







我和这位哥简直一摸一样,来自https://zhuanlan.zhihu.com/p/142186760

在默认设置下,Pandas只使用单个CPU内核,对于稍大一些的数据,用Pandas来处理,通常会显得比较慢。
学习目标:
Dask、Vaex、Modin、Cupy、Ray、Mars、Cpython、swifter 、pandarallel 、Polars
额,笔记写得很杂,主要是给自己看
pandas 读取csv文件
import time
import pandas as pd
s = time.time()
df = pd.read_csv('train.csv')
e = time.time()
print("Pandas Loading Time = {}".format(e-s))
在读数据时候,可以指定列类型,减小内存占用
df = pd.read_csv('train.csv', nrows=1000,
dtype={
'x1': 'int32',
'x2': 'int16',
'x3': 'int16',
'x4': 'int16',
'x5': 'int16',
'x6': 'int8'
})
只读需要的列
df = pd.read_csv('train.csv', usecols=['x1', 'x3', 'x6'])
面对大量数据,也可以使用 read_csv 中的 chunksize 参数,分块读取来提高速度
利用chunksize参数,可以为指定的数据集创建分块读取IO流,每次最多读取设定的chunksize行数据,这样就可以把针对整个数据集的任务拆分为一个一个小任务最后再汇总结果:
def read_single_csv(input_path):
'''
读入数据
'''
import time
print("开始处理...")
start = time.time()
df_chunk=pd.read_csv(input_path,chunksize=1000000,encoding='utf-8')
res_chunk=[]
for chunk in df_chunk:
res_chunk.append(chunk)
res_df=pd.concat(res_chunk)
end = time.time()
shi = end - start
print("已完成!总耗时%s秒!" % shi)
print("*"*50)
print(res_df.shape)
return res_df
或者
读一百万行写入新的文件,可以用readline,一次读取一行,边读边写
with open('/path/to/input') as fi, open('/path/to/output/' as fo:
for i in xrange(1000000):
chunk_data = fi.readline()
if not chunk_data:
break
fo.write(content)
链接:https://www.zhihu.com/question/56153676/answer/147882741
查看内存函数
def memory():
import psutil
mem = psutil.virtual_memory()
zj = float(mem.total) / 1024 / 1024 / 1024
ysy = float(mem.used) / 1024 / 1024 / 1024
kx = float(mem.free) / 1024 / 1024 / 1024
print('Total system memory:%d.3GB' % zj)
print('The system has used memory:%d.3GB' % ysy)
print('System free memory:%d.3GB' % kx)
memory()
from tqdm.notebook import tqdm
# 在降低数据精度及筛选指定列的情况下,以1千万行为块大小
df = pd.read_csv('train.csv',
dtype={
'x1': 'int32',
'x3': 'int16',
'x6': 'int16'
},
usecols=['x1', 'x3', 'x6'],
chunksize=10000000)
# 从df中循环提取每个块并进行分组聚合,最后再汇总结果
result = pd.concat([chunk for chunk in tqdm(df)])
批量读取
边读边存
import csv
import pandas as pd
import numpy as np
data1 = pd.DataFrame()
for i in range(6):
print(f'The {i+1} file is executing')
try:
path = '/dev/shm/data_2021_{}.dat'.format(i)
da_li = []
with open(path,mode='rt',encoding='utf8' ) as f:
reader = csv.reader(f)
head_row = next(reader)
for item in reader:
da_li.append(item[0].split('€€'))
dat_1 = pd.DataFrame(np.array(da_li))
data1 = pd.concat([data1,dat_1],axis=0)
print('ok',data1.shape)
print(f'The {i+1} file save success')
print()
except Exception:
print(f'{i+1} file execution error')
dask
官网
https://docs.dask.org/en/latest/
Dask是一个并行计算库,能在集群中进行分布式计算,能以一种更方便简洁的方式处理大数据量,与Spark这些大数据处理框架相比较,Dask更轻。
