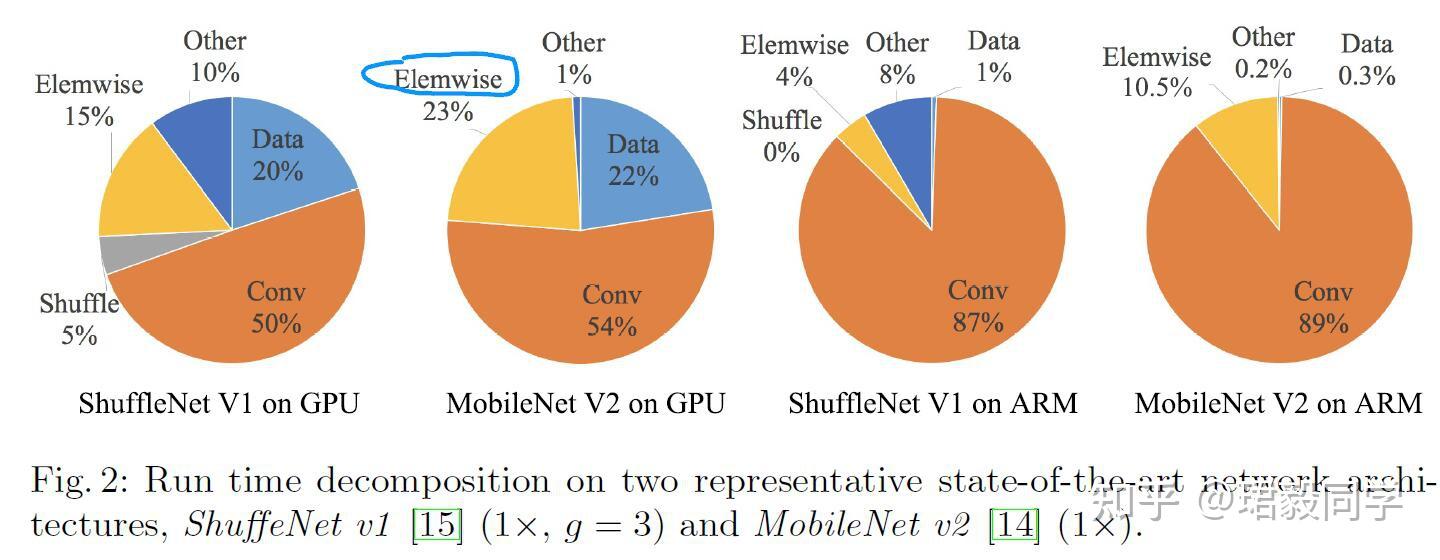
可以看到 FLOPs卷积运算只占据了总运行时间的绝大部分,其余的还包括数据输入输出,数据打乱,元素级处理相关操作(张量相加,激活函数处理等)。
因此,我们可以说FLOPs评价标准对于运行时间并不是一个准确的估计。
高效网络准则(一) : 相等的通道宽度可以降低存储访问成本
深度可分离卷积被广泛应用在现代主流网络中,其中的 1x1 conv占据了发部分模型复杂度,这个卷积的形状主要由两个参数控制:输入通道数 c_1 和输出通道数 c_2 。
设 h,w 为特征图的空间大小,则1x1 conv 的计算量FLOPs为 B=hwc_1c_2 。
存储访问成本为 MAC=hw(c_1+c_2)+c_1c_2 。
从均值不等式,可以得到,
公式(1) \mathrm{MAC} \geq 2 \sqrt{h w B}+\frac{B}{h w}
也就是说,在给定计算量的限制情况下,MAC是有下界的。
所得到的结论是理论性的,通常情况下很多设备的缓存都是有限的,虽然现在很多计算库都采取了复杂的策略来最大化利用缓存,但是实际上MAC的值跟理论上的值是存在偏差的。
为了验证这个结论,下表进行了实验分析。测试网络由10个重复块堆叠而成,其中每个块包含两个卷积层,输入通道是 c_1 ,输出通道是 c_2 。
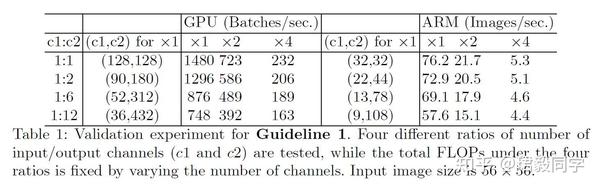

从表中的数据可以得到:当 c_1:c_2 值接近 1:1的时候,MAC值越来越小,网络运行的评估速度是越来越快的。
高效网络准则(二) : 大量的分组卷积数量会增加存储访问
分组卷积是当下流程CNN网络主要的组成部分,通多改变通道的稀疏性关系大幅度降低了FLOPs复杂度。但是在另一个方面,在给定FLOPs的情况下它高效利用的通道关系并且增加了网络的容量体积,也就是增加了MAC。
结合上面的公式(1),我们可以得到MAC 与 1x1 conv FLOPs的关系:
公式(2) \begin{aligned} \mathrm{MAC} &=h w\left(c_{1}+c_{2}\right)+\frac{c_{1} c_{2}}{g} \\ &=h w c_{1}+\frac{B g}{c_{1}}+\frac{B}{h w} \end{aligned}
其中 g 是分组数量,计算量 B = \frac{hwc_1c_2}{g}
可以看到,在给定输入 c_1\times h\times w ,计算成本 B 和MAC都会逐渐提高。
