
Reactor模式介绍

概述
阅读本文前,读者应了解基本的linux下socket的编程知识,了解常见的socket函数,同时对IO多路复用epoll有所了解。
1. 常见的网络模型
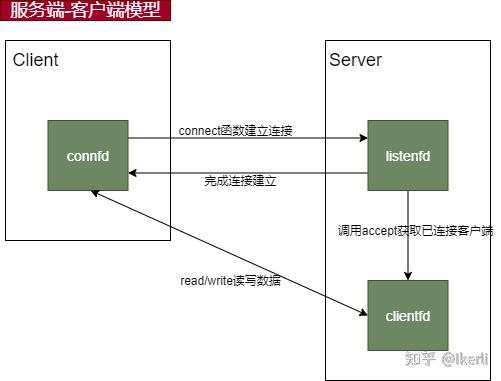
1.1 服务端-客户端连接原理
服务器编程中通常涉及三类socketfd, 先简单定义一下:
connfd:客户端调用connect与服务端建立连接。
listenfd: 服务端的监听套接字。
clientfd:服务端获取的已连接客户端套接字。

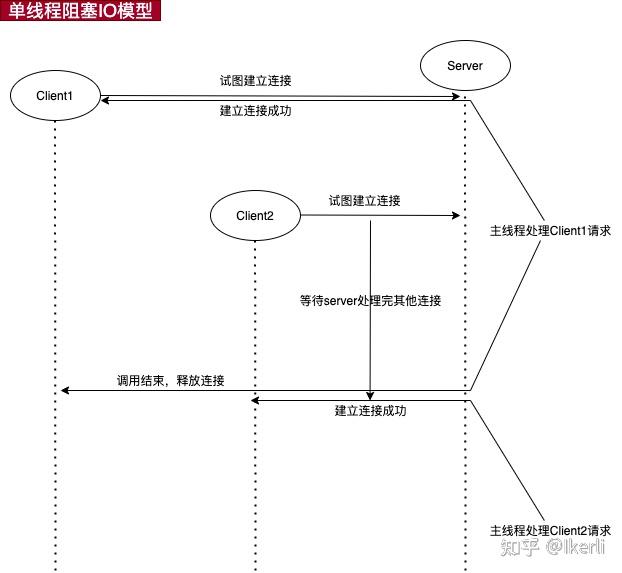
1.2 单线程阻塞模型
单线程阻塞式模型是最基础的网络模型,也是学习服务器开发中每个人接触的第一个网络模型。
单线程阻塞模型中:服务端只有一个线程,阻塞在accept函数上,等待客户端对listenfd成功建立连接。成功连接后处理返回的 connfd,直到处理完后才关闭该connfd。
listenfd = socket(); // 初始化监听套接字
bind(); // 绑定监听套接字和服务端地址
listen(listenfd); // 监听
while(1) {
int clientfd;
// 主线程阻塞在 accept 上直到返回已连接套接字
if ((clientfd=accept()) >= 0) {
// 如果返回 大于0,代表有新连接产生
dothing(clientfd); // 处理请求
close(clientfd); // 关闭连接
}
}

这种模式最大的特点就是:服务端一次只能同时处理一个客户端连接。因此这种模型是无法用于高并发服务器的,甚至说他就不是一个并发的模型。。。
1.3 多线程阻塞模型
为了同时处理多个客户端请求,即支持并发,对单线程阻塞模型进行了改进,改进的措施也很简单,既然单个线程不够,那我增加线程数不就行了?
服务端对每个新连接都单独起一个线程去处理,主线程继续阻塞在accept上等待新连接。每当accept获取到新的connfd后,把这个connfd交给新的线程去处理。
listenfd = socket(); // 初始化监听套接字
bind(); // 绑定监听套接字和服务端地址
listen(listenfd); // 监听
while(1) {
if ((clientfd=accept()) >= 0) {
// 如果返回 大于0,代表有新连接产生
// 启动新的线程去处理这个连接 主线程继续while循环等待新的连接
new_thread(clientfd);
}
}