调用时,dask具有延时加载技术,最后加上.compute(),dask才会基于前面搭建好的计算图进行正式的结果运算
即
.compute() 相当于激活计算图,加上 .compute() 才能达到真正的结果。
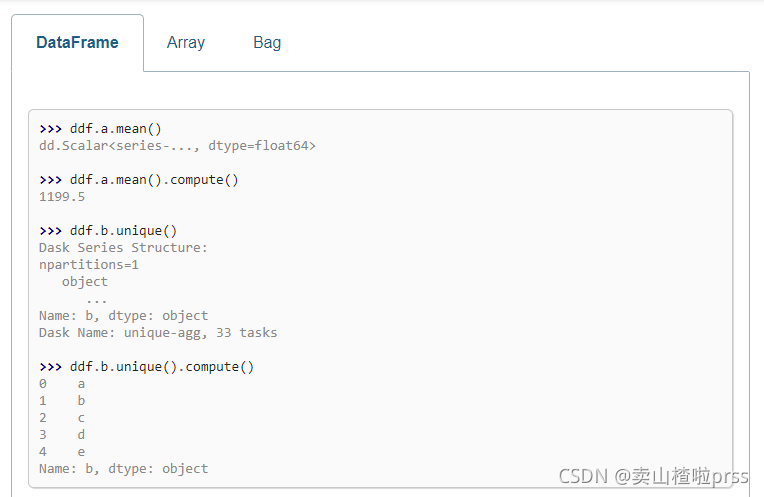
import dask.dataframe as dd
df = dd.read_csv('csv_files/*.csv')
df.head()
df.info(memory_usage='deep')
quantile = df.col1.quantile(0.1).compute() # Dask具有分位数功能,可以计算实际分位数,而不是近似值。
df['col1_binary'] = df.col1 > df.col1.quantile(0.1)
df = df[(df.col2 > 10)]
roup_res = df.groupby('col1_binary').col3.mean().compute()
monthly_total = df.groupby(df[‘Date’].dt.month).sum().compute()
plot = df.col3.compute().plot.hist(bins=64, ylim=(13900, 14400))
suma = df.sum().sum().compute()
df[df.col1.between(2, 4)]
df[df['col4'].str.contains('small|medium')]
import numpy
import dask
from dask import array as darray
arr = dask.from_array(numpy.array(my_data), chunks=(1000,))
mean = darray.mean()
stddev = darray.std(arr)
unnormalized_moment = darry.mean(arr * arr * arr)
dask 读取庞大的数据
import dask
import dask.dataframe as dd
from dask.diagnostics import ProgressBar
from numba import jit
import pandas as pd
import numpy as np
import sys
# ----------------------------------------------------------------------------
switchDict = {
0 : 'TEST',
1 : 'ALL'
}
# 编译数据量状态开关 0为测试(读部分数据),1为全量
status = switchDict[1]
@jit
def importData(fileName):
if status == 'TEST':
df = dd.read_csv(fileName, header=None, blocksize="100MB").head(17000)
else:
df = dd.read_csv(fileName, blocksize="64MB").compute()
df.index = pd.RangeIndex(start=0, stop=len(df))
return df
# 读正样本
with ProgressBar():
data = importData('train.csv')
print(f"当前数据框占用内存大小:{sys.getsizeof(data)/1024/1024:.2f}M")
data.shape
data.memory_usage(deep=True)
把数据读取出来以后,对内存进行优化,可以大幅提高数据处理效率
def reduce_mem_usage(df):
'''
内存优化 数据精度量化压缩
'''
# 处理前 数据集总内存计算
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
# 遍历特征列
for col in df.columns:
# 当前特征类型
col_type = df[col].dtype
# 处理 numeric 型数据
if col_type != object:
c_min = df[col].min() # 最小值
c_max = df[col].max() # 最大值
# int 型数据 精度转换
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
# float 型数据 精度转换
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
# 处理 object 型数据
else:
df[col] = df[col].astype('category') # object 转 category
# 处理后 数据集总内存计算
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
print('=========================================================')
print(df.info(verbose=True))
return df
参考:https://zhuanlan.zhihu.com/p/137292923
当读取批量数据时,可能会使用glob包,这个包将一次处理多个csv文件。可以使用data/*. CSV模式来获取data文件夹中的所有csv文件。
Pandas没有本地的glob支持,因此我们需要循环读取文件。
import glob
all_files = glob.glob('data/*.csv')
dfs = []
for fname in all_files:
dfs.append(pd.read_csv(fname, parse_dates=['Date']))
