本文简要介绍 python 语言中 scipy.stats.tukey_hsd 的用法。
用法:
scipy.stats.tukey_hsd(*args)#执行 Tukey 的 HSD 测试以确保在多个治疗中均值相等。
Tukey 的诚实显著性差异 (HSD) 检验对一组样本的均值进行成对比较。 ANOVA(例如
f_oneway)评估每个样本的真实平均值是否相同,而 Tukey 的 HSD 是一种事后检验,用于将每个样本的平均值与其他样本的平均值进行比较。原假设是样本的分布均具有相同的均值。针对每个可能的样本配对计算的检验统计量只是样本均值之间的差异。对于每一对,p 值是在零假设(和其他假设;参见注释)下观察统计量的极值的概率,考虑到正在执行许多成对比较。还提供每对均值之间差异的置信区间。
- sample1, sample2, …: array_like
每组的样本测量值。必须至少有两个参数。
- result:
TukeyHSDResult实例 返回值是一个具有以下属性的对象:
- 统计 浮点数数组
每次比较的测试计算统计量。索引
(i, j)处的元素是组i和j之间比较的统计量。- p值 浮点数数组
每次比较的检验的计算 p 值。索引
(i, j)处的元素是组i和j之间比较的 p 值。
该对象具有以下方法:
- confidence_interval(confidence_level=0.95):
计算指定置信水平的置信区间。
- result:
参数 ::
返回 ::
注意:
该测试的使用依赖于几个假设。
观察在组内和组间是独立的。
每组内的观察值呈正态分布。
从中抽取样本的分布具有相同的有限方差。
测试的原始公式是针对相同大小的样本 [6]。在样本量不等的情况下,测试使用Tukey-Kramer 方法 [4]。
参考:
[1]NIST/SEMATECH e-Handbook of Statistical Methods, “7.4.7.1.图基的方法。”https://www.itl.nist.gov/div898/handbook/prc/section4/prc471.htm, 2020 年 11 月 28 日。
[2]Abdi、Herve & Williams、Lynne。 (2021 年)。 “Tukey 的诚实显著差异 (HSD) 测试。”https://personal.utdallas.edu/~herve/abdi-HSD2010-pretty.pdf
[3]“One-Way 使用 SAS PROC ANOVA 和 PROC GLM 的 ANOVA。” SAS 教程,2007 年,www.stattutorials.com/SAS/TUTORIAL-PROC-GLM.htm。
[4]克莱默,克莱德·杨。 “将多范围检验扩展到具有不相等复制数的组均值。”生物识别,第一卷。 12,没有。 3,1956 年,第 307-310 页。 JSTOR,www.jstor.org/stable/3001469。 2021 年 5 月 25 日访问。
[5]NIST/SEMATECH e-Handbook of Statistical Methods, “7.4.3.3. ANOVA 表和均值假设检验”https://www.itl.nist.gov/div898/handbook/prc/section4/prc433.htm, 2021 年 6 月 2 日。
[6]Tukey, John W. “在方差分析中比较个体均值”。生物识别,第一卷。 5,没有。 2,1949 年,第 99-114 页。 JSTOR,www.jstor.org/stable/3001913。于 2021 年 6 月 14 日访问。
例子:
以下是比较三种品牌的头痛药缓解时间的一些数据,以分钟为单位。数据改编自[3]。
>>> import numpy as np >>> from scipy.stats import tukey_hsd >>> group0 = [24.5, 23.5, 26.4, 27.1, 29.9] >>> group1 = [28.4, 34.2, 29.5, 32.2, 30.1] >>> group2 = [26.1, 28.3, 24.3, 26.2, 27.8]我们想看看任何组之间的方法是否有显著差异。首先,目视检查盒须图。
>>> import matplotlib.pyplot as plt >>> fig, ax = plt.subplots(1, 1) >>> ax.boxplot([group0, group1, group2]) >>> ax.set_xticklabels(["group0", "group1", "group2"]) >>> ax.set_ylabel("mean") >>> plt.show()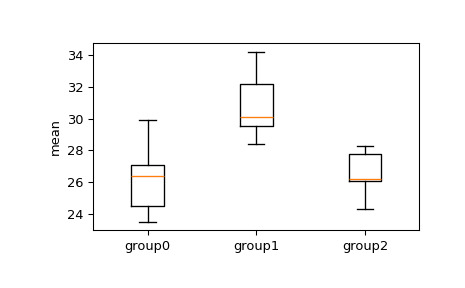
从箱线图中,我们可以看到四分位间距组 1 到组 2 和组 3 的重叠,但我们可以应用