为了实际验证上面的结论,构建了10层 pointwise group 网络,测试结果如下表所示,
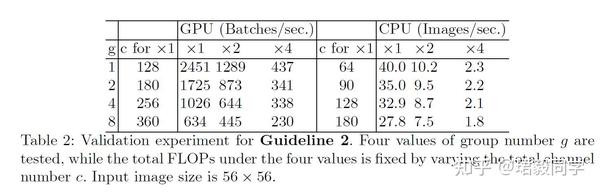

在总计算量固定的情况下,改变分组的数量,可以看到使用分组数量越多,实际运行速度越慢。
因此在选择运行平台和实际视觉任务的情况下,要非常谨慎使用分组卷积的数量。*建议使不要使用很多的分组卷积数量,这样会产生更多的通道数,从而会提高精确度,但是实际上,快速增加的计算成本会远远超过精确度提升所带的效益。
高效网络准则(三) : 网络分支过多会降低其并行化程度
在GoogLeNet,Inception V1,V2,V3等网路中每个单元块使用了“multi-path”多分支结构。
使用“分支块操作”来代替大的操作过程。
虽然这些分支结构在提高精确度方面有一定的提升作用,但是当在拥有大的并行计算设备像是GPU时会降低其精确度。
为了验证网络分支对性能的影响,作者在这里进行了不同分支程度网络的对比实验。
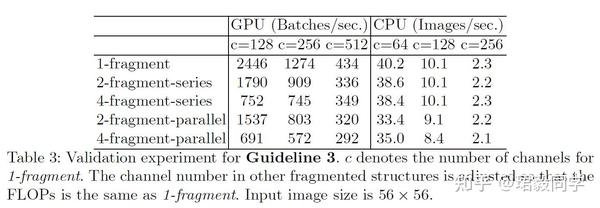

从表中的数据可以得知,网络过多的分支在GPU设备上会大幅度降低运行速度。
而在ARM平台上速度降低的相对平缓。
高效网络准则(四) : 元素级操作是不可忽略的
在前面网络运行时间各个成分占比中发现,像是一些元素级的操作也占据了相当的一部分时间,尤其是在GPU设备上。他们的计算量相对较小,但是MAC值却很大。
作者推断像是深度卷积这样的元素级操作,通常有较高的 MAC / FLOPs 值。
为了验证上面的假设,作者做了相关实验进行研究,如下表
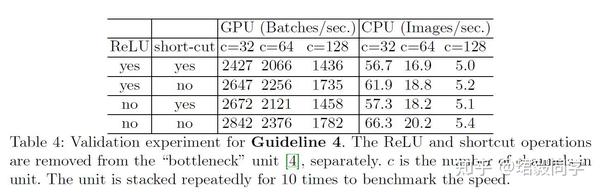

在对比实验中可以发现,当ReLU激活函数和短连接路径被移除后,在GPU和ARM设备上,运行速度大约提升了约20%。
小结
由上面的研究分析,我们在设计一个高效网络时应该遵循以下几点建议:
- 使用平衡性的卷积(还有通道宽度)
- 谨慎使用分组卷积的数量
- 降低网络分支的数量
- 降低元素级操作次数
- 同时在实际使用也应该注意到操作平台的影响。
ShufflNet V2:高效的网络结构
在ShuffleNet V1中,面临的主要问题是在有限计算资源的情况下,特征通道数量不够多,为了解决这个问题,采取了两项新技术:pointwise group conv和 bottle-like 结构,与此同时,“通道打乱操作”引入到网络中增强信息的交互性。
如下图的(a)(b)所示。