df = pd.concat(dfs, axis=0)
dfsum = df.groupby(df['Date'].dt.year).sum()
dask 可以通过将数据分成块并指定任务链来处理不适合内存的数据,并且 dask 接受read_csv()函数的glob模式,这意味着不必使用循环。在调用compute()函数之前,不会执行任何操作
import dask.dataframe as dd
df = dd.read_csv(‘data/*.csv’, parse_dates=[‘Date’])
dfsum = df.groupby(df[‘Date’].dt.year).sum().compute()
建议只对不适合主内存的数据集使用Dask。
modin
modin 的原理:将 DataFrame分割成不同的部分,而每个部分由发送给不同的CPU处理。modin 可以切割DataFrame的横列和纵列,任何形状的DataFrames都能平行处理。
modin 依赖 ray
modin 还是相对比较新的库,还在开发扩展中。所以并不是所有Pandas函数都能在modin 中得以实现。如果想用 modin 来运行一个尚未加速的函数,它还是会默认在Pandas中运行,来保证没有任何代码错误。
import ray
ray.init(num_cpus=4, ignore_reinit_error=True)
# 第一个参数充分利用4核CPU。
# 第二个参数 ignore_reinit_error=True, 忽略重复初始化的 而产生的报错。
import modin
import modin.pandas as mpd
s = time.time()
df = mpd.read_csv('train.csv')
e = time.time()
print("Modin Loading Time = {}".format(e-s))
Vaex
Vaex是一个开源的DataFrame库(类似于Pandas),对和你硬盘空间一样大小的表格数据集,它可以有效进行可视化、探索、分析甚至进行实践机器学习。
Vaex 采用内存映射、高效的核外算法和延迟计算等概念
Vaex要求将CSV转换为HDF5格式,才能看到Vaex的优点。
HDF5是一种全新的分层数据格式产品,由数据格式规范和支持库实现组成。
HDF5旨在解决较旧的HDF产品的一些限制,满足现代系统和应用需求。
HDF5文件以分层结构组织,其中包含两个主要结构:组和数据集。
HDF5 group:分组结构包含零个或多个组或数据集的实例,以及支持元数据(metadata)。
HDF5 dataset:数据元素的多维数组,以及支持元数据。
import glob
import vaex
# csv_files = glob.glob('csv_files/*.csv')
csv_files = glob.glob('train.csv')
for i, csv_file in enumerate(csv_files, 1):
for j, dv in enumerate(vaex.from_csv(csv_file, convert=True, chunk_size=5_000_000), 1):
print('Exporting %d %s to hdf5 part %d' % (i, csv_file, j))
dv.export_hdf5(f'hdf5_files/analysis_{i:02}_{j:02}.hdf5')
dv = vaex.open('hdf5_files/*.hdf5')
Vaex实际上并没有读取文件,因为延迟加载。
quantile = dv.percentile_approx('col1', 10)
Vaex具有虚拟列的概念,在添加新列时创建一个虚拟列,虚拟列的处理方式与普通列相同,但是它们不占用内存。Vaex只记得定义它们的表达式,而不预先计算值。这些列仅在必要时才被延迟计算,从而保持较低的内存使用率。
dv['col1_plus_col2'] = dv.col1 + dv.col2
dv['col1_binary'] = dv.col1> dv.percentile_approx('col1',10)
CuPy
CuPy 是一个借助 CUDA GPU 库在英伟达 GPU 上实现 Numpy 数组的库。
只要用兼容的 CuPy 代码替换 Numpy 代码,用户就可以实现 GPU 加速。
Swifter
import pandas as pd
import swifter
df.swifter.apply(lambda x: x.sum() - x.min())
Mars
基于张量的大规模数据计算的统一框架,即使在单块CPU的情况下,它的矩阵运算速度也比NumPy(MKL)快
pandarallel
Pandarallel 的想法是将pandas计算分布在计算机上所有可用的CPU上,以显着提高速度。
拐求
暂时不支持windows
https://zhuanlan.zhihu.com/p/65647604
Polars
Polars使用语法和Pandas差不多,处理数据的速度却比Pandas快了不少
安装
pip install -i https://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com polars
读取数据
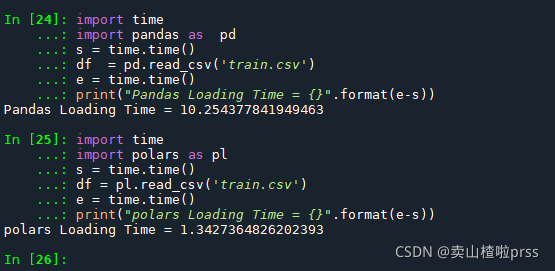
import time
import polars as pl
s = time.time()
df = pl.read_csv('train.csv')
e = time.time()
print("polars Loading Time = {}".format(e-s))














 146
146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









