






《SQL-TOP(n)函数》
一、 说明
本文主要讲SQL数据库的TOP(n)函数的相关的内容。
该函数主要用于获取数据的最(大/小)值。
应用场景:查出员工中年龄最高的人是谁
二、 所用工具
SQL 数据库
三、 具体内容
1. 函数说明
TOP(n)函数返回指定的列中n个记录的值。
2. 语法
SELECT TOP n column_name FROM table_name ORDER BY column_name ASC;
语句解释:其中SELECT TOP、FROM、ORDER BY、ASC为关键字
ASC为排序的方式正序排序(从小到大)
改为DESC则为倒序排序(从大到小)
n为所要查询的数据的条数
column_name为要查询的列的名称
table_name为该列所在的表
第二个column_name为要作为排序依据的列(将当前列进行排序后得出的结果进行排序,然后再取n条数据进行显示)
3. 例子
查出员工中年龄最高的人是谁!
表结构:表名为EmployeeTable
表数据:
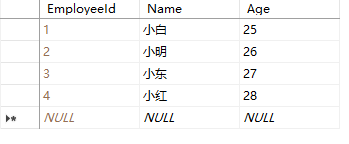
查询语句:
SELECT TOP(1)EmployeeTable.Name FROM EmployeeTable ORDER BY EmployeeTable.Age DESC
查询结果:
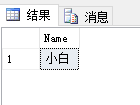
注意:排序依据的列必须是int或decimal等类似的类型,如果是其他的数据类型(如nchar类型)则无法得到正确的结果;如果有两个值同时为最值时:假如上面表数据在最后多了两条数据
Name值为“小爱”,Age值为“25”
Name值为“小西”,Age值为“28”后
如图:
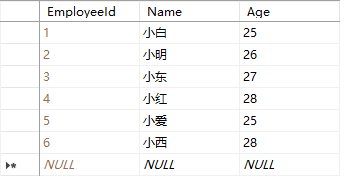
DEAC排序(从大到小排序)下所得的结果为原表中第一个出现的Age值为28的数据(即查询结果为“小红”)
ASC排序下(从小到大排序)下所得的结果为原表中第一个出现的Age值为25的数据(即查询结果为“小白”)














 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