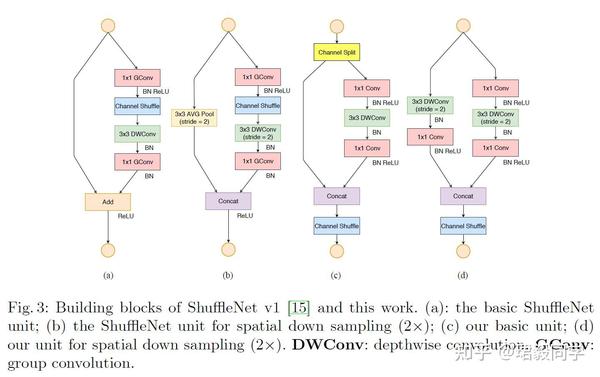

根据之前的分析,点卷积和瓶颈结构都在一定程度上增加了MAC值,这是一点是不能忽略的,尤其是对于轻量级网络。使用太多的卷积分组和元素级操作同样也是不可取。
所以要构建一个高效的网络模型,关键是如何在保持较高通道数量的同时,不能有太多的密集卷积数量和分组数量。
通道分离 ShuffleNet V2
根据以上的分析,作者引入了一个简单操作“channel split”通道分离操作,如图(c)所示。
- 在每个单元开始之前,输入通道`$c$`被分成两个分支`$c-c^{'}$`和`$c^{'}$`
- 根据准则三,其中一个分支保持恒等映射。
- 另外的分支包括三个具有相同输入输出通道卷积。
- 两个1x1卷积不再分组,因为开始的分支结构已经产生了两个分组。
- 然后,两个分支进行通道级融合操作。
- 最后在进行通道打乱操作,用来网络增强信息交互能力。
对于空间下采样操作,如图(d)所示,通道分离操作被移除,然后输出通道的数量翻倍。
图(c)(d)就是所提出的 ShuffleNet V2。
上面提出的模块单元经过多重堆叠以构建新的网络,为了简便起见,作者在这里设置 c^{'}={c} / {2}
总体网络结构如下表所示,
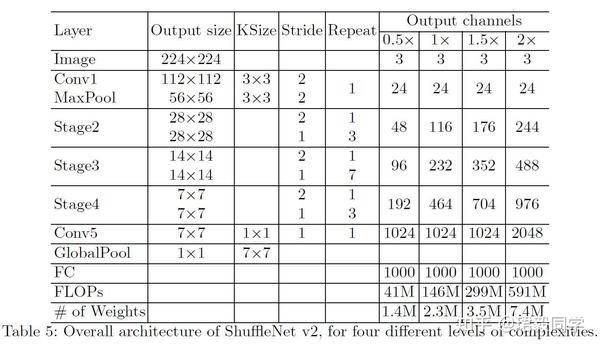

可以看到,与ShuffleNet V1基本类似,但有一处不同,就是在全局平均池化之前,添加了一个额外的1x1卷积操作。
其中ShuffleNet V2 0.5x ,ShuffleNet V2 1x 是对原始网络的模型缩减表示。
网络准确率分析
ShuffleNet v2 不仅速度快而且准确率也很高。这主要来源于他的网络设计,首先就是他的模块单元能够是网络有更多的通道数量和网络容量。其次就是,特征通道( c^{'}={c} / {2} )直接贯穿这个模块单元链接下一个模块,这可以被看做是一个特征再利用,与DenseNet和CondenseNet类似。
如下图(a)
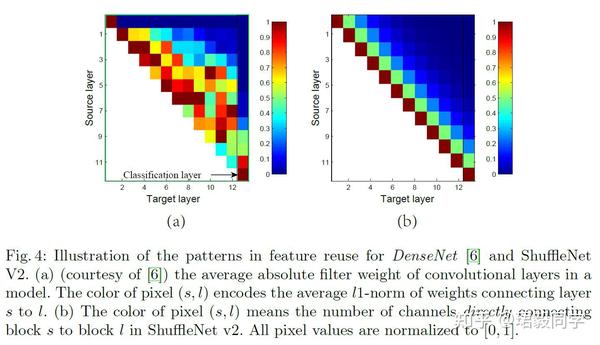
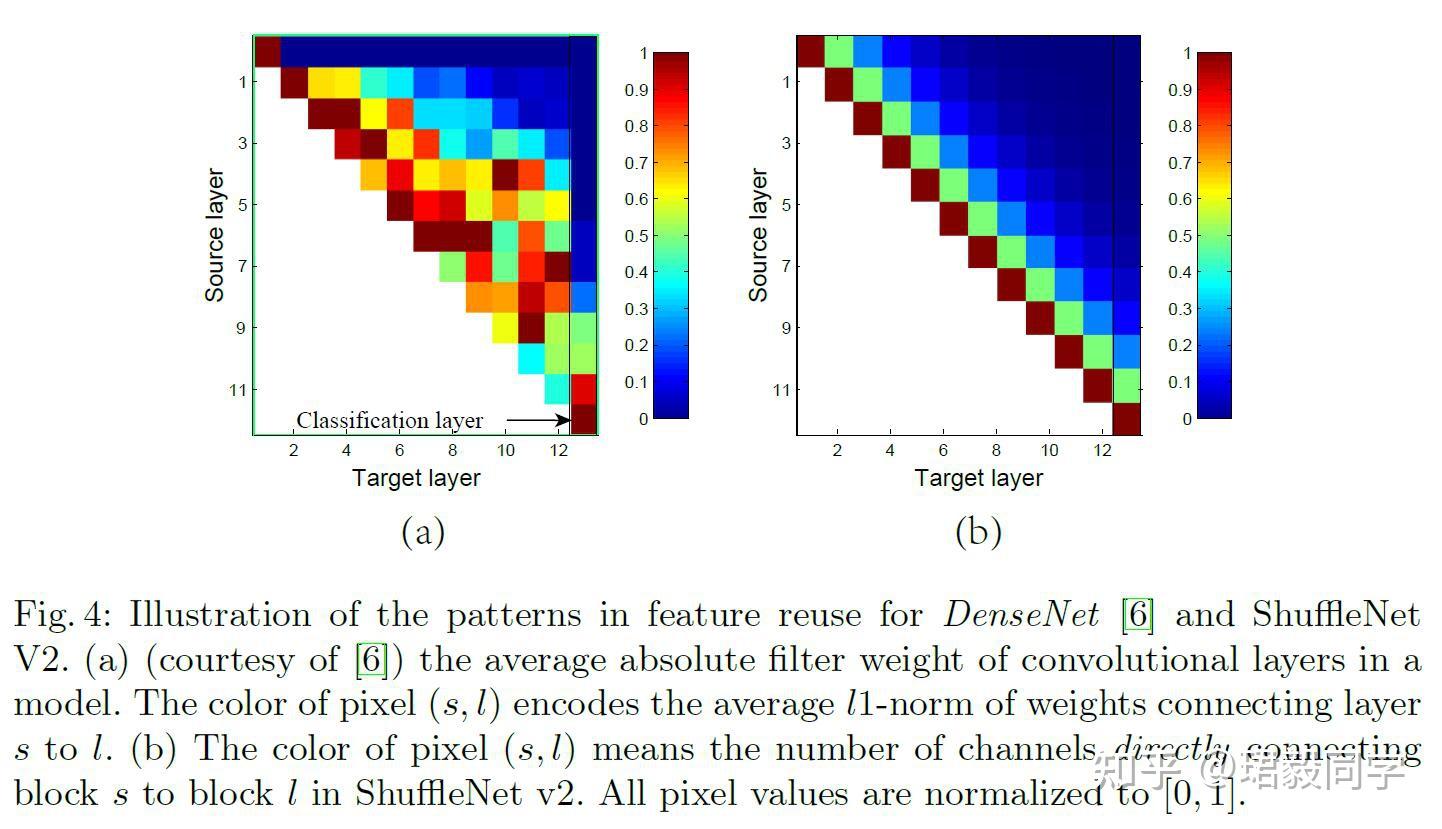
可以看到,临近层之间的连接性要比其他层体现的更加突出,但是如果在所有层都建立密集连接,可能会带来很大的冗余性。
在ShuffleNet V2中,如图(b)所示,在两个模块随着距离变成特征重利用性逐渐衰减。
ShuffleNet V2实现了特征重利用,并且达到了较高的准确率,比DenseNet更加高效。