tukey_hsd检验来确定均值之间的差异是否显著。我们设置了 0.05 的显著性水平来拒绝原假设。>>> res = tukey_hsd(group0, group1, group2) >>> print(res) Tukey's HSD Pairwise Group Comparisons (95.0% Confidence Interval) Comparison Statistic p-value Lower CI Upper CI (0 - 1) -4.600 0.014 -8.249 -0.951 (0 - 2) -0.260 0.980 -3.909 3.389 (1 - 0) 4.600 0.014 0.951 8.249 (1 - 2) 4.340 0.020 0.691 7.989 (2 - 0) 0.260 0.980 -3.389 3.909 (2 - 1) -4.340 0.020 -7.989 -0.691原假设是每组均值相同。
group0和group1以及group1和group2之间比较的 p 值不超过 0.05,因此我们拒绝它们具有相同均值的原假设。group0和group2之间的比较的 p 值超过 0.05,因此我们接受零假设,即它们的均值之间不存在显著差异。我们还可以计算与我们选择的置信水平相关的置信区间。
>>> group0 = [24.5, 23.5, 26.4, 27.1, 29.9] >>> group1 = [28.4, 34.2, 29.5, 32.2, 30.1] >>> group2 = [26.1, 28.3, 24.3, 26.2, 27.8] >>> result = tukey_hsd(group0, group1, group2) >>> conf = res.confidence_interval(confidence_level=.99) >>> for ((i, j), l) in np.ndenumerate(conf.low): ... # filter out self comparisons ... if i != j: ... h = conf.high[i,j] ... print(f"({i} - {j}) {l:>6.3f} {h:>6.3f}") (0 - 1) -9.480 0.280 (0 - 2) -5.140 4.620 (1 - 0) -0.280 9.480 (1 - 2) -0.540 9.220 (2 - 0) -4.620 5.140 (2 - 1) -9.220 0.540
相关用法
- Python SciPy stats.tukeylambda用法及代码示例
- Python SciPy stats.theilslopes用法及代码示例
- Python SciPy stats.triang用法及代码示例
- Python SciPy stats.t用法及代码示例
- Python SciPy stats.ttest_rel用法及代码示例
- Python SciPy stats.tvar用法及代码示例
- Python SciPy stats.trim_mean用法及代码示例
- Python SciPy stats.tsem用法及代码示例
- Python SciPy stats.ttest_ind_from_stats用法及代码示例
- Python SciPy stats.truncpareto用法及代码示例
- Python SciPy stats.ttest_1samp用法及代码示例
- Python SciPy stats.ttest_ind用法及代码示例
- Python SciPy stats.tmean用法及代码示例
- Python SciPy stats.truncweibull_min用法及代码示例
- Python SciPy stats.trim1用法及代码示例
- Python SciPy stats.tmin用法及代码示例
- Python SciPy stats.trimboth用法及代码示例
- Python SciPy stats.tmax用法及代码示例
- Python SciPy stats.truncexpon用法及代码示例
- Python SciPy stats.truncnorm用法及代码示例
- Python SciPy stats.trapezoid用法及代码示例
- Python SciPy stats.tstd用法及代码示例
- Python SciPy stats.tiecorrect用法及代码示例
- Python SciPy stats.anderson用法及代码示例
- Python SciPy stats.iqr用法及代码示例
注:本文由纯净天空筛选整理自scipy.org大神的英文原创作品 scipy.stats.tukey_hsd。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。