缺点:
- 系统最大线程数是有限的。对于突发的大量的客户端连接,不可能创建很多线程去处理连接。
- 线程的频繁切换也极度浪费系统资源。
线程池可能一定程度上解决上诉问题:
服务端首先创建一定数目的线程池备用,当新的客户连接来临后,利用负载均衡算法从线程池中取出一个线程去处理这个客户请求。一个线程可能同时被分配了多个clientfd。
1.3.1 阻塞
线程池的引入解决了线程频繁创建消耗的问题。但仔细考虑上面几个模型,都存在一个典型的问题:阻塞。
阻塞的地方有两处:
1. 主线程每次调用 accept 函数获取客户端连接是阻塞的。必须要等待能获取到新连接之后,accept函数才会返回,否则主线程一直阻塞在accept上。。
2. 子线程分配到新的客户端连接后,会对这个clientfd进行读写操作。但是对clientfd调用read(或write)也是阻塞的。必须要等待clientfd这个套接字满足可读(或可写)条件后read(或write)才会返回。
阻塞的缺点:当线程阻塞在某个accept、read、write等这些慢系统调用时,一阻塞就不知道要到什么时候才能解脱了。线程阻塞在这上面,又不能处理其他事务,导致白白地浪费线程资源,而且还不知道要浪费到好久。。
阻塞还有另一个缺点,不利于同时多个socketfd的处理。
考虑这样一种情况:某个线程T现在有两个待处理的客户端连接(clientfd1和clientfd2)。线程T串行的处理这两个请求:
// 线程T执行伪代码
void run() {
// 先处理 clientfd1
read(clientfd1);
dothing(clientfd1);
wirte(clientfd1);
// 再处理clientfd2
read(clientfd2);
dothing(clientfd2);
wirte(clientfd2);
}如果clientfd1一直没有可读事件,那么线程T就会一直阻塞在 read(clientfd1)上;而clientfd2永远得不到处理,即使clienfd2发生可读可写事件,但一直执行不到这里来;
简单来说,只要前面的socket阻塞了,后面的socket就会陷入无尽的等待中。
当然,有阻塞IO,自然也有非阻塞IO。那是不是直接修改为非阻塞IO就行了? 其实也不是,非阻塞IO虽然会立即返回结果,但我们不知道什么时候会返回我们期待的结果?也就是说,非阻塞IO只能保证立即返回结果给我,但不能保证他返回的结果是我想要的。
到这里,需要处理一个问题:
我希望某个东西能帮我管理多个套接字,通过它来检测多个socketfd的可读可写条件,当某个socketfd上产生了可读可写事件的时候通知我,我再来操作这个 socketfd,此时对其调用read/write/accept等函数也不会再阻塞了。
在计算机界有一句名言:计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决!
IO多路复用就是用来解决这个问题的中间件。
1.3.2 IO复用
对于accept、connect、read、write等系统调用,实际上都属于慢系统调用,他可能会永远阻塞直到套接字上发生 可读\可写 事件。事实上,通常不希望一直阻塞直到IO就绪,而应该等待IO就绪之后再通知我们过来处理。
IO复用可以通过 select、poll、epoll来实现。这里只简单说下epoll。
epoll就是实现这个功能的,使用epoll只需要三步:
- 调用epoll_create创建套接字epfd。
- 调用epoll_ctl 增加需要关心的套接字的事件,如 listenfd的可读事件。
- 调用epoll_wait沉睡,直到有关心的事件发生后epoll_wait会主动返回,此时我们去处理发生了IO事件的相应套接字即可。
具体的epoll用法这里不再细说。在这里把epoll看成一个黑匣子即可,暂时不关心原理。我们只需要将关心得套接字事件注册到epoll上,epoll就会在这些事件发生时通知我们。
1.4 Reactor模型
讲了这么多,终于轮到Reactor模式登场了。
什么是Reactor模式? Reactor模式又叫反应堆模式,是一种常见的高性能的服务器开发模式,著名的Netty、Redis等软件都使用到了Reactor模式。
Reacor模式是一种事件驱动机制,他逆转了事件处理的流程,不再是主动地等事件就绪,而是它提前注册好的回调函数,当有对应事件发生时就调用回调函数。 由陈硕所述,Reactor即为非阻塞IO + IO复用,单个Reactor的逻辑大致如下
while(!stop) {
// 1.取得下次定时任务的时间,与设定time_out去较大值,即若下次定时任务时间超过1s就取下次定时任务时间为超时时间,否则取1s
int time_out = Max(1000, getNextTimerCallback());
// 2.调用Epoll等待事件发生,超时时间为上述的time_out
int rt = epoll_wait(epfd, fds, ...., time_out);
if(rt < 0) {
// epoll调用失败。。
} else {
if (rt > 0 ) {
// 3. 以此处理发生IO时间的fd,调用其回调函数
}
}
}它的核心思想就是利用IO复用技术来监听套接字上的读写事件,一旦某个fd上发生相应事件,就反过来处理该套接字上的回调函数。
1.4.1 one loop per thread
Reactor模式只是一个框架,它可以由单个线程简单实现,也可以通过线程池实现主从reactor模式。
即一个线程有且只有一个reactor,执行以上loop循环。程序中通常有多个Reactor,例如一种常见的模式是mainReactor只监听connfd连接事件,当发生连接后就交给subReactor去监听IO事件。在这里由于要将新连接交给其他线程的reactor,那么reactor的实现就得是线程安全的。
为什么不能多个线程一个loop?
- 多个线程进行同一个loop,会导致大量的竞争条件,影响性能,这种做法也没多大意义。
- 多个线程同时沉睡在同一个epoll_wait上,可能会发生惊群效应。
为什么不能一个线程多个loop
1. reactor可以认为是一个死循环,一个线程只可能同时执行一个循环就可以了。
1.4.2 单Reactor服务器模型
单Reactor服务器模型就是只有一个主线程运行Reactor。整个线程有一个epoll句柄,用于管理所有的套接字。服务器将listenfd的读事件注册到epoll上,当epoll_wait返回时说明listenfd可读,即有新的连接建立。此时再调用accept函数获取新连接clientfd,然后将clientfd的读写事件也注册到这个epoll上,等待clientfd发生读写事件从epoll_wait返回后,再处理clientfd的事件。