实验分析
本实验在ImageNet2012分类数据集上训练,在验证集上测试,与ShuffleNet v1, MobileNet v2, Xception, DenseNet对比分析。
如下表所示,
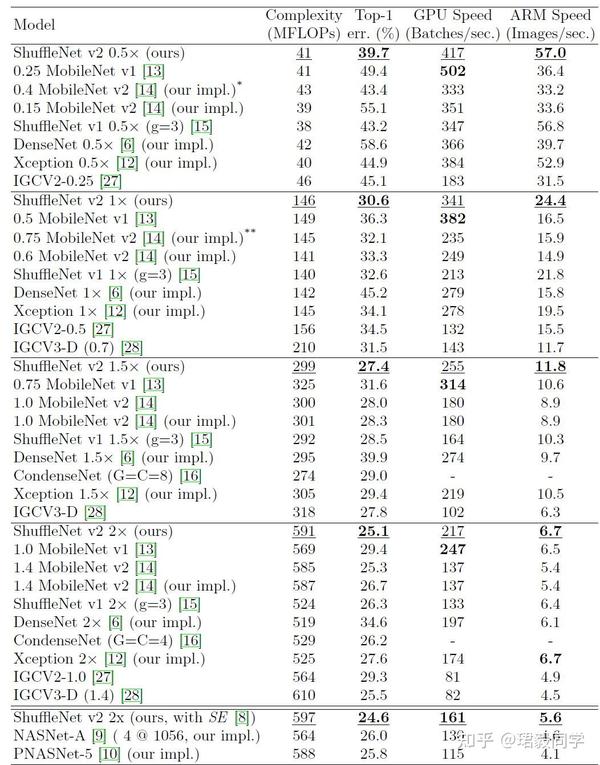

精确率 vs. FLOPs
- ShuffleNet v2模型很大幅度上优于其他网络,尤其是在很小计算成本的情况下。
推理速度 vs. FLOPS/Accuracy
如下表所示,
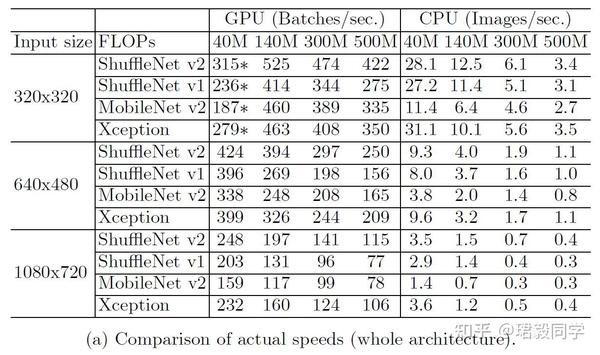
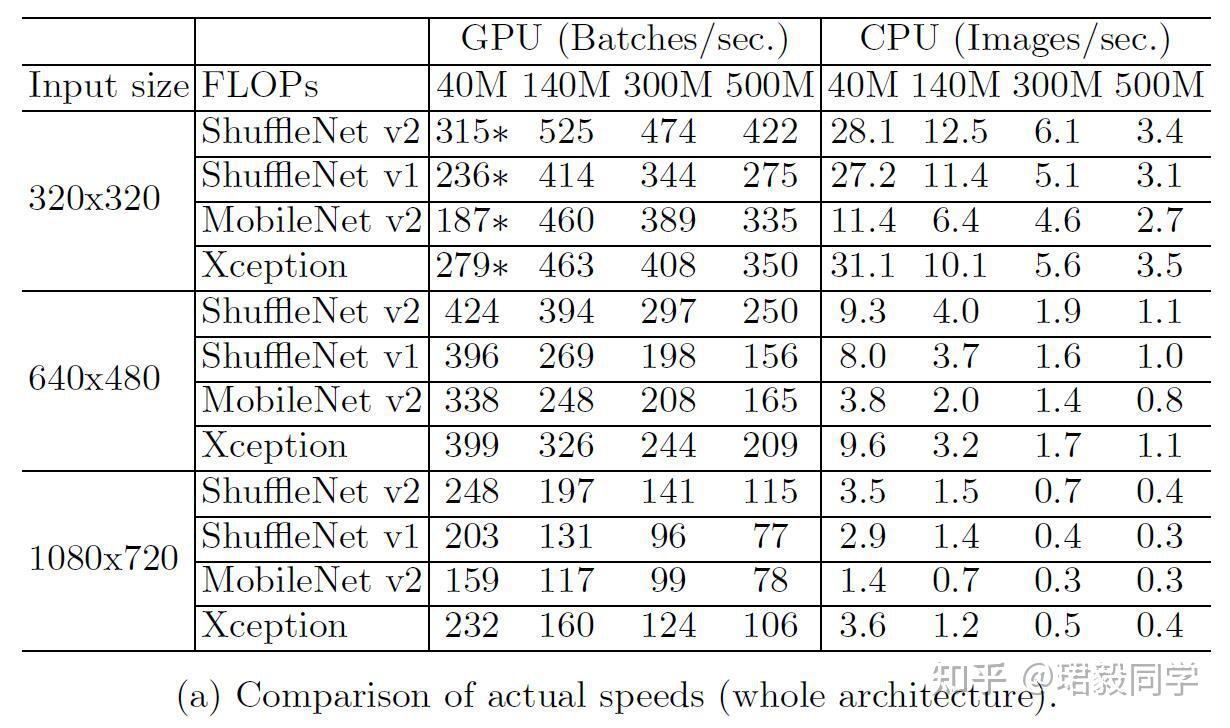
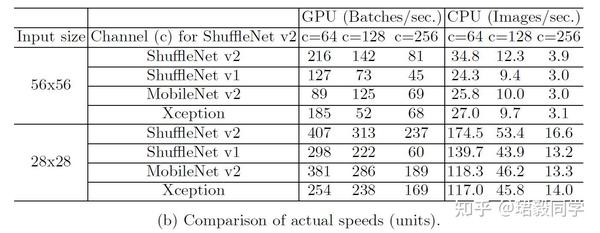
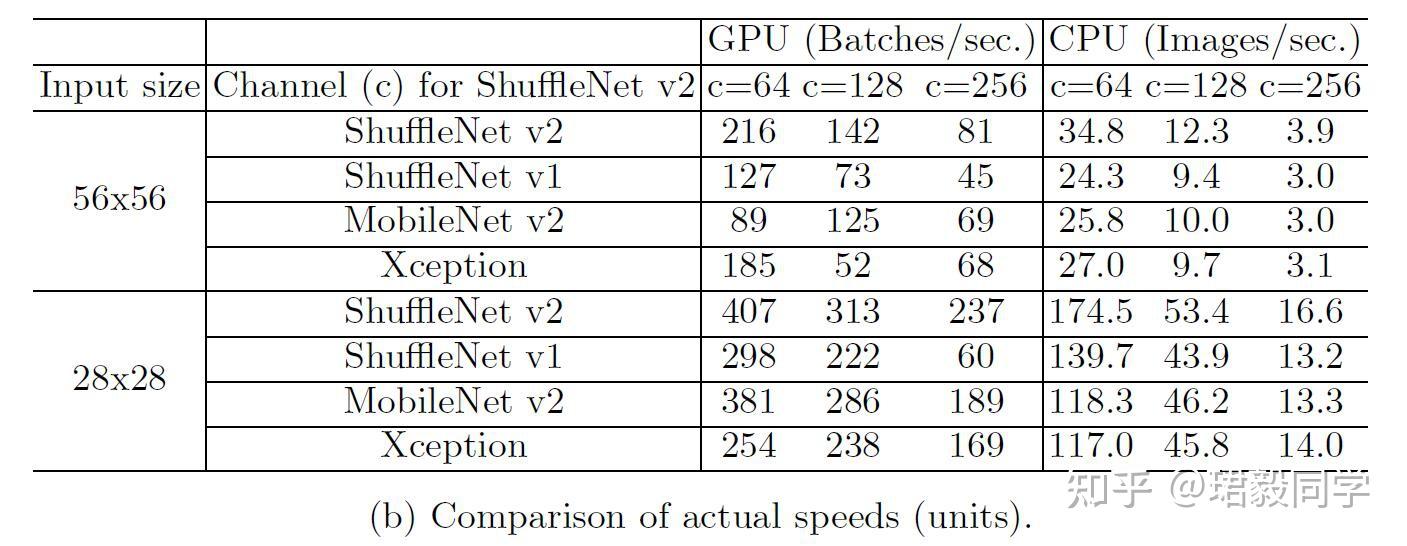
- ShuffleNet v2 与 MobileNet v2, ShuffleNet v1 和Xception相比,在运行速度方面要快很多。
- 在500MFLOPs GPU设备上,ShuffleNet v2比Mobile v2 快 58%,比ShuffleNet v1快63%,比Xception快25%。
与其他网络的兼容性
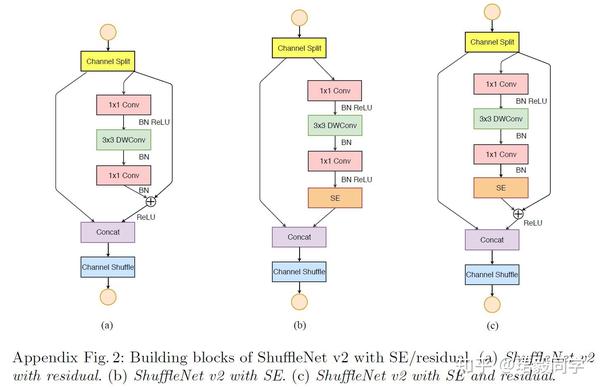
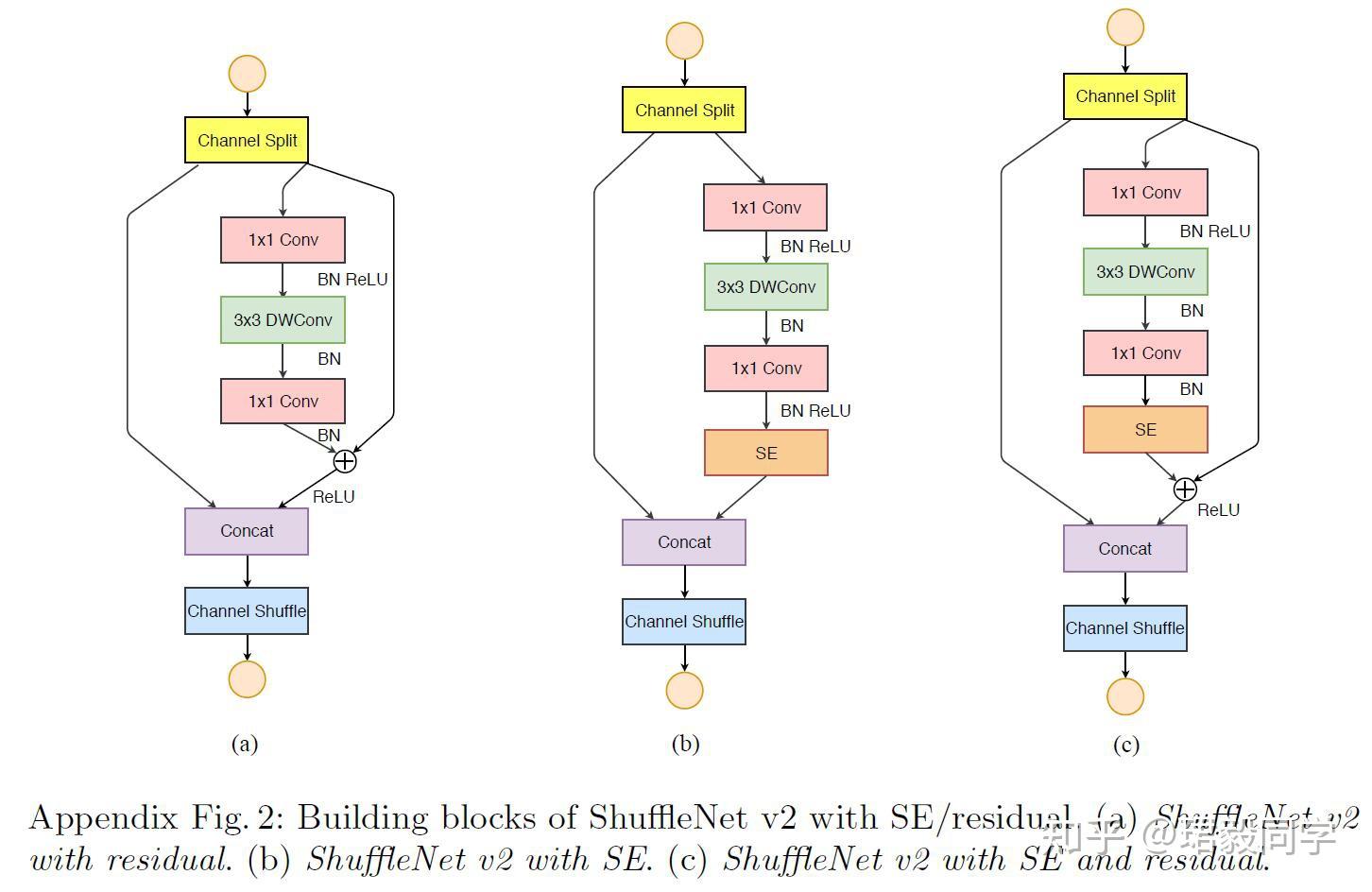
- ShuffleNet v2 可以与其他模块单元进行组合从而进一步提高网络性能。当与SENet进行组合使用时,在损失一点速度的情况下,精度可以提升0.5%。
网络模型的泛化性能
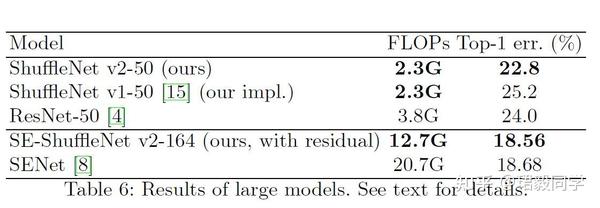
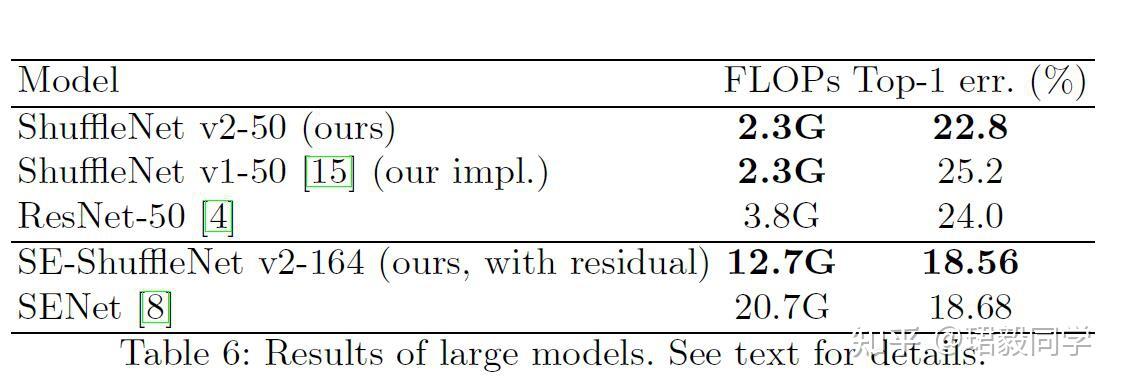
- 可以看到50层的ShuffleNet v2比 ShuffleNet v1 分类错误率要低很多,减少了ResNet将近40%的参数量。
- 对于深层网络164层的ShuffleNet v2 同时加入了SE模块,在拥有更少参数的同时,达到了最好的分类性能。
ShuffleNet 不同层数网络配置表

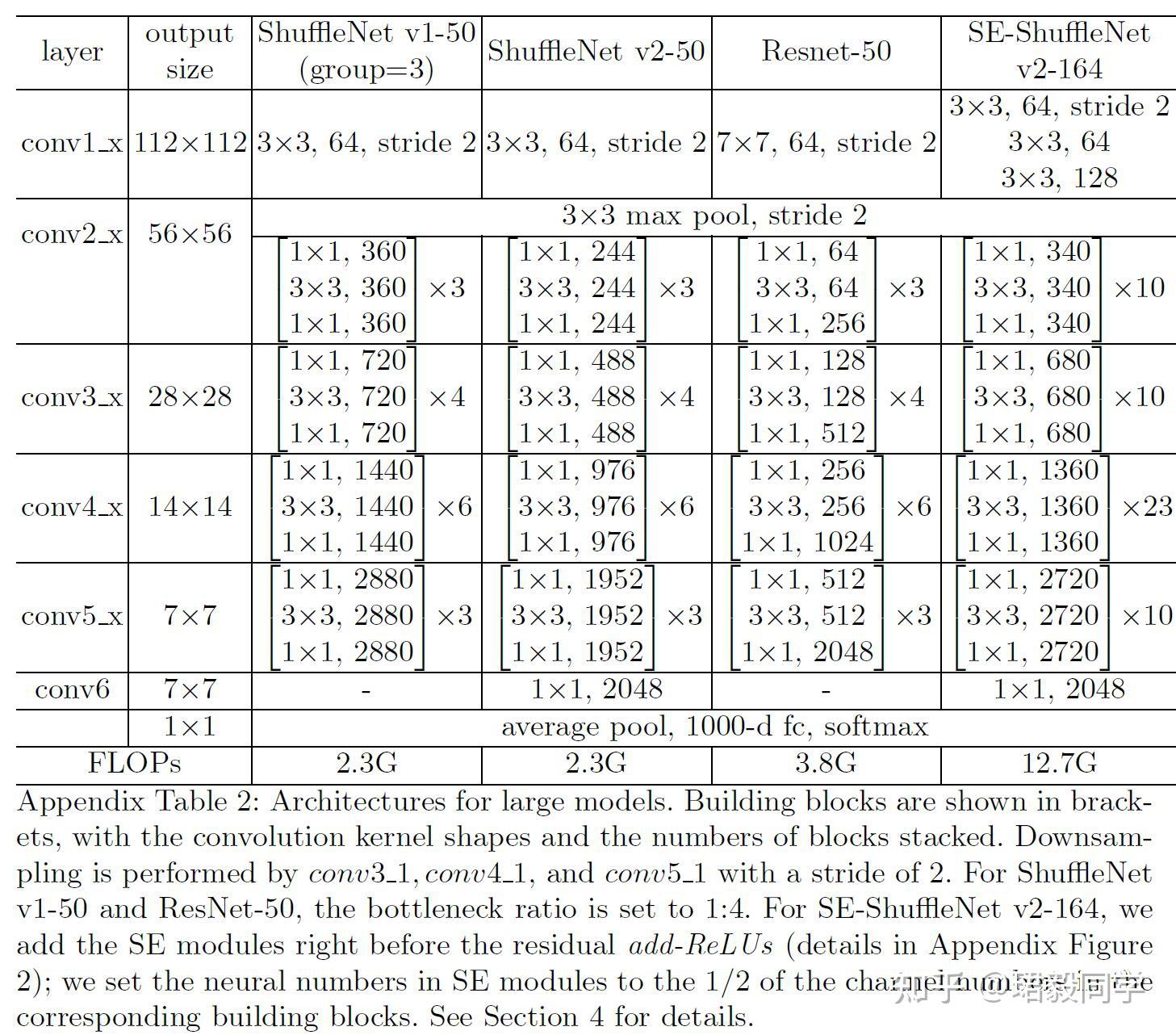
目标检测数据集测试
在COCO数据集使用Light-Head RCNN算法进行训练,在minival数据集上进行测试,下表是测试结果。


- 在测试的所有模型中,ShuffleNet V2表现最好。
