
【Python并行计算】- Dask 让你的python更快更强

Dask(https://docs.dask.org/en/latest/) 是一个灵活的python并行/分布式计算的框架。

类似的还有Ray/Modin, 从我的使用场景来看,我更喜欢Dask一些,特别是在SGE、SLURM等作业管理系统下的分布式计算,Dask 更加方便。
以下内容在Dask官网介绍的基础上加入了自己的理解。本文只是一个dask的简要介绍,希望帮助你在众多python并行框架中找到自己适合的。
Dask 有以下几个优点:
•Familiar(熟悉): 与 NumPy array and Pandas DataFrame 是兼容的,这些变量可以直接参与计算,所有函数几乎是无缝对接,极个别参数需要调整,上手很快;同时支持, Scikit-Learn, XGBoost等机器学习框架;支持for循环;•Flexible(灵活): 支持更多自定义的任务调度接口,比如Kubernetes/SGE/SLURM/Docker 等;•Native(原生): 通过访问PyData堆栈,在纯Python中启用分布式计算;•Fast(快): 以低开销、低延迟和快速数值算法所需的最小序列化进行操作;•Scales down(能屈): 在笔记本电脑上以单个进程设置和运行很简单;•Scales up(能伸): 在拥有1000个核心的集群上弹性运行;•Responsive(交互): 设计时考虑了交互式调试,它提供快速反馈和诊断,在程序运行时,实时显示节点的运行状况;•超内存使用,即便你的数据量大于机器的内存,Dask 通过数据分块也是可以解决的;

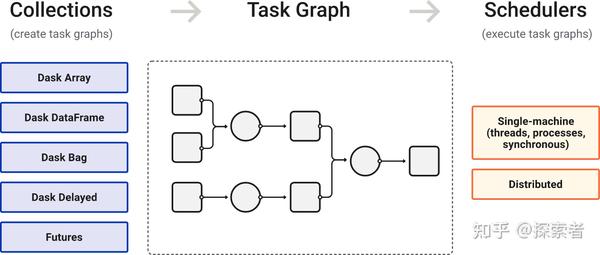
Dask 主要由两部分组成
•Dynamic task scheduling 动态任务调度,就是一个任务分发系统,类似的还有Airflow, Luigi, Celery, or Make;•“Big Data” collections 将python的数据类型list、numpy.array、pandas.dataframe 进行并行化处理,分成多个块,在不同线程、进程、节点上分发(task scheduling),即便你的数据占用内存大于机器的内存,也是可以解决的;

Dask 注意事项
•Lazy execution(延迟执行), Dask是延迟执行 ,就是你把所有的命令输入运行,无论数据量多大,dask都会立即显示运行完成,但实际上这些步骤dask并不是真正的计算,而只是一个可执行解析、分割数据、分配任务的过程,最后通过compute命令dask才会最终执行。所以需要你保证前面的数据结构没有错误,当然如果有简单的错误dask也是可以识别的。•常用的dask.dataframe 对象与pandas.dataframe 99%的相似性,但还是有些小的差异,后面我们的文章会做一期总结。
dask 实例
Dask DataFrame
几乎完全兼容pandas
import pandas as pd
df = pd.read_csv('2015-01-01.csv')
df.groupby(df.user_id).value.mean()
# dask
import dask.dataframe as dd
df = dd.read_csv('2015-*-*.csv')
# 或 df = dd.read_csv('2015-01-01.csv', blocksize=25e6) # 25MB chunk
# 或 df = dd.from_pandas(pd.read_csv('2015-01-01.csv') , npartitions=300)
df.groupby(df.user_id).value.mean().compute()
Dask-ML
支持 Scikit-Learn, XGBoost 等机器学习框架
import dask.array as da
from dask_ml.datasets import make_regression
from dask_ml.model_selection import train_test_split
X, y = make_regression(n_samples=125, n_features=4, random_state=0, chunks=50)Dask Array
模仿 numpy
import numpy as np
f = h5py.File('myfile.hdf5')
x = np.array(f['/small-data'])
x - x.mean(axis=1)
# dask
import dask.array as da
f = h5py.File('myfile.hdf5')
x = da.from_array(f['/big-data'],
chunks=(1000, 1000))
x - x.mean(axis=1).compute()
Dask Bag
模仿 iterators, Toolz, and PySpark
import dask.bag as db
b = db.read_text('2015-*-*.json.gz').map(json.loads)
b.pluck('name').frequencies().topk(10, lambda pair: pair[1]).compute()
Dask Delayed
支持for循环,支持全局变量
from dask import delayed
L = []
for fn in filenames: # Use for loops to build up computation
data = delayed(load)(fn) # Delay execution of function
L.append(delayed(process)(data)) # Build connections between variables
result = delayed(summarize)(L)
result.compute()Dask-Jobqueue
支持集群运算
from dask_jobqueue import PBSCluster
cluster = PBSCluster()
cluster.scale(jobs=10) # Deploy ten single-node jobs
from dask.distributed import Client
client = Client(cluster) # Connect this local process to remote workers
# wait for jobs to arrive, depending on the queue, this may take some time
import dask.array as da
x = ... # Dask commands now use these distributed resourcesdask-kubernetes
支持 kubernetes
from dask_kubernetes import KubeCluster, make_pod_spec
pod_spec = make_pod_spec(image='daskdev/dask:latest')
cluster = KubeCluster(pod_spec)
cluster.scale(10)Dask的目的是让简单的事情变得简单,让复杂的事情变得可能!
更多内容请关注公众号,我们持续更新