// 单Reactor模型
while(!stop) {
// 1.取得下次定时任务的时间,与设定time_out去较大值,即若下次定时任务时间超过1s就取下次定时任务时间为超时时间,否则取1s
int time_out = Max(1000, getNextTimerCallback());
// 2.调用Epoll等待事件发生,超时时间为上述的time_out
int rt = epoll_wait(epfd, fds, ...., time_out);
if(rt < 0) {
// epoll调用失败。。
} else {
if (rt > 0 ) {
foreach (fd in fds) {
if (是listenfd的可读事件) {
// 如果是连接事件
1. 获取连接 clientfd = accept();
2. 将clientfd的IO注册到epoll上
} else {
// 不是连接事件,那就是clientfd的读写事件,此时需要处理业务逻辑
dothing(fds[i]);
}
}
}
}
}
对于clienfd发生读写事件后,需要进行业务逻辑处理。业务逻辑处理通常是耗时的,这会影响主线程的执行,也就是说主线程会等到 dothing(fds[i])做完之后才进入下一次循环过程。
加入线程池可以一定程度上优化:
// 单Reactor + 线程池模型
while(!stop) {
// 1.取得下次定时任务的时间,与设定time_out去较大值,即若下次定时任务时间超过1s就取下次定时任务时间为超时时间,否则取1s
int time_out = Max(1000, getNextTimerCallback());
// 2.调用Epoll等待事件发生,超时时间为上述的time_out
int rt = epoll(epfd, fds, ...., time_out);
if(rt < 0) {
// epoll调用失败。。
} else {
if (rt > 0 ) {
foreach (fd in fds) {
if (是listenfd的可读事件) {
// 如果是连接事件
1. 获取连接 clientfd = accept();
2. 将clientfd的IO注册到epoll上
} else {
// 不是连接事件,那就是clientfd的读写事件,此时需要处理业务逻辑
// 1.线程池里面取一个线程
// 2.用该线程处理这个套接字上的业务逻辑
thread = threadpoll.get();
thread.dothing(fd[i]);
}
}
}
}
}将业务逻辑处理也可以交给线程池来做,主线程继续进行Reactor循环。从而很大程度上减小了主线程的负担,提高并发量。这就是单Reactor+线程池的模型。
1.4.3 主从Reactor服务器模型
单Reactor模式+线程池能够很大程度上支持并发了,但还可以优化。注意到单Reactor模式只有一个Reactor线程,所有的关心套接字都需要注册到这个Reactor上。可以看到,这个主线程的Reactor既要负责客户端连接事件的处理(即关心listenfd的事件),又要关心已连接套接字的事件(即关心clientfd的io事件)。
能不能用多个Reactor,其中一个Reactor只监听listenfd,获取到新连接后就把clientfd甩给其他Reactor来监听呢?
这就是主从Reactor模式:


服务器有一个mainReactor和多个subReactor。
mainReactor由主线程运行,他作用如下:通过epoll监听listenfd的可读事件,当可读事件发生后,调用accept函数获取clientfd,然后随机取出一个subReactor,将cliednfd的读写事件注册到这个subReactor的epoll上即可。也就是说,mainReactor只负责建立连接事件,不进行业务处理,也不关心已连接套接字的IO事件。
subReactor通常有多个,每个subReactor由一个线程来运行。subReactor的epoll中注册了clientfd的读写事件,当发生IO事件后,需要进行业务处理。
更多技术博客欢迎关注我的个人同名公众号获取(无骚扰公告,微信公众号搜索 ikerli )。