结合上面分类性能表分析我们可以得到:
在分类准确率方面
ShuffleNet v2 >= MobileNet v2 > ShuffleNet v1 > Xception
在检测方面
ShuffleNet v2 > Xception >= ShuffleNet v1 >= MobileNet v2
这样结果可能因为Xception网络中感受野能获得更多的特征信息。
根据这个观察作者又对ShuffleNet v2进行了改进,在原先的网络中添加了额外的3x3深度卷积,ShuffleNet v2*,在牺牲一点速度的同时,进一步提高了精确度。
总结
本文对网络结构性能评价标准速度和计算量做了详细分析,并提出轻量级网络设计应该要考虑的准则,提出了ShuffleNet v2,其性能超越当下主流网络,达到了较高的水平。
实现代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class ShuffleBlock(nn.Module):
def __init__(self, groups=2):
super(ShuffleBlock, self).__init__()
self.groups = groups
def forward(self, x):
'''Channel shuffle: [N,C,H,W] -> [N,g,C/g,H,W] -> [N,C/g,g,H,w] -> [N,C,H,W]'''
N, C, H, W = x.size()
g = self.groups
return x.view(N, g, C//g, H, W).permute(0, 2, 1, 3, 4).reshape(N, C, H, W)
class SplitBlock(nn.Module):
def __init__(self, ratio):
super(SplitBlock, self).__init__()
self.ratio = ratio
def forward(self, x):
c = int(x.size(1) * self.ratio) # [0,1,2,3] size(1) = 2 取得是维度上的值
return x[:, :c, :, :], x[:, c:, :, :]
class BasicBlock(nn.Module):
def __init__(self, in_channels, split_ratio=0.5):
super(BasicBlock, self).__init__()
