







set底层存储
redis的集合对象set的底层存储结构特别神奇,我估计一般人想象不到,底层使用了intset和hashtable两种数据结构存储的,intset我们可以理解为数组,hashtable就是普通的哈希表(key为set的值,value为null)。是不是觉得用hashtable存储set是一件很神奇的事情。
set的底层存储intset和hashtable是存在编码转换的,使用intset存储必须满足下面两个条件,否则使用hashtable,条件如下:
- 结合对象保存的所有元素都是整数值
- 集合对象保存的元素数量不超过512个
hashtable的数据结构应该在前面的hash的章节已经介绍过了,所以这里着重讲一下intset这个新的数据结构好了。
intset的数据结构
intset内部其实是一个数组(int8_t coentents[]数组),而且存储数据的时候是有序的,因为在查找数据的时候是通过二分查找来实现的。
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;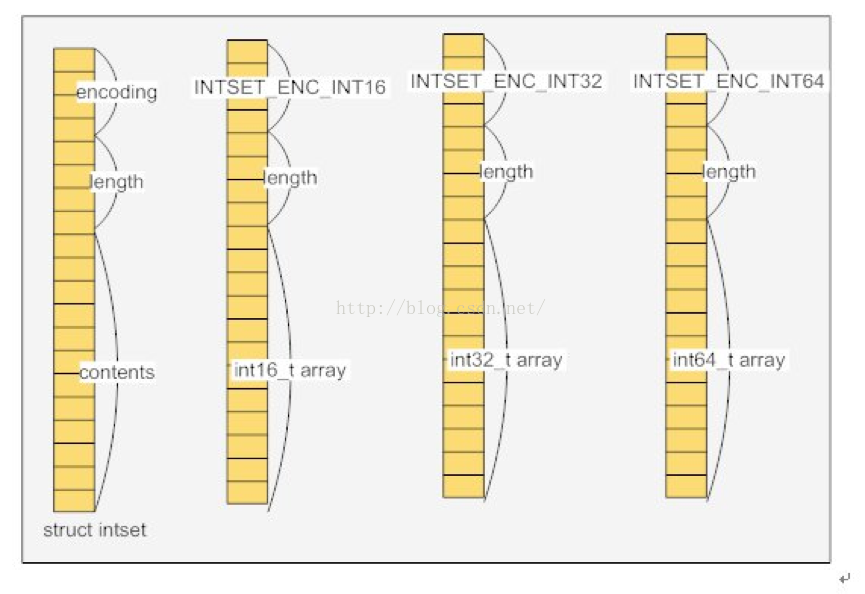
intset存储结构
redis set存储过程
以set的sadd命令为例子,整个添加过程如下:
- 检查set是否存在不存在则创建一个set结合。
- 根据传入的set集合一个个进行添加,添加的时候需要进行内存压缩。
- setTypeAdd执行set添加过程中会判断是否进行编码转换。
void saddCommand(redisClient *c) {
robj *set;
int j, added = 0;
// 取出集合对象
set = lookupKeyWrite(c->db,c->argv[1]);
// 对象不存在,创建一个新的,并将它关联到数据库
if (set == NULL) {
set = setTypeCreate(c->argv[2]);
dbAdd(c->db,c->argv[1],set);
// 对象存在,检查类型
} else {
if (set->type != REDIS_SET) {
addReply(c,shared.wrongtypeerr);
return;
}
}
// 将所有输入元素添加到集合中
for (j = 2; j < c->argc; j++) {
c->argv[j] = tryObjectEncoding(c->argv[j]);
// 只有元素未存在于集合时,才算一次成功添加
if (setTypeAdd(set,c->argv[j])) added++;
}
// 如果有至少一个元素被成功添加,那么执行以下程序
if (added) {
// 发送键修改信号
signalModifiedKey(c->db,c->argv[1]);
// 发送事件通知
notifyKeyspaceEvent(REDIS_NOTIFY_SET,"sadd",c->argv[1],c->db->id);
}
// 将数据库设为脏
server.dirty += added;
// 返回添加元素的数量
addReplyLongLong(c,added);
}
稍微深入分析一下set的单个元素的添加过程,首先如果已经是hashtable的编码,那么我们就走正常的hashtable的元素添加,如果原来是intset的情况,那么我们就需要进行如下判断:
- 如果能够转成int的对象(isObjectRepresentableAsLongLong),那么就用intset保存。
- 如果用intset保存的时候,如果长度超过512(REDIS_SET_MAX_INTSET_ENTRIES)就转为hashtable编码。
- 其他情况统一用hashtable进行存储。
/*
* 多态 add 操作
*
* 添加成功返回 1 ,如果元素已经存在,返回 0 。
*/
int setTypeAdd(robj *subject, robj *value) {
long long llval;
// 字典
if (subject->encoding == REDIS_ENCODING_HT) {
// 将 value 作为键, NULL 作为值,将元素添加到字典中
if (dictAdd(subject->ptr,value,NULL) == DICT_OK) {
incrRefCount(value);
return 1;
}
// intset
} else if (subject->encoding == REDIS_ENCODING_INTSET) {
// 如果对象的值可以编码为整数的话,那么将对象的值添加到 intset 中
if (isObjectRepresentableAsLongLong(value,&llval) == REDIS_OK) {
uint8_t success = 0;
subject->ptr = intsetAdd(subject->ptr,llval,&success);
if (success) {
// 添加成功
// 检查集合在添加新元素之后是否需要转换为字典
// #define REDIS_SET_MAX_INTSET_ENTRIES 512
if (intsetLen(subject->ptr) > server.set_max_intset_entries)
setTypeConvert(subject,REDIS_ENCODING_HT);
return 1;
}
// 如果对象的值不能编码为整数,那么将集合从 intset 编码转换为 HT 编码
// 然后再执行添加操作
} else {
setTypeConvert(subject,REDIS_ENCODING_HT);
redisAssertWithInfo(NULL,value,dictAdd(subject->ptr,value,NULL) == DICT_OK);
incrRefCount(value);
return 1;
}
// 未知编码
} else {
redisPanic("Unknown set encoding");
}
// 添加失败,元素已经存在
return 0;
}
作者:晴天哥_374
链接:https://www.jianshu.com/p/28138a5371d0
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。














 581
581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