self.split = SplitBlock(split_ratio)
in_channels = int(in_channels * split_ratio)
self.conv1 = nn.Conv2d(in_channels, in_channels,
kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv2 = nn.Conv2d(in_channels, in_channels,
kernel_size=3, stride=1, padding=1, groups=in_channels, bias=False)
self.bn2 = nn.BatchNorm2d(in_channels)
self.conv3 = nn.Conv2d(in_channels, in_channels,
kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(in_channels)
self.shuffle = ShuffleBlock()
def forward(self, x):
x1, x2 = self.split(x)
out = F.relu(self.bn1(self.conv1(x2)))
out = self.bn2(self.conv2(out))
out = F.relu(self.bn3(self.conv3(out)))
out = torch.cat([x1, out], 1)
out = self.shuffle(out)
return out
class DownBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(DownBlock, self).__init__()
mid_channels = out_channels // 2
# left
self.conv1 = nn.Conv2d(in_channels, in_channels,
kernel_size=3, stride=2, padding=1, groups=in_channels, bias=False)
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv2 = nn.Conv2d(in_channels, mid_channels,
kernel_size=1, bias=False)
self.bn2 = nn.BatchNorm2d(mid_channels)
# right
self.conv3 = nn.Conv2d(in_channels, mid_channels,
kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(mid_channels)
self.conv4 = nn.Conv2d(mid_channels, mid_channels,
kernel_size=3, stride=2, padding=1, groups=mid_channels, bias=False)
self.bn4 = nn.BatchNorm2d(mid_channels)
self.conv5 = nn.Conv2d(mid_channels, mid_channels,
kernel_size=1, bias=False)
self.bn5 = nn.BatchNorm2d(mid_channels)
self.shuffle = ShuffleBlock()
def forward(self, x):
# left
out1 = self.bn1(self.conv1(x))
out1 = F.relu(self.bn2(self.conv2(out1)))
# right
out2 = F.relu(self.bn3(self.conv3(x)))
out2 = self.bn4(self.conv4(out2))
out2 = F.relu(self.bn5(self.conv5(out2)))
# concat
out = torch.cat([out1, out2], 1)
out = self.shuffle(out)
return out
class ShuffleNetV2(nn.Module):
def __init__(self, net_size):
super(ShuffleNetV2, self).__init__()
out_channels = configs[net_size]['out_channels']
num_blocks = configs[net_size]['num_blocks']
self.conv1 = nn.Conv2d(3, 24, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(24)
self.in_channels = 24
self.layer1 = self._make_layer(out_channels[0], num_blocks[0])
self.layer2 = self._make_layer(out_channels[1], num_blocks[1])
self.layer3 = self._make_layer(out_channels[2], num_blocks[2])
self.conv2 = nn.Conv2d(out_channels[2], out_channels[3],
kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels[3])
self.linear = nn.Linear(out_channels[3], 10)
def _make_layer(self, out_channels, num_blocks):
layers = [DownBlock(self.in_channels, out_channels)]
for i in range(num_blocks):
layers.append(BasicBlock(out_channels))
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
# out = F.max_pool2d(out, 3, stride=2, padding=1)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = F.relu(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
configs = {
0.5: {
'out_channels': (48, 96, 192, 1024),
'num_blocks': (3, 7, 3)
},
1: {
'out_channels': (116, 232, 464, 1024),
'num_blocks': (3, 7, 3)
},
1.5: {
'out_channels': (176, 352, 704, 1024),
'num_blocks': (3, 7, 3)
},
2: {
'out_channels': (224, 488, 976, 2048),
'num_blocks': (3, 7, 3)
}
}
def test():
net = ShuffleNetV2(net_size=0.5)
x = torch.randn(3, 3, 32, 32)
y = net(x)
print(y.shape)
